Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

ゆうきまさみ開業30周年記念企画展に行ってきた - Dec 25, 2010
渋谷PARCO 1で開催されている原画展で、パトレイバーの原稿の展示が23日で終わるという事を22日になって知って、慌てて行ってきた。
単行本は実家に置いてきたんだけど、展示されてたイングラム対グリフォンの最終戦の原稿を見てると、最終戦を読んだ時の興奮が蘇ってきて涙目になりかけた。「機動警察パトレイバー」は本当に名作だと思う。未読の人はほんとに1回読んでみるといいです。
で、帰宅してその勢いで劇場版第1作を見た。ブルーレイだけど、5.1chじゃない方の音声を選ぶと(ステレオPCMで)サウンドリニューアル版でない当時の音声で楽しめるという事に、初めて気がついた。5.1chサラウンドの環境なんか持ってないから音声を選び直したんだけど、これは嬉しいサプライズだ。「呪ってやるー!!」は当時の演技の方が好きなのです。
ツリー型タブがCSSの!importantを使いすぎているせいで他のアドオンと衝突する(Tree Style Tab conflicts Tab Utilities, ColorfulTabs, and other tab-related addons because it uses too many "!important" rule in its CSS.) - Dec 18, 2010
- Q
With BOTH Tree Style Tab AND Tab Utilities enabled at the same time, the ColorfulTabs extension makes no difference - no tabs get colored. I have reported this to the author of Tab Utilities since it has worked properly in all previous versions of Tab Utilities. But here's his answer:
TU hacks the ColorfulTabs code to reduce its use of "!important", but Tree Style Tab still uses "!important" for tab background-color. I may revert TU's changes, but IMO it's Tree Style Tab who behaves improperly. It uses too many unnecessary "!important" modifiers in CSS rules, which also leads to the conflict with TU for the pinned tabs' position.
Can you fix this please?
ツリー型タブとTab Utilitiesが同時に有効になっている時、ColorfulTabsは何の変化ももたらしません──つまり、タブに色が付きません。Tab Utilitesの以前のバージョンは正しく動いていたため、私はこの件をTab Utilitiesの作者に連絡しました。しかし彼はこう言っています:
Tab Utilitiesは「!important」の使用を減らすようにColorfulTabsのコードに手を加えていますが、ツリー型タブはまだ多くの「!important」指定をタブの背景色に指定しています。私はTab Utilitiesに加えた変更を取り消すかもしれませんが、しかし私の考えでは、ツリー型タブのやり方の方が間違っています。ツリー型タブはあまりに多くの不必要な「!important」指定をCSSの中で使っており、これはTab Utilitiesの「ピン留めされたタブ」の配置を壊す原因にもなっています。
この件について修正してもらえませんか?
- A
Those "!important" are surely required, because appearance of tabs can be modified by third-parties' theme. For example, if a theme defines black background with white text, then partially applied styles from TST possibly make lighter background with white text -- yes, it is very hard to be read. To avoid these cases, I decided to use "!important" rules. Actually I got some "bug reports" like this. If I remove those "!important", I'll get similar bug reports again -- I'm very sorry but I don't want that.
Instead, I made an option for "highly compatibile for other addons". See the configuration dialog of TST, "Appearance" panel. There is an option "Default (Specified by the Theme)" in built-in themes. If you choose the option, TST doesn't apply any "!important" rule for tabs. I believe that the option makes TST compatible with Tab Utilities and ColorfulTabs.
