Technical Notes of Web Map 技術的な情報
履歴データの再利用のための指針
Web Mapは履歴データを一般的なRDFデータソースとして保持しています。構造を把握していれば、自作のアプリケーションや拡張から利用することもできます。
また、履歴データを取得・蓄積する処理の部分(バックエンド)とユーザーインターフェースであるマップ表示部分(フロントエンド)は分割して開発していますので、Web Mapの履歴データを走査するためのサービスとして、バックエンド部分のみを利用することも可能です。
履歴データの構造
RDFデータソースのファイル配置
Web Mapは、ページのURLやタイトル、最終訪問時刻などの情報を、ドメインごとに別々のファイルで管理しています(隠し設定を変更することで、単一のファイルにまとめることもできます)。
データフォルダ(デフォルトではユーザープロファイル内の「webmap」フォルダ)内において、ファイルは以下のように配置されます。
- [webmap]
- webmap.rdf
- [data]
- [piro.sakura.ne.jp]
- piro.sakura.ne.jp.rdf
- favicon.ico
- tn******.jpg
- tn******.jpg
- ...
- [www.osakac.ac.jp]
- www.osakac.ac.jp.rdf
- [www.google.co.jp]
- www.google.co.jp.rdf
- favicon.ico
- tn******.jpg
- tn******.jpg
- ...
- ...
- [piro.sakura.ne.jp]
起点ノードの情報
Web Mapはノード間のリンク情報を辿って履歴データ全体にアクセスしますが、その出発点となるノード(ブックマークから開かれたり、URIを直接入力して開かれたりした、リンク元が無いノード)について、特別に情報を保持しています。データフォルダ直下にある webmap.rdf がそれです。
このデータソースは、URIが https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:root のシーケンシャルなコンテナを一つだけ含んでいます。このコンテナには https://piro.sakura.ne.jp/ などのURIのリソースが要素として格納されます。
<?xml version="1.0"?>
<RDF:RDF xmlns:NC="http://home.netscape.com/NC-rdf#"
xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:root">
<RDF:li RDF:resource="https://piro.sakura.ne.jp/"/>
<RDF:li RDF:resource="http://www.osakac.ac.jp/"/>
<RDF:li RDF:resource="http://www.google.co.jp/"/>
</RDF:Seq>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:root"
WMNS:EntriesCount="22">
<WMNS:FirstEntry RDF:resource="https://piro.sakura.ne.jp/xul/xul.html"/>
<WMNS:LastEntry RDF:resource="https://piro.sakura.ne.jp/latest/"/>
</RDF:Description>
</RDF:RDF>また、同じURIのリソースにも、履歴としていくつかの情報を保持しています。
https://piro.sakura.ne.jp/rdf/webmap#EntriesCount には、リテラルとしてノードの総数を保持しています。 https://piro.sakura.ne.jp/rdf/webmap#FirstEntry には履歴として見た時の「最初の/最も古い/訪問回数の最も少ない」ノードが、 https://piro.sakura.ne.jp/rdf/webmap#LastEntry 「最後の/最も新しい/訪問回数の最も多い」ノードがリソースとして関連付けられています。
なお、隠し設定で全てのデータを一つのデータソースに保存するように設定している場合は、以下の記述するデータの全てが、このデータソースに保存されます。
各ドメインのデータソースの内容
各ドメイン用のデータソースは、「ドメインに含まれるノードのリスト」「各ノードの情報」「このドメインのノードを始点とするアークの情報」を含んでいます。以下は凡例です。
<?xml version="1.0"?>
<RDF:RDF xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:NC="http://home.netscape.com/NC-rdf#"
xmlns:NCWB="http://home.netscape.com/WEB-rdf#"
xmlns:WMNS="https://piro.sakura.ne.jp/rdf/webmap#">
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:nodes:
[ドメイン名をURIエンコードした文字列]">
<RDF:li>
<RDF:Description RDF:about="[URI]"
NC:URL="[URI]"
NC:Name="[タイトル]"
NCWB:LastVisitDate="[最終訪問時刻]"
NCWB:LastModifiedDate="[最終更新時刻]"
WMNS:VisitedCount="[訪問回数]">
<NC:Icon>
<RDF:Description RDF:about="[faviconのURI]">
<WMNS:ImageData RDF:resource="[キャッシュファイルのURL]"/>
<WMNS:Page RDF:resource="[このfaviconを参照しているページのURI]"/>
...
</RDF:Description>
</NC:Icon>
...
<WMNS:AvailableIcon RDF:about="[実際に利用可能なfaviconのURI]" />
<WMNS:Thumbnail RDF:about="[サムネイルのファイルのURI]" />
<WMNS:OlderEntry RDF:about="[前のエントリのURI]" />
<WMNS:LaterEntry RDF:about="[次のエントリのURI]" />
<WMNS:Arcs>
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arcs:
[このページのURIをURIエンコードした文字列]">
<RDF:li>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arc:
[遷移元のURIをURIエンコードした文字列]:
[遷移先のURIをURIエンコードした文字列]"
NCWB:ForeignDomain="[別ドメインへのアークか否か]"
NCWB:LastVisitDate="[最終訪問時刻]"
WMNS:VisitedCount="[訪問回数]">
<WMNS:ArcType RDF:resource="[アークの種別]"/>
<WMNS:From RDF:resource="[遷移元URI]"/>
<WMNS:To RDF:resource="[遷移先URI]"/>
</RDF:Description>
</RDF:li>
...