それらの「!important」指定は必要な物なのです。タブの外観がサードパーティ製のテーマによって変更される事があるのがその理由です。例えば、あるテーマが背景色を黒に、文字色を白に設定していた時、ツリー型タブのスタイル指定が部分的に適用されてしまうと、明るい背景色と白い文字の組み合わせになってしまうことがあります──これはとても読みにくいですよね。こういったケースの発生を防ぐために、私は「!important」指定を使う事を決めました。実際、私はそういう「バグ報告」を受け取った事があります。もしこれらの「!important」指定を削除したら、私は再びそういった報告を受け取る事になるでしょう──申し訳ありませんが、私はそれを望んでいません。
その代わりに、私は「他のアドオンとの互換性を高く保つ」選択肢を設けました。ツリー型タブの設定ダイアログの「外観」パネルを参照してください。ここでタブバーの表示スタイルとして「なし(テーマ本来の表示スタイル)」を選択すると、ツリー型タブは「!important」指定が付いたスタイル指定を適用しなくなります。これを選択する事で、ツリー型タブとTab UtilitiesやColorfulTabsの衝突は回避できるものと私は考えています。
木村拓哉艦長代理の宇宙戦艦ヤマト - Dec 14, 2010
話題のSPACE BUTTLESHIP ヤマト、見てきましてん。感想。
- 木村拓哉は総理になっても弁護士になっても木村拓哉だなあ。
- 第3艦橋って……死亡フラグ……
- アナライザーかっこいいよアナライザー。
- 森雪さんはいつの間に木村さんと恋愛関係になったのでしょうか。
正直かなりなめてかかってた(最悪、実写デビルマンを想定してた)から、最初の戦闘で結構「おおっ!」と思った。コスモゼロにギミックが加わってたり、アナライザーがでっかくなってたり、森雪の役所が生活班長じゃなくなってたり、デスラーの設定が今時のSF風になってたりと、色々入ってたアレンジについては、僕はこれはこれでアリだと思えた(ガミラス星人が青塗りの日本人俳優だったらコメディですよね)。まあ、僕自身が原作にそれほど強い思い入れが無いからかもしれないけど。
重力どないなってんのん? とか、なんで放射線があった方が住みよい種族なのに放射能を除去できるん? とか、突っ込めそうな所はたくさんあるけど、まあ、堅い事言わないで頭空っぽにして気楽に楽しんだらいいと思います。
しかし主役のラブストーリー展開はあまりに唐突すぎるなーとは思った。真田さんの「本当の弟のように」も。世界観とか舞台設定の強引さ不自然さは「そういうもの」として僕は気にならないんだけど、人間関係のそういうのはすごく……気になる。時間が限られてるんだし、恋愛に振るのかそうでないのかスッパリ割り切ればよかったのになー。そこの所の不自然さがなければ、もっと手放しで褒められたんだけど。
XULに追加された「layer」属性には、XULと低レベルのレイヤの入り交じりっぷりが顕れていた - Dec 11, 2010
Firefox4 オワタ - alice0775のファイル置き場で既報だけど、Bug 588764 – Content area needs a grey border and shadow around itというバグのパッチでborderのためだけに新たにXULのボックスが追加された。
最初このパッチを見た時、僕は「なんじゃこりゃ」と思った。こんなもんレイアウト目的の空divと同じ発想じゃないか! 何やってんだ! こんなもんCSSのborderでやりゃいいじゃないか! と。(既にタブの中にもレイアウト調整用のボックスが入ってるけど、まあ、それはさておく。)
でも当該バグの最初の方についてるコメントや最初のバージョンのパッチでは、hbox#browser(ブラウズ領域のコンテナ要素)に対してCSSでborderを設定してるんだよね。それで分からなくなった。何でわざわざ、ボーダーのためだけにXUL要素を増やしたのか。そこには何か理由があるんじゃないのか? っていうかそもそも、この追加された要素に付いてるlayer="true"ってのは何なんだ?
と疑問に思ったので議論の流れを追ってみたら、Bug 590468 – Reduce size of chrome document layer due to status barという別のバグが参照されていた。layerという属性もこのバグのパッチで導入されたらしい。
そっちの議論を読んでみたところ、どうもこういうことらしかった。
- ブラウザウィンドウのXULの要素ツリーは、(部分的に省略して要点を残すと)
となっている。<vbox> <toolbox/> <hbox id="browser" style="background:transparent"> <browser/> <hbox> <hbox id="browser-bottombox/> </vbox>- この時、hbox#browserは透明だが、toolboxとhbox#browser-bottomboxは不透明なので、結果的に、その上位のvbox要素はウィンドウ全体を覆う大きさの描画領域を持つ事になる。
- browser(コンテンツ領域のインラインフレーム)の描画領域は、最上位のvboxの描画領域の上に載っかっている形になる。
- そのため、例えばツールバー上の1箇所に変更があった時であっても、最上位のvboxの描画領域全体が再描画されて、その上に載っかっているコンテンツ領域の描画領域も再描画される、という無駄な処理が沢山行われてしまう。
- それだけでなく、最上位のvboxの描画領域全体の情報を保持するために無駄にメモリを使う事になる。必要なのはtoolboxとhbox#browser-bottomboxの分のメモリだけで、hbox#browserの部分(完全に透明)のメモリは不要なのに。
- この無駄をなくしてパフォーマンスを改善するためには、描画領域の大きさをもっと賢く計算する必要がある。この例だったら、「最上位のvboxの大きさの描画領域」ではなく、本当に必要な「toolboxの大きさの描画領域」と「hbox#browser-bottomboxの大きさの描画領域」という2つの最小限の領域を求めるようにしないといけない。
- しかし、今それをやるには人的リソースが足りない。
- なので次善の策として、「このXUL要素には専用に描画領域を割り当ててくれ」ということをGeckoの低レベル(よりネイティブ寄り)の描画処理に伝える方法として、XULにlayerという属性を導入する。
layer="true"が指定されたXUL要素は、強制的に専用の描画領域を持つようになる。- hbox#browser-bottomboxが専用の描画領域を持つようになった事で、最上位のvboxのために必要な描画領域はtoolboxの大きさだけで済むようになった(hbox#browserの部分が透明なので、その部分は描画領域が確保されなくなる)。
- この変更によって、toolbox、コンテンツ領域、hbox#browser-bottomboxのそれぞれが、お互いに重なり合わない描画領域を形成するようになった。
- ひいては、描画周りのパフォーマンスが向上した。
最近はWebGLとかどんどんネイティブ寄りの所に突っ込んでいってパフォーマンス改善に注力してるようなので、こういう事もまあ必要なんだろう。Firefox 4リリースが近くて大規模な変更を入れられる余裕が無いから、インテリジェントな判断が必要な所について、インテリジェントな判断のためのロジックを実装する代わりに、人力でインテリジェントな判断をあらかじめ下しておこう、という苦肉の策のようだ。
そこで最初の話に戻るんだけど、単純にhbox#browserにCSSでborderを設定してしまうと、こういう事が起こってしまうという指摘がなされたようだ。
- hbox#browserのボックスが完全な透明ではなくなってしまう。
- よって、最上位のvboxの描画領域がtoolbox+hbox#browserの大きさに拡大されてしまう。
- すると、描画領域がコンテンツ領域と重なる状態に戻ってしまう。
- 描画周りのパフォーマンスが落ちてしまう。これじゃ元の木阿弥だ。
- なので、hbox#browserにCSSのborderを設定するのは諦める。
- 代わりに、hbox#browserの中・コンテンツ領域の前後にボーダーのためのボックスとしてvbox#browser-border-startとvbox#browser-border-endを追加して、さらにそれらを
layer="true"と指定する。- これで、toolboxとvbox#browser-border-startとvbox#browser-border-endとhbox#browser-bottomboxとコンテンツ領域のそれぞれが、重なり合わない描画領域を持つ状態になる。
- よって、描画周りのパフォーマンス低下は起こらない。
Alice0775さんが「やっつけ仕事」と評した事について、僕は最初は単に「空divのようなボックスの使い方」についてだけ言っていたのだと思ったんだけど、このような背景事情を知って、それではなくて「インテリジェントな判断をするためのロジックを組むという真っ当なやり方をせずに、人力で解決する」というアドホックな対応の事をこそ「やっつけ仕事」と評されていたのだと、やっと悟ったわけです。
という風にlayer="true"が導入された背景を調べた事によって、アドオン作者も「Firefoxのウィンドウ内にXUL要素を追加すると、場合によっては最上位のvboxの描画領域が広がる事でパフォーマンスが低下してしまう」ということを意識しておかないといけないのだなあ、ということが分かった。ああ、もう、実に厄介な話だなあ……
タブを検索する機能が欲しい / How to search tabs? - Dec 08, 2010
- Q
It would be nice if you could search the tabs.