</RDF:Seq>
</WMNS:Arcs>
</RDF:Description>
</RDF:li>
...
</RDF:Seq>
</RDF:RDF>※データソースの読み書きはXPCOMの機能を使って行っていますので、実際にはもっととっ散らかっています。ここでは、説明を簡単にするために入れ子を使って表現し直しています。
具体例として、このサイトのトップページの場合を用いて解説します。
<?xml version="1.0"?>
<RDF:RDF xmlns:RDF="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:NC="http://home.netscape.com/NC-rdf#"
xmlns:NCWB="http://home.netscape.com/WEB-rdf#"
xmlns:WMNS="https://piro.sakura.ne.jp/rdf/webmap#">
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:nodes:
piro.sakura.ne.jp">
<RDF:li>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/"
NC:URL="https://piro.sakura.ne.jp/"
NC:Name="outsider reflex"
NCWB:LastVisitDate="1101020524125"
NCWB:LastModifiedDate="1101020523000"
WMNS:VisitedCount="2">
<NC:Icon>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/common/favicon.png">
<WMNS:ImageData RDF:resource="file://..."/>
<WMNS:Page RDF:resource="https://piro.sakura.ne.jp/"/>
...
</RDF:Description>
</NC:Icon>
<NC:Icon>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/common/favicon.ico"
WMNS:ImageData="data:">
<WMNS:Page RDF:resource="https://piro.sakura.ne.jp/"/>
...
</RDF:Description>
</NC:Icon>
<WMNS:AvailableIcon RDF:about="https://piro.sakura.ne.jp/common/favicon.png" />
<WMNS:Thumbnail RDF:about="file://.../piro.sakura.ne.jp/tn123456.jpg" />
<WMNS:OlderEntry RDF:about="https://piro.sakura.ne.jp/xul/xul.html" />
<WMNS:LaterEntry RDF:about="https://piro.sakura.ne.jp/latest/" />
<WMNS:Arcs>
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arcs:
http%3A%2F%2Fpiro.sakura.ne.jp%2F">
<RDF:li>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arc:
http%3A%2F%2Fpiro.sakura.ne.jp%2F:
http%3A%2F%2Fpiro.sakura.ne.jp%2Flatest%2F"
NCWB:ForeignDomain="false"
NCWB:LastVisitDate="1101020527843"
WMNS:VisitedCount="1">
<WMNS:ArcType RDF:resource="https://piro.sakura.ne.jp/rdf/webmap#Link"/>
<WMNS:From RDF:resource="https://piro.sakura.ne.jp/"/>
<WMNS:To RDF:resource="https://piro.sakura.ne.jp/latest/"/>
</RDF:Description>
</RDF:li>
...
</RDF:Seq>
</WMNS:Arcs>
</RDF:Description>
</RDF:li>
...
</RDF:Seq>
</RDF:RDF>ルートノード
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:nodes:
piro.sakura.ne.jp">
...
</RDF:Seq>そのドメインに属する全てのノードは、シーケンシャルなコンテナであるルートノードに格納されています。URIの末尾にはドメイン名をURIエンコードした文字列が付与されます。(JavaScriptであれば、encodeURIComponent()で変換した文字列です)
ノードの基本情報
<RDF:li>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/"
NC:URL="https://piro.sakura.ne.jp/" ←URI文字列
NC:Name="outsider reflex" ←ページ名
NCWB:LastVisitDate="1101020524125" ←最終訪問時刻
NCWB:LastModifiedDate="1101020523000" ←最終更新時刻
WMNS:VisitedCount="2"> ←訪問回数
...
</RDF:Description>
</RDF:li>最終訪問時刻と最終更新時刻は、(new Date()).getTime()で取得できる形式の整数値です。最終更新時刻を取得できなかった場合は0になります。訪問回数は1以上の整数値です。
ページのURIを文字列として保持していますが、これは、利用してもしなくても構いません(実際、Web Mapでは利用していません)。なお、初期状態では、このURIは「?」以下と「#」以下を削除した形で記録されます。
faviconの情報
<NC:Icon>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/common/favicon.png">
<WMNS:ImageData RDF:resource="file://..."/> ←キャッシュファイルのURL
<WMNS:Page RDF:resource="https://piro.sakura.ne.jp/"/> ←このfaviconを参照しているページ
...
</RDF:Description>
</NC:Icon>faviconの情報は http://home.netscape.com/NC-rdf#Icon のリソースとして保持しています。一つのページに複数のfaviconが設定されている場合、ノードの情報はこのリソースを複数個持つことになります。
キャッシュファイルはリソースとして関連付けられています。ただし、faviconを正常に取得できなかった場合、例えばfaviconのファイルが404 Not Foundだった場合などは、リソースではなくリテラルとして data: という値を保持します。
<NC:Icon>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/common/favicon.ico"
WMNS:ImageData="data:">
...
</RDF:Description>
</NC:Icon>なお、この仕様を見ると分かるとおり、faviconのデータはdata:スキーマを使って直接RDFデータソース内に保持することもできます。Web Mapは標準では取得したfaviconをファイルそのままの形でキャッシュしますが、隠し設定を変更すると、data:スキーマを使ってリテラルとして保持するようになります。
faviconの情報には、そのfaviconを参照している全てのページがリソースとして関連付けられています。
<WMNS:AvailableIcon RDF:about="https://piro.sakura.ne.jp/common/favicon.png" />そのページが複数個のfaviconを持っている場合に、どのfaviconを表示するかの情報は、 https://piro.sakura.ne.jp/rdf/webmap#AvailableIcon として保持しています。
サムネイルの情報
<WMNS:Thumbnail RDF:about="file://.../piro.sakura.ne.jp/tn123456.jpg" />サムネイルの情報は https://piro.sakura.ne.jp/rdf/webmap#Thumbnail のリソースとして保持しています。ファイル名は接頭辞「tn」とランダムな数値との組み合わせで、ファイル形式はMozillaが表示可能な任意の形式です。
履歴としての情報
<WMNS:OlderEntry RDF:about="https://piro.sakura.ne.jp/xul/xul.html" />
<WMNS:LaterEntry RDF:about="https://piro.sakura.ne.jp/latest/" />Web MapはWeb閲覧の履歴でもあります。個々のノードは時系列順に互いを辿れるよう、 https://piro.sakura.ne.jp/rdf/webmap#OlderEntry として「自分の前の/自分より古い」エントリを、 https://piro.sakura.ne.jp/rdf/webmap#LaterEntry 「自分の次の/自分より新しい」エントリを、それぞれリソースとして保持しています。これらを辿ることによって、処理系は履歴データを時系列順に処理することができます。
なお、全てのノードの中で「最初のノード」であるノードは、OlderEntryを持ちません。また、「最後のノード」であるノードはLaterEntryを持ちません。
アークの情報
Web Mapの履歴データは、ページ同士の関係を、単純な「リンク元リソースからリンク先リソースへの参照」ではなく、「アーク」という独立したリソースの情報として保持しています。これにより、「よく訪問するリンクは強調して表示する」などの応用が可能になります。
<WMNS:Arcs>
<RDF:Seq RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arcs:
http%3A%2F%2Fpiro.sakura.ne.jp%2F">
...
</RDF:Seq>
</WMNS:Arcs>そのページに関連付けられた全てのアークの情報は、 https://piro.sakura.ne.jp/rdf/webmap#Arc のシーケンシャルなコンテナに保持しています。コンテナのURIの末尾には、そのページのURIをURIエンコードした文字列が付与されます。
個々のアークの情報
<RDF:li>
<RDF:Description RDF:about="https://piro.sakura.ne.jp/rdf/webmap#urn:webmap:arc:
http%3A%2F%2Fpiro.sakura.ne.jp%2F:
http%3A%2F%2Fpiro.sakura.ne.jp%2Flatest%2F"
NCWB:ForeignDomain="false" ←別ドメインへのアークかどうか
NCWB:LastVisitDate="1101020527843" ←アークの最終訪問時刻
WMNS:VisitedCount="1"> ←アークの訪問回数
<WMNS:ArcType RDF:resource="https://piro.sakura.ne.jp/rdf/webmap#Link"/> ←アークの種別
<WMNS:From RDF:resource="https://piro.sakura.ne.jp/"/> ←遷移先URI
<WMNS:To RDF:resource="https://piro.sakura.ne.jp/latest/"/> ←遷移元URI
</RDF:Description>
</RDF:li>個々のアークは、URIの末尾に 遷移元URIをURIエンコードした文字列:遷移先URIをURIエンコードした文字列 という形式の文字列が付与されます。二つのURIのエンコード後の文字列が「:」によって連結されていることに注意してください。なお、この文字列がこのアークのID名となります。
アークは、「ページ中のリンク」以外にも様々なケースで作られ得ます。例えば、先読みであったり、メタデータとして関連付けられていたり。このような「アークの種類」は、 https://piro.sakura.ne.jp/rdf/webmap#ArcType でリソースとして保持しています。現在の所は、以下の値が有効です。
- https://piro.sakura.ne.jp/rdf/webmap#Link
- リンク文字列やJavaScriptなどによってページの遷移が明示されていることを示す。現在の実装では、単純に、遷移先のページを読み込んだ段階で HTTP_REFERER が設定されていればこの種類のアークと見なす。