タブを検索できるといいんですが……
- A
Tab Filter or Search Tabs will help you.
Tab FilterかSearch Tabsを使ってみるとよいでしょう。
タブをドメインごとにソートする機能が欲しい / Auto-sorting of tabs by domain (or other conditions). - Dec 08, 2010
- Q
Could you add the option to Tree Style Tab or Multiple Tab Handler, to keep tabs with same domain/host in alphabetical order. In other words auto grouping by domain or host.
ツリー型タブまたはマルチプルタブハンドラに対して、同じドメインまたは同じホストのタブをアルファベット順で表示させる、というオプションを付けてもらえませんか? 言い換えるとつまり、ドメイン名やホスト名によるタブのグルーピングということです。
- A
Group/Sort Tabs provides the feature, so try it please. However it doesn't work with my Tree Style Tab.
I have no plan to do it on the Tree Style Tab, because I believe that tree of tabs is a "visualized history of web browsing". In the concept, "tree of tabs" and "auto-sorting by domain" mix is like oil and water. (By the way Tab Kit provides both features, so it possibly become your favorite instead of TST.)
Group/Sort Tabsというアドオンがその機能を持っているので、試してみてください。しかし、このアドオンはツリー型タブとは併用できないようです。
私はタブのツリーを「ブラウズ履歴を視覚化した物」と考えていますので、ツリー型タブにこの機能を付ける予定はありません。このコンセプトにおいて「タブのツリー」と「ドメインによる自動的な並べ替え」は相性が悪いです。(ちなみにTab Kitはその両方の機能を提供します。ツリー型タブよりもそちらの方があなたにとって気に入るかもしれません。)
複数のアドオンを一気にインストールする(ような形で配布する)方法 - Dec 06, 2010
多機能オールインワン型のタブ系アドオンをdisったら、こんな反応があった。
ただエンドユーザーからみると、タブ機能のために細かい拡張をいくつも入れてられるか、とも思っちゃうのよね。
そんな時のためにFirefoxには複数のアドオンを一発でインストールできる仕組み(ユーザ側で工夫したら複数のアドオンを一括インストールできる、のではなくて、アドオンを公開する側がユーザに「このリンクを辿ればこれらのアドオンを全部インストールできます」的なインターフェースを提供できる)が備わっているのですよ!! 全然活用されてないけど!!!!!
やり方は2つある。
- マルチプルアイテムパッケージという特殊なXPIを配布する方法
- InstallTriggerを使う方法
ツリー型タブ、マルチプルタブハンドラ、情報化タブ、ソース表示タブ、ブックマークを新しいタブで開く、リンクを新しいタブで開く、ロケーションバーから新しいタブを開くの7つを一括インストールさせたい場合を例に説明しよう。
マルチプルアイテムパッケージで複数のアドオンをまとめて配布する
これはtabextensions3や学生向けアドオンパックが実際に使ってる方法だ。
やり方
まず、こういうinstall.rdfを作る。em:type="32"というのがミソ。
<?xml version="1.0" encoding="UTF-8"?>
<RDF:RDF xmlns:em="http://www.mozilla.org/2004/em-rdf#"
xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<RDF:Description RDF:about="urn:mozilla:install-manifest"
em:id="tabextensions3@piro.sakura.ne.jp"
em:type="32">
<em:targetApplication>
<RDF:Description em:id="{ec8030f7-c20a-464f-9b0e-13a3a9e97384}"
em:minVersion="3.6"
em:maxVersion="4.0b2pre" />