- https://piro.sakura.ne.jp/rdf/webmap#SameDomain
- リンクはされていないが、同じドメイン内のページであることを示す。なお、Web Mapでは、隠し設定を有効にしないと記録もレンダリングも行わない。
アークは遷移元と遷移先のURIをリソースとして保持しています。遷移元と遷移先のドメインが異なるかどうかの情報は、それぞれのURIを比較すればもちろん分かりますが、後々の利用のために、 https://piro.sakura.ne.jp/rdf/webmap#ForeignDomain にtrueかfalseのリテラルで情報を保持しています。
個々のアークの情報を保持するデータソース
データソースをドメインごとに分割する設定の場合、前述の「個々のアークの情報」は、遷移元URIのドメイン用のデータソースのみに保持されます。
例えば http://www.google.co.jp/ から https://piro.sakura.ne.jp/ へのリンクのアーク情報であれば、piro.sakura.ne.jp のデータソースに含まれる「そのノードのアーク一覧」には、単純に「このノードにはURIが ...urn:webmap:arc:http%3A%2F%www.google.co.jp%2F:http%3A%2F%2Fpiro.sakura.ne.jp%2F のリソースがアークとして関連付けられている」という情報だけが記録されます。
ただし、例外的に、https://piro.sakura.ne.jp/rdf/webmap#ForeignDomain の情報だけは両方のデータソースに記録されます。これはいくつかの局面で処理を単純化するための措置です。
Web Mapのバックエンドを使用して履歴データを読み書きする場合のヒント
Web Mapのバックエンドは chrome://webmap/content/webmapService.js 内で定義されているサービスとしてのオブジェクト WebMapService において実装されています。このオブジェクトのメソッドを使用すれば、前述のようなややこしいデータを割と簡単に処理することができます。
ノードの情報の更新
ノードの情報は、 WebMapService.updateNode() で更新できます。データソースのファイルの生成、アークの更新など、適切なメッセージを与えることで全て自動で処理してくれます。
このメソッドはメッセージ用のオブジェクト一つだけを引数として取ります。
var message = {
URI : 'https://piro.sakura.ne.jp/',
linkedURI : 'https://piro.sakura.ne.jp/latest/',
title : 'outsider reflex',
isActive : true,
incrementCount : true
};
WebMapService.updateNode(message);メッセージオブジェクトには以下のプロパティを設定できます。
- URI(文字列, 初期値:null)
- 更新対象のノードのURI文字列。
- linkedURI(文字列, 初期値:null)
- 「リンク元」のページのURI文字列。これが渡されると、リンクとしてのアークを自動的に生成する。
- title(文字列, 初期値:null)
- 更新対象のノードのタイトル。
- isActive(真偽値, 初期値:false)
- 例えば「現在のタブで読み込まれた」「最全面のウィンドウで読み込まれた」など、そのノードが現在注目された状態であることを示す。
- incrementCount(真偽値, 初期値:false)
- 訪問回数を増加させるかどうかを示す。また、この値がtrueだと、このノードは履歴の中で一番最後のエントリとなる。この値がtrueで、且つ、リンク元URIが指定されている場合、アークの訪問回数も一緒に増加させる。
- lastModified(数値, 初期値:null)
- そのページの最終更新時刻。
アークの情報の更新
アークの情報のみを更新する場合、 WebMapService.updateArc() を使います。
このメソッドはメッセージ用のオブジェクト一つだけを引数として取ります。
var message = {
fromURI : 'https://piro.sakura.ne.jp/latest/',
targetURI : 'https://piro.sakura.ne.jp/',
isLink : true,
incrementCount : true
};
WebMapService.updateArc(message);メッセージオブジェクトには以下のプロパティを設定できます。
- fromURI(文字列, 初期値:null)
- 遷移元ノードのURI。
- targetURI(文字列, 初期値:null)
- 遷移先ノードのURI。
- isLink(真偽値, 初期値:false)
- このアークが「リンク」であるかどうかを示す。
- incrementCount(真偽値, 初期値:false)
- 訪問回数を増加させるかどうかを示す。
現時点では、isLinkがfalseの場合は何もしません。また、遷移元と遷移先のどちらかが空の場合も、何もしません。
ノードの削除
ノードの情報を削除する場合、 WebMapService.removeNode() を使います。
このメソッドは、削除対象のノードのURI、ノードのRDFリソース(nsIRDFResource)、メッセージ用のオブジェクトの、いずれかを引数として取ります。言い換えれば、どれを渡してもちゃんとノード情報を削除します。また、ノードを削除すると、連動してそのノードに関連付けられている全てのアークも削除されます。
WebMapService.removeNode('https://piro.sakura.ne.jp/');メッセージオブジェクトを使う場合、以下のプロパティを設定します。
- URI(文字列, 初期値:null)
- ノードのURI。
URIが空の場合は、何もしません。
アークの削除
アークの情報だけを削除する場合、 WebMapService.removeArc() を使います。
このメソッドは、削除対象のアークのID(遷移元URIと遷移先URIをURIエンコードしたそれぞれの文字列を「:」で繋いだ文字列)、アークのRDFリソース(nsIRDFResource)、メッセージ用のオブジェクトの、いずれかを引数として取ります。これもノードの削除と同様に、どれを渡してもちゃんとノード情報を削除します。
WebMapService.removeArc(message);メッセージオブジェクトを使う場合、以下のプロパティを設定します。
- fromURI(文字列, 初期値:null)
- 遷移元ノードのURI。
- targetURI(文字列, 初期値:null)
- 遷移先ノードのURI。
遷移元と遷移先のどちらかが空の場合、何もしません。
データソースの取得
起点ノードの情報を格納しているデータソースのnsIRDFDataSourceのオブジェクトは、 WebMapService.rootDataSource で取得できます。
ドメイン用のデータソースの取得
データソースをドメインごとに分割する設定の時に、そのドメイン用のデータソースのnsIRDFDataSourceのオブジェクトを取得するには、 WebMapService.getDataSourceForURI() を使います。
このメソッドにドメイン名かURIを渡すと、そのドメインに対応したデータソースを返します。データソースのファイルが存在しない場合はnullを返します。また、第二引数としてtrueを与えると、データソースのファイルを自動的に生成してからデータソースのオブジェクトを返します。データの書き込みを行う場合は、必ず第二引数にtrueを渡してデータソースを取得するようにしてください。
var ds = WebMapService.getDataSourceForURI('https://piro.sakura.ne.jp/', true);ノードの自動配置のアルゴリズム
こんな情報必要か? と思ったんですが、中間発表の時に何か特記事項の説明ということで担当教官に訊かれたので。その道の専門家の方々が見れば子供だまし以前の「なんじゃこりゃ?!」的なやり方だとは思いますが、僕の頭で思いつく方法はこれが限界だったのです……
他のノードに重ならないように配置する処理
Web Mapでは、新しく生成したノードを画面上で自動的に配置するにあたって、可能な限り既存のノードと重ならないように配置します(というか、してるつもりです)。
グリッドのサイズの決定
Web Mapを実装しているXUL/SVG/JavaScript/XPCOMでは、ある座標の場所の情報を得るといった方法はありません。いや、実はあるんですが、開発環境のSVGビルドのFirefoxではその方法が使えなかったので、別の方法を使ってこれからの処理を行っています。それが、グリッドを使った計算です。
 グリッドの大きさは、ここでは仮に「g」としておきます。このグリッドの大きさは、後述する基準ノードが「同じドメイン」「似たドメイン」「全然異なるドメイン」「全く無関係」のいずれかによって変化します。(同じドメインの場合が最小、全然無関係の場合が最大。それぞれの場合のデフォルト値は16, 128, 384, 640)
グリッドの大きさは、ここでは仮に「g」としておきます。このグリッドの大きさは、後述する基準ノードが「同じドメイン」「似たドメイン」「全然異なるドメイン」「全く無関係」のいずれかによって変化します。(同じドメインの場合が最小、全然無関係の場合が最大。それぞれの場合のデフォルト値は16, 128, 384, 640)
中にノードが置かれていないグリッドを見つけ出し、そこに新しいノードを置くということで、Web Mapではノードを重ならないように配置しています。
基準点の決定
グリッドの次は、配置の基準とするノードの位置を取得します。基準にするノードは、新しいノードに対する「リンク元」や「同じドメインのノード」、「最後にフォーカスしたノード」などです。
ノードが配置されているSVGの座標系は、原点が左上の方にあって、右に行くほどXが大きく、下に行くほどYが大きいというものです。Web Mapではその座標系において、SVGのforeignObject要素を使ってXULのボックス要素を埋め込んでいます。
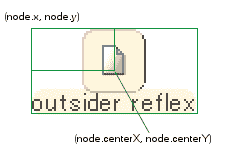 個々のノードはforeignObjectのボックスの一番左上の頂点を基準に描画されており、この基準点の座標が (node.x, node.y) です。しかし、ノードのアイコンの下にラベルを表示するという現在のスタイルだと、大抵の場合、このボックスの左上の頂点は「何もない場所」になっています。ここを基準にしてアークの描画などを行うと妙ちきりんなことになってしまいますので、この座標とは別に、各ノードはボックスの中央の座標 (node.centerX, node.centerY) の情報を持っています。自動配置の処理においても、この中央の座標を基準として計算を行います。
個々のノードはforeignObjectのボックスの一番左上の頂点を基準に描画されており、この基準点の座標が (node.x, node.y) です。しかし、ノードのアイコンの下にラベルを表示するという現在のスタイルだと、大抵の場合、このボックスの左上の頂点は「何もない場所」になっています。ここを基準にしてアークの描画などを行うと妙ちきりんなことになってしまいますので、この座標とは別に、各ノードはボックスの中央の座標 (node.centerX, node.centerY) の情報を持っています。自動配置の処理においても、この中央の座標を基準として計算を行います。