</em:targetApplication>
</RDF:Description>
</RDF:RDF>
このinstall.rdfと、7つのアドオンのXPIをまとめてZIP圧縮して、ファイル名を「〜.xpi」に変えれば完成。
この時、install.rdfに書く対象アプリケーションのem:minVersionとem:maxVersionは、全部のアドオンの最大公約数的な値になるようにしないといけない。
例えばminVersionが3.5の物と3.6の物、maxVersionが4.0b2preと4.0b8preの物があるんだったら、「全部揃った状態で確実に動くのは3.6〜4.0b2preの間」ということでそのように指定する。
この方法の詳しい話はMDCにドキュメントがある。
メリットとデメリット
この方法には、配布するファイルが1個だけでよくなるし、JavaScriptとかを使う必要がないというメリットがある。
その反面、同梱するアドオンを増やしたり減らしたり更新したりしたい時には、パッケージをその都度作り直さないといけないというデメリットがある。
InstallTriggerで複数のアドオンをまとめてインストールする
これは台湾のMozillaコミュニティのプロモーション用サイトで実際に使われてる方法だ。
やり方
こんな感じのスクリプトを実行するだけ。
var targets = {
treestyletab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/treestyletab.xpi?update'
},
multipletab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/multipletab.xpi?update'
},
informationaltab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/informationaltab.xpi?update'
},
viewsourceintab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/viewsourceintab.xpi?update'
},
openbookmarkintab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/openbookmarkintab.xpi?update'
},
openlinkintab : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/openlinkintab.xpi?update'
},
newtabfromlocationbar : {
URL : 'http://piro.sakura.ne.jp/xul/xpi/openlinkintab.xpi?update'
}
};
InstallTrigger.install(targets);InstallTrigger.install()にはインストールさせたいアドオンのリストをハッシュとして渡す。
ハッシュ値を渡して安全なインストールを可能にするとかの工夫もできる。これも詳しい話はMDCに書いてある。
メリットとデメリット
この方法には、いちいちパッケージを作らなくていいというメリットがある。台湾コミュニティのサイトのように、「ユーザがリストにチェックを入れていって、最後にボタンを押したらチェックが入ってるアドオンだけを一括インストールする」という風な事が簡単にできる。
その代わり、配布するファイルがバラバラになるし、JavaScriptが有効になってないと利用できないというデメリットがある。
なんでAMOでこれを使わないんでしょうね?
AMOにコレクションという機能が加わった時、これを使って「お薦めのアドオンを一括インストールできますよ!」という見せ方ができるようになるものとばかり思ってた。そういうものが絶対に必要だろ、と思ってたから、すごく期待してた。でも実際に出てきた機能はただの「リンク集作成機能」でしかなかったのですごくガッカリした。
せっかくこういう機能があるのに、それを使わないでTab Mix Plusを「お薦めアドオン」として前面に押し出してたりするんですよ。何考えてるんですかねホント。
乱立する「多機能型のタブ系アドオン」を苦々しく思う - Dec 03, 2010
ちょっと前に、Tab Utilities Mini、というのが出てきたらしいですね。
改めて、今現在それ系のアドオンがどれだけあるのかリストアップしてみて、乾いた笑いしか出てこなかった。
- Tab Mix Plus
- Tab Mix Lite
- Tab Mix Lite CE
- Tab Utilities
- Tab Utilities Lite
- Tab Utilities Mini:NEW!!