ちなみに、基準のノードが無い場合は、座標系の原点を基準点にします。
走査点を設定する
 基準点が決まったら、基準点を中心とした半径gの円の円周上の任意の点 (sX, sY) を走査点として設定します。「g」は、前述したグリッドの大きさです。
基準点が決まったら、基準点を中心とした半径gの円の円周上の任意の点 (sX, sY) を走査点として設定します。「g」は、前述したグリッドの大きさです。
走査点の位置を決定するX軸からの角度Rは、 乱数を用いて0~360°の範囲で決めます。
座標の回転には、よく知られた以下の式を使っています。
- x' = x cosθ - y sinθ
- y' = x sinθ + y cosθ
JavaScriptではMath.sin()とMath.cos()を使って計算が可能ですが、これらのメソッドの受け取るθの単位はラジアンなので、当然ながら θ = Rπ/180 の計算を行う必要があります。
なお、先の式は原点を中心とした回転の式ですので、走査点を回転するにあたっては、まず「原点を中心とした半径gの円周上」を回転させ、その後、走査点の座標を基準点の座標分だけ平行移動しています。
走査点を動かす
基準点を中心として前述の基準角rごとに走査点を回転させ、新しくノードを配置したい点の座標 (newX, newY) を求めます。(なお、基準角rのデフォルト値は30°)

そこにノードを置いていいかどうかを調べる
ここまでの段階では、基準となるノード以外のノードとの位置関係は考慮していません。走査点の位置にそのまま新しくノードを置くと、他のノードに重なってしまう恐れがあります。そのような事態を可能な限り避けるために、ここで「新しいノードを本当にここに置いていいのかどうか」のチェックを行います。
以下のチェックで「ここには新しいノードを置けない」と判断した場合は、走査点を基準角rごとに回転し、同じチェックを繰り返していきます。また、360°一周してもチェックを通過できなかった場合、基準点からの距離を2gにしてもう一週、それでもまだ駄目ならば距離を3g、とどんどん増やして、「新しいノードを置ける場所」が見つかるまで延々走査し続けます。なお、ノードの配置をばらつかせるため、回転の方向は一周するごとにランダムに変化します。
チェック1:グリッドごとの排他処理
まず単純なチェックとして、最初に持ち出した「グリッド」単位で排他処理を行います。すなわち、このグリッドに「先客」がいるなら、ここには新しいノードを置けないということです。
グリッドの位置は、先の座標をグリッドの大きさで割った物の小数点以下切り上げで求められます(Math.ceil(newX/g), Math.ceil(newY/g))。
 XUL+SVGというXMLベースの実装でこの処理を実現するために、Web Mapでは属性を使用しています。
XUL+SVGというXMLベースの実装でこの処理を実現するために、Web Mapでは属性を使用しています。
各々のノードは、生成された時点であらかじめ、自分が位置するグリッドの座標を gridPosition<LEVEL>="10:20" という形式の属性として設定されています(LEVELは前述のグリッドの大きさを表す)。そのため、 newGridPosition = Math.ceil(newX/g) +':' + Math.ceil(newY/g); document.getElementsByAttribute('gridPosition<LEVEL>', newGridPosition) として得たノードリストの長さを見れば、そのグリッドにノードがあるかどうかを知ることができます。
ちなみに、document.getElementsByAttribute()というメソッドは、属性値とその値をキーとしてノードリストを得るという、DOM Level3を先取り実装したXULDocumentオブジェクトのメソッドで、標準のDOM Level2やSVG用のDOMには存在しません。この方法はXULの中にSVGの要素を埋め込んでいるからこそ可能な方法といえます。
チェック2:既存のノードとのニアミスを避ける
先のチェックだけでは、既存ノードとのニアミスが起こることがあります。
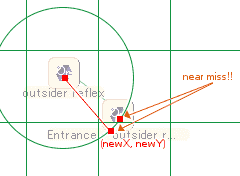 新しいノードの位置がグリッドの境界線ギリギリで、既存ノードが隣のグリッドの境界線ギリギリにある場合、先のチェックで「空きグリッド」と見なしていても、実際にはノード同士が重なってしまいます。マップを見やすくするには、こういったニアミスを可能な限り避けなくてはなりません。
新しいノードの位置がグリッドの境界線ギリギリで、既存ノードが隣のグリッドの境界線ギリギリにある場合、先のチェックで「空きグリッド」と見なしていても、実際にはノード同士が重なってしまいます。マップを見やすくするには、こういったニアミスを可能な限り避けなくてはなりません。
Web Mapではこのために、新しいノードを配置するグリッドの周囲のグリッドについて、それらのグリッドに含まれる既存ノードと、新しいノードとの距離を調べるようにしています。具体的には、ノード間の距離Lがグリッドの大きさgよりも小さい(近い)場合に、ニアミスと見なし、ここには新しいノードを置けないと判断します。
なお、ノード間の距離Lは、二つのノードそれぞれの中心座標 (x1, y1) と (x2, y2) から、Math.sqrt((x1-x2)*(x1-x2) + (y1-y2)*(y1-y2)) で求められます。
 格子状のグリッドを想定した場合、周囲のグリッドは全部で8つあることになります。理屈の上では、この8つそれぞれに対して、先ほども使った
格子状のグリッドを想定した場合、周囲のグリッドは全部で8つあることになります。理屈の上では、この8つそれぞれに対して、先ほども使った document.getElementsByAttribute() でノードリストを取得し、一つ一つ距離を比較していくことになります。ただ、8つ全てをチェックすると場合によっては途方もない時間がかかりますので、Web Mapでは、処理を簡略化するために、新しいノードがそのグリッドの第1~第4象限のどこにあるかを最初に判断して、そこに一番近い周囲3つのグリッドのみについてチェックを行うようにしています。
新しいノードがグリッド内のどの象限にあるかは、 Math.ceil(Math.abs(newX/g*2)) % 2 と Math.ceil(Math.abs(newY/g*2)) % 2 の値を見て判別することができます。なお、Math.ceil(Math.abs(newX/g*2)) % 2 というのは、「グリッドの大きさを半分にした時に、そのノードが含まれるグリッドの座標を、2で割った余り」です。
| Math.ceil( Math.abs( newX/g*2 )) % 2 == 1 | Math.ceil( Math.abs( newX/g*2 )) % 2 == 0 | |
|---|---|---|
| Math.ceil( Math.abs( newY/g*2 )) % 2 == 1 | 第2象限 | 第1象限 |
| Math.ceil( Math.abs( newY/g*2 )) % 2 == 0 | 第3象限 | 第4象限 |
新しくノードを配置する座標が決まったら……
ここまでで見つけた「新しくノードを配置する座標」は、「新しいノードの中心座標」です。しかし、各ノードは「ボックスの左上の頂点」を基準として描画されますので、ここで取得した値をそのままノードの配置に使ったのでは、場合によっては、見かけ上のノードの配置位置が大きくずれてて不自然なことになってしまいます。
しかし、ノードのボックスの大きさは実際に描画されるまでは決定されないため、この時点で「新しいノードの正確な中心座標」を知ることは困難です。そのため、ここでは次善の策として、新しいノードの大きさは配置の基準にしたノードと同じくらいのはずと仮定して、基準ノードの幅・高さから仮の「左上の頂点の座標」を求め、それを返すようにしています。
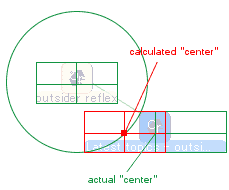 とはいえ、この座標はあくまで、「ノードの大きさが近いと仮定して求めた座標」なので、実際にノードが描画された際にはズレが生じることも多いです。手抜きだからしょうがないですね。
とはいえ、この座標はあくまで、「ノードの大きさが近いと仮定して求めた座標」なので、実際にノードが描画された際にはズレが生じることも多いです。手抜きだからしょうがないですね。
なお、新しく生成するノードにはこの時点で、「4種類のサイズのグリッドそれぞれにおいての座標」を属性として設定しておき、次の新しいノードを配置する時に備えておきます。(ノードを自分で移動した場合は、グリッドの座標の情報もそれに応じて自動的に更新されます)
クラスタ化について
Web Mapでは、ノードを配置するにあたって、前述したとおり、新しいノードを基準ノードとの関係が「同じドメイン」「似たドメイン」「全然異なるドメイン」「全く無関係」のいずれであるかを判断し、それを基準ノードからの離れ具合に反映させます。よって、この際の離れ具合を適当に設定しておくと、使い込むうちに、生成されたマップが自然とクラスタ化されてきます。
離れ具合の判定基準は、現在の所、ドメイン名とリンクの状況のみです。
- レベル1:同じドメイン →ごく近くに配置
- これは、単純な比較によります。
- レベル2:似たドメイン →少し離れたところに配置
- ドメイン名のうち、サブドメインと思われる部分を取り除いた部分や、場合によってはTLDを取り除いた部分などを見て、比較を行います。
- レベル3:全く異なるドメイン →かなり離れたところに配置
- 前の二つの比較でドメインが一致せず、しかし、リンクを辿って辿り着いたなど、何らかの関係がある場合はこれにあたります。
- レベル4:全く無関係なドメイン →非常に離れたところに配置
- リンク関係も何も全くない、完全に無関係の場合は、これになります。
キーワードで比較を行って、近いキーワードのドメインの所に配置するようにすると、またさらに面白いことになるのではないかと思います。ただし、そこまで行くと僕の手には完全に余ってしまうので、それについては全く手を着けていません。
隣のノードをゴムひもで繋いだようにぐにぐに動かすアルゴリズム
Web Mapでは、ノードをドラッグすることで自分で配置を変えられます。
しかし、たくさんのノードを動かす時、いっこいっこ動かすのは非常にめんどくさいです。複数ノードを選択すればまとめて動かせますが、選択するのがやっぱりめんどくさいです。そういうわけで、3Dアトリエのバーテックスリレーション(バーテックス:頂点)のように、選択したノードを中心として周囲のノードもつられて動くような処理を組み込んでみました。
この手のグラフ化ツールでは、先の「ノードを適当にばらつかせる」処理も含めて、TouchGraphなどで採用されているばねモデルを使った力学シミュレーションを使うのが一般的(同アルゴリズムによるデモを触ってみれば、その効果がよく分かる)だそうです。が、文系人間の僕にはTouchGraphのソースコードを見てもさっぱり意味が分かりません。そもそもJava知らないし英語わかんないし。
そんなわけで、Web Mapではばねモデルの代わりにもっと泥臭いアルゴリズムを使って、上記のような挙動を実現してみています。その筋の方にとっては噴飯ものだとは思いますが、僕の頭ではこれが限界なのです……(そればっかやな)