- Tab Kit
- Tabberwocky
- Super Tab Mode
- Tab Control
PlusにLiteにCEにMiniに……それはギャグで言っているのか? タブ統合型アドオンの比較表みたいな物がないと見分けつかないよ。既にこれだけあるのにまだ同じ事をやるんだ、っていう事に呆れる。
しかも、よく見たらTab UtilitiesとTab Utilities MiniとTab Utilities Liteって作者同じじゃないすか。ますます意味が分からない。
/ || ̄ ̄|| ∧_∧ |.....||__|| ( ) どうしてこうなった・・・ | ̄ ̄\三⊂/ ̄ ̄ ̄/ | | ( ./ / ___ / || ̄ ̄|| ∧_∧ |.....||__|| ( ^ω^ ) どうしてこうなった!? | ̄ ̄\三⊂/ ̄ ̄ ̄/ | | ( ./ / ___ ♪ ∧__,∧.∩ / || ̄ ̄|| r( ^ω^ )ノ どうしてこうなった! |.....||__|| └‐、 レ´`ヽ どうしてこうなった! | ̄ ̄\三 / ̄ ̄ ̄/ノ´` ♪ | | ( ./ / ___ ♪ ∩∧__,∧ / || ̄ ̄|| _ ヽ( ^ω^ )7 どうしてこうなった! |.....||__|| /`ヽJ ,‐┘ どうしてこうなった! | ̄ ̄\三 / ̄ ̄ ̄/ ´`ヽ、_ ノ | | ( ./ / `) ) ♪
すげー悪く言うけどさ、ほんとすげー悪く言うけどさ、今日はセンスタソになっちゃうけどさ、タブブラウザ拡張(Tabbrowser Extensions、TBE)を作ってた僕自身も含めて、こういう事やる人ってほんっとセンスないよね。
日本のメーカーがiPhoneを作るとこうなるって話なんかもそうだけど、センスが無い人は「カタログスペック上の数値が高い物」「カタログ上の機能が多い物」という観点からしか「良さ」をアピールできないんだよね。まあ、そんなセンス無しでもiPhoneを触ったら「キモチイイ!!!」って感覚は多分抱くんだよね。ただ、残念な事に、その感想が脳内のフィルタをいくつも通ってその人の口から出力される時には、どーいうわけか「あれもできる、これもできる、だから素晴らしい」的なくっだらない表現に「翻訳」されちゃうわけですよ。
同じ事が、そういう人が物を作る時にも起こるわけですよ。物を作る以上、そりゃあ、自分で「こりゃ駄目だ」って思うものよりは「これは良い物だ」って思える物を作りたくなる。でもセンスがないから、どう作れば「良い物」になるかがわかんない。しょうがないから、自分が「良い」って思った事があるものを切り貼りして集めてくるしかないワケですよ。そういう風にセンスの無い人間が、下手に決定権を持っちゃったり実行力を持っちゃったりするから、こういう物が世の中に出てきてしまうんだ。
で、こういうアドオンってほんと罪作りだと思うんだ。
カタログスペックだけはやたら高いから、よく分かってない人は「多分良い物なんだろう、カタログスペックはいいみたいだから」って同じ発想で飛びついちゃうんだよきっと。「それらの機能が本当に自分を幸せにしてくれるのかどうか」なんて分からないままに。
それで機能の8割くらいが結局使われなかったとしても、まあ、ユーザが満足してるならそれでいいじゃんっていう考え方はある。メモリだのなんだのの面で無駄が大きくても、そんなの関係ない。「無駄がないけど目的は達成されない」のと「無駄はあるけど目的は達成される」のとだったら、後者は前者に対して圧倒的に正しい。
でもさあ。「無駄がある」だけじゃなく「囲い込まれてしまう」っていう事まで加わってしまったら、それはさすがにあかんやろって思うんですよ。なんで多機能オールインワン型のアドオンが囲い込みになってしまうのかという話は過去にも詳しく書いたから、そっちを読んで欲しいんだけど。囲い込みたくて囲い込んでるんじゃなくて、囲い込もうというつもりはなかったのに結果的に囲い込みになってしまう、囲い込んだ後にちゃんと維持し続けていけるだけのキャパシティもないのにそういう状況を作り出してしまう、それが良くない。囲い込みって、やる方にも体力がいるんだよ。あらゆる物を自前で用意しなきゃいけない。そんなの個人で趣味でやれるような事じゃない。それでは作り手も使い手もみんな不幸になってしまうよ。
僕はFirefox 1.5までのバージョンにしか対応できていなかったTBEに自分自身が激しくロックインされてしまって、Firefox 2にいつまで経ってもアップグレードできなかった。そんな馬鹿みたいな事に他人まで巻き込んだらあかんよ……