基本的な理屈
偽バーテックスリレーションの理屈は至極単純で、「ドラッグしているノードからの離れ具合に応じて、周囲のノードも少なめに移動する」というものです。具体的に図を交えて説明すると、
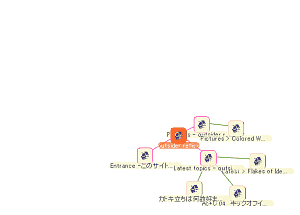 これが
これが
 こうなるにあたって、
こうなるにあたって、
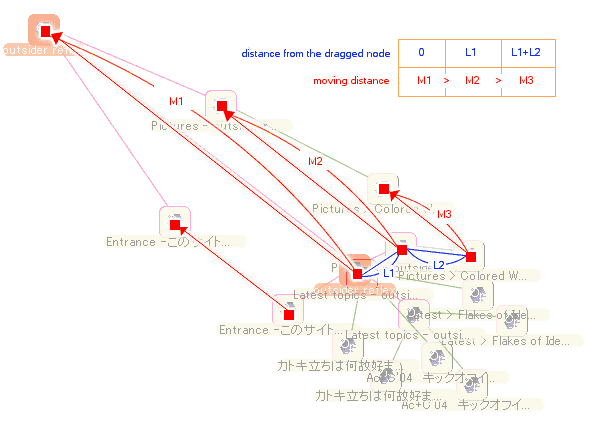 ドラッグしたノードの移動距離をM1、そのノードにL1の距離で隣接するノードの移動距離をM2、さらにそのノードにL2の距離で隣接するノードの移動距離をM3とおいた時に、ドラッグしたノードからの距離(0, L1, L1+L2)と、元の位置からの移動距離(M1, M2, M3)の間に、負の相関関係を成り立たせるということですね。この「負の相関関係」をいかに定義するかが、ぱっと見での「自然なばねっぽさ」を演出できるかどうかのポイントになります。
ドラッグしたノードの移動距離をM1、そのノードにL1の距離で隣接するノードの移動距離をM2、さらにそのノードにL2の距離で隣接するノードの移動距離をM3とおいた時に、ドラッグしたノードからの距離(0, L1, L1+L2)と、元の位置からの移動距離(M1, M2, M3)の間に、負の相関関係を成り立たせるということですね。この「負の相関関係」をいかに定義するかが、ぱっと見での「自然なばねっぽさ」を演出できるかどうかのポイントになります。
実際の処理手順1:基本的な計算
試行錯誤をすっ飛ばして、とりあえず僕が使うことにした計算方法はこんな感じです。
- 基準となる距離をLとおく。(算出方法は後述)
- 実際にドラッグしているノードnode1から、計算対象のノードnode2までの総距離(直線距離ではなく、アークを辿っての距離の合計)をdとおく。
- この時、node1の移動距離に対するnode2の移動距離の係数を、 √(L/d) と定義する。
基準となる距離Lは、とりあえず、「ノードの高さh」と「node1から直近の隣接ノードnodeNまでの距離dNの、dN/h倍」のうちの短い方を使うことにします。これはJavaScriptでは以下のようになります。
var h = node1.height;
var dN = Math.sqrt(
(node1.centerX - nodeN.centerX) * (node1.centerX - nodeN.centerX) )
- (node1.centerY-nodeN.centerY) * (node1.centerY-nodeN.centerY)
);
var L = Math.min(h, dN*(dN/h));なぜ幅ではなく高さかというと、ノードの幅はラベル文字列の長さによって大きく変化するからです。また、ノード同士が重なりあうほど近い位置にある時は、ノード同士の距離の方が短くなるので、そちらを基準にします。
何故距離の「dN/h倍」かというと(いや、べつに1倍以下なら何倍でも構わないのですが。だから「dN/h」という式自体には深い意味はありません)、これが1倍だと、直近の隣接ノードnodeNの移動距離の係数が1になってしまうからです。係数が1ということは、つまり、実際にドラッグしているノードnode1と全く同じ分だけ動いてしまうということです。それでは見た目にまずいので、とりあえず1より必ず小さくなるように、dN/h倍してます。いいかげんですね。
√(L/d) 、JavaScriptで書くと Math.sqrt(L/d) という式は、いくつかの式を試してみて、比較的「それっぽく」見えるかな? と思えた物です。他にも L/d (これは周囲のノードがあんまりついてきてくれなかった)とか (L/d)2 (これは周囲のノードが全然ついてきてくれなかった)とか色々試しましたが、自分はこれが一番しっくり来ました。ものすごくいいかげんですね。全然論理的じゃないですね。
実際の処理手順2:慣性の考慮
慣性というと大層ですが、要するに、いらんノードまで動かさないようにしたいということです。
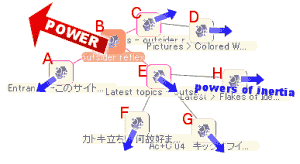 もしこれが本当に物理シミュレーションになっているなら、あるノードを動かそうとしても、他のノードは慣性によって現在の場所にとどまろうとするはずです。また、たくさんの子が連なっているノード(この図であればEなど)は、子ノード達に引き留められる力も加わり、より強く現在の場所にとどまろうとするはずです。これを、物理シミュレーションなしでそれっぽく再現できないものだろうか、というのが、ここでの本題です。
もしこれが本当に物理シミュレーションになっているなら、あるノードを動かそうとしても、他のノードは慣性によって現在の場所にとどまろうとするはずです。また、たくさんの子が連なっているノード(この図であればEなど)は、子ノード達に引き留められる力も加わり、より強く現在の場所にとどまろうとするはずです。これを、物理シミュレーションなしでそれっぽく再現できないものだろうか、というのが、ここでの本題です。
Web Mapでは、このような効果を出すために、先の計算においてdに子ノードの数Nをかけています。ということは、先の係数を求める式は実際には √(LN/d) という形で使われていることになります。
dを増やすということは、node1からの距離が遠くなったのと同じ扱いにするということなのですが、その結果として、ぶら下がっている子ノードの数が多ければ多いほど先の係数は極端に小さくなります。つまり、多数の子ノードに引き留められているのと「似たような」結果になると言えます。
これでどこまで「それっぽい」動きになるのかは分かりませんが、というか、非常に不自然な動きになりそうな気もするのですが、せっかくなので使ってみている次第です。