(ツリー型タブから「ロケーションバーから新しいタブを開く」「リンクを新しいタブで開く」を分離することにしたきっかけがこの出来事だったので、それについて書こうと思って色々思い返したり調べ直したりしてたんだけど、結局こういう話に落ち着いた。)
ツリー型タブとマルチプルタブハンドラとHTML5のドラッグ&ドロップ - Dec 02, 2010
Tree Style TabとMultiple Tab Handlerのドラッグ&ドロップ周りのコードを色々書き直した。
Tab Utilitiesとの衝突
発端は、「Tab Utilitiesと一緒に使うとタブのドラッグ&ドロップが期待通りに動かない」という報告だった。しかし、「また衝突かよー」と思いながらメールの内容を読むと、想像していたのとはちょっと状況が違った。
僕はてっきり、Tab Utilitiesのイベント処理とツリー型タブのイベント処理がかちあって変な事になってるんだとばかり思ってたんだけど、そうではなくて、Tab Utilitiesが提供する「複数のタブを選択してまとめてドラッグ&ドロップする」機能で複数のタブを1つのタブの上にドロップしても、選択されていたタブのうち1つしかドロップ先のタブの子タブにならない、という状況だった。その人はすでにTab Utilitiesの作者にも問い合わせていたようで、Tab Utilitiesの作者の回答に「ツリー型タブにマルチプルタブハンドラのためのコードしか含まれていないのがそもそもの問題だ。ツリー型タブの方で修正してもらってくれ。」みたいなコメントがあったそうだ。
それでTab Utilitiesを見てみたら、確かに複数のタブを選択する機能があったんだけど、その時のタブの情報の受け渡しにHTML5のドラッグ&ドロップのイベントの複数のデータの指定の仕組みが使われているようだった。
- マルチプルタブハンドラを最初に作ったときはまだこんなAPIは無かった。
- タブのドラッグ&ドロップの実装になるべく介入したくなかった。タブがドロップされた時に、そのタブが選択状態だったら、他の選択されているタブも一緒にドラッグされることが意図されていたと判断して、後から他のタブも追従して移動させる、という設計にしていた。
という事情があって、マルチプルタブハンドラではドラッグ操作のイベントそのものには介入しないようにしてたんだけど、Tab Utilitiesがそういう事をやってるんだったら、「複数タブのドラッグ操作」に特化したアドオンであるマルチプルタブハンドラが黙って見てるわけにはいかない。なので、マルチプルタブハンドラではバージョン0.6から、ついでにツリー型タブもバージョン0.11.2010120101から、タブをドラッグ&ドロップするときはドラッグしようとしているすべてのタブをデータトランスファーに渡すようにした。ついでにドラッグフィードバックイメージも自前で生成するようにして、複数タブのドラッグ時はドラッグ中のすべてのタブのサムネイルを重ねて表示するようにしてみた。
それで「ああやっと時代に追いつけたわ」と安心してたんだけど、Windowsでテストしてみたら、せっかく生成したドラッグフィードバックイメージがぜんぜん表示されないんでやんの。どうも、Windows版のFirefox 3.6以前は、mozSetDataAt()で複数のデータを指定するとドラッグフィードバックイメージが表示されないというバグがあるようだ。Ubuntu上のFirefox 3.6や、Windows上でもMinefieldでは問題なかったんだけど。頑張りの報われなさに切なくなった。
ツリー型タブのリファクタリング
ツリー型タブの場合は、タブのドラッグ&ドロップでツリーを編集する場合があるから、マルチプルタブハンドラみたいにTabMoveイベントをトリガーとして後から必要な処理を行うということはできなかった。なので、Firefox自身のドラッグ&ドロップの処理に介入する形の設計にせざるを得なかった。
その後HTML5のドラッグ&ドロップのAPIが実装されて、Firefox 3.5ではFirefoxのタブのドラッグ&ドロップのためのコード自体もそれをベースに書き直された。これはまだFirefox 3.0と同じようなやり方でドラッグ&ドロップの処理に介入できる余地があった。
しかしFirefox 4ではタブのドロップとかドラッグオーバーとかの処理がXBLのイベントハンドラの中にベタ書きされるようになってしまって、メソッドの中に処理を注入するやり方ではドラッグ&ドロップの操作に介入できなくなってしまった。なので、仕方ないからdragstartとかdropとかのイベントにキャプチャリングフェーズで割り込んでツリー型タブの側で全部自分で処理するようにした。
という経緯があって、結果的にツリー型タブのドラッグ&ドロップ周りの処理はFirefox 3.0向けとFirefox 3.5~3.6向けとFirefox 4向けとで3種類の方法が同居してかなりシッチャカメッチャカな状態になっていた。あとタブバー自体のドラッグ&ドロップの処理もあって、それぞれがあちこちに散らばっててだいぶ訳のわからんことになってた。
そんな状態だったから、昨日のリリースでは案の定リグレッションしてドラッグ&ドロップが盛大にぶっ壊れてた。これはもう駄目かもわからんねと思ったので、Firefox 3.0向けのコードを全廃したついでにFirefox 3.5~3.6に対してもFirefox 4向けのやり方を使うようにして、ドラッグ&ドロップのコードを専用のクラスに集めて整理することにした。
安定性とメンテナンス性を取った結果、タブのドラッグ&ドロップのイベント処理はFirefox本体のものを完全に無視する形になっているので、他のアドオンとの機能の両立という点では残念なことになっているかもしれない。タブのドラッグ&ドロップに介入するためのきちんとしたAPIが整理されていれば、こんな思いをしなくて済むのになあ。
ツリー型タブ 0.11.2010112601で機能を足したり引いたりした - Nov 26, 2010
今まではTree Style Tabでタブバーを横置き(上または下にタブバーを配置するモード)にした時特有の機能というのは特に設けていなかった、というか横置きで階層化されたグループ化なんて全然使いにくいし誰も使わないだろと思って割となおざりにしてたら、案外使われてるみたいで時々このモード特有のバグ報告を貰ってたわけですが、Opera 11でタブスタッキングとかいう機能が加わるとかで「そんなんXULでもできるわい!!! つうかもっと前からやっとるわい!!!」とカッとなって、タブが重なってるっぽく表示するようにしてみた。
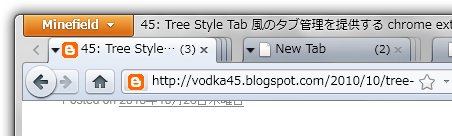
種を明かしてしまうと、元々「折り畳まれたタブ」はvisibility: collapseで見えないようにしてたのを、collapseにせずにvisibleのままで親のタブの下にz-indexを調整して重ねるようにしたというだけ。諸々の事情でMinefieldでしかこの表示にはならないようになってる(Firefox 3.6だと今まで通り)。
このようにしたおかげで、
- ツリーの折り畳み状態(子タブがあるかどうか)について、今までは見分ける術がタブのラベルに表示される「(3)」のような文字列と小さなtwistyだけだったので、縦置きタブバーではすぐ分かるけど横置きタブバーだと識別が困難だった。しかし今回の変更によって、タブの外形の変化で状態を簡単に識別できるようになった。
- 折り畳まれた状態のタブをクリックできるようになった(元々、背後にあるタブにフォーカスが来ても大丈夫なように設計していたので、そのための変更というのは特にはしていない)。
というメリットを図らずも得られてしまった。
しかしIDEA*IDEAの記事の小さいスクリーンショットと動画だけ見てこういう表示にしたんだけど、もっと大きなスクリーンショットだと、実際は全然違う形だった。まあ、今更だからこのままいくけどさ……
あと、このリリースから「リンクをクリックした時にそれを自動的にタブで開く」系の機能と「ロケーションバーからの入力で常にタブを開く」系の機能を別のアドオンに分割することにした。
既にあったOpen Bookmarks in New Tabと並べて「新しくタブを開く系3兄弟」的な。
- ちょっと探してみた限り、ほんとにこの機能だけを提供してくれるというアドオンを見つけられなくて、こういうものはTab Mix Plusとかの統合型のタブ拡張の一機能としてしか提供されていないようだった。
- 統合型のタブ拡張はどれもこれもこの機能を持ってるせいでツリー型タブと衝突してそうだった。
- これらの機能があるせいで、ツリー型タブは便利機能全部入りの統合型のタブ拡張を指向してると思われて、あれが欲しいこれが欲しいという機能追加の要望を受けてしまっていたのではないか? 僕はツリー型タブをそういう物として作りたくはない。
といった理由があっての決定です。多機能なのがいい人はツリー型タブを捨ててTab Kitあたりに乗り換えるといいと思います。