Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

さくらのレンタルサーバーの一番安いプランでWebサイトを公開するノウハウ - Dec 04, 2016
このエントリはさくらのアドベントカレンダー(その2)とのクロスポストです。(→Qiitaの方の投稿)
この記事では自分で自由に使えるLinuxなサーバーかPCがあるという事を前提として、さくらのレンタルサーバーのライトプランで静的コンテンツだけのWebサイトを公開・運用する際のノウハウをご紹介します。
なお、自分では調べていませんが、スクリプト内で使用しているlftp等のコマンドがHomebrew等でインストール可能なのであれば、macOS(OS X)でもこの方法をそのまま使えるかもしれません。
定期的にブラウザのタブを再読み込みしてスクリーンショットをSlackに投稿するシェルスクリプト - Dec 03, 2016
このエントリはLinux Advent Calendar 2016とのクロスポストです。(→Qiitaの方の投稿)
連載の方で書くには粒度の大きい話題だったので公開するのにいい場所はないかなあと思っていたらLinux Advent Calendarという名前を見かけて、まだ空きがあったので「これや!」と思って勇んでエントリーしたのですが、埋まってみると皆さん当たり前ですがカーネルの話中心で、そんな中で一人だけディストリビューションより上のレイヤの話でなんかほんとごめんなさい……シェルスクリプトアドベントカレンダーとかの存在を知ったときにはもう後の祭りでして……
そんな感じで空気まるで読めてない内容ですが、生暖かい目で見て頂けましたら幸いです。
GUIアプリを制御するシェルスクリプト
先日参加したイベントの懇親会で、「シス管系女子」の本をご覧になった方から「Google Analyticsのグラフを何分間隔とかでスクリーンショットとってSlackに流したいんだけど、本にはそういう話は書かれてなかった……」というご相談を頂きました。

本の中では主にSSHでLinuxのサーバーにリモート接続してコマンドで操作する時の話を取り扱っているため、GUIアプリの話はあまり、というか全然取り扱っていません。しかし、何かしら方法はありそうな気がします。
という話をつぶやいたところ、フォロワーの方にヒントを教えて頂けて、最終的にそれらしいことを実現できる筋道が立ちました。なのでこの場を借りて、得られた知見を共有したいと思います。
「技術書典」参加しましたれぽ - Jun 26, 2016
技術書典に参加してきましたので、MozLondonの技術面以外の話をほったらかして先にこっちの話を書いておきます。

技術書オンリーイベントとは?
個人や小規模の団体などによる自費出版物=同人誌の即売会には「オールジャンルイベント」と「オンリーイベント」の2種類があります。「コミックマーケット」はオールジャンルイベントの代表例で、マンガ小説評論写真集その他色々な種類・内容の作品が取り扱われています。一方のオンリーイベントでは、取り扱われる作品が「艦これオンリー」や「弱虫ペダルオンリー」のように特定のタイトルのファンアートだけだったり、「耳キャラオンリー」のように特定のキーワードに関係する作品だけだったりという風に、イベント全体が特定のジャンル性を帯びています。
オールジャンルイベントには電子工作の話だったりプログラミングの話だったりという技術的な話題を扱う作品も出展されていることがあり、これらは大まかに「技術系ジャンル」という括りになっています。このジャンルの(おそらく初の)(自分が知らなかっただけで前例はあったようです)オンリーイベントが、今回の「技術書典」というわけです。
そういう文脈なので、イベントの体裁は自分が見たところまさしく「同人誌即売会」という感じでした。他のオンリーイベントとの違いというと、そこに「企業ブロック」という扱いで、OSCの会場で見かけるような翔泳社やオライリーといった技術書に強い出版社の販売ブースが普通のサークルと机を並べて存在していたという点でしょうか。
シス管系女子のスペース
今回は、自分は「シス管系女子」の名前で企業として参加しました。企業参加とはいっても日経BP主導ではなく、僕個人が技術書典の情報を見つけて「参加したい!」と言ってゴネて、頒布物作りや当日の作業は自分でやるということでスポンサードして頂いた感じです。基本的に商業出版物は企業参加で申し込むようにというレギュレーションもありましたし。
シス菅系女子!!!#技術書典 #通運会館 #2F pic.twitter.com/pl7prmf4Ev
— 戸倉彩@C90日曜日(西4f38a) (@ayatokura) 2016年6月25日
(写真を撮り忘れたので戸倉さんのツイートを引用)
頒布物は新作描き下ろし(ただし下描きクオリティ)の8ページのコピー本と、既刊のムック2冊でした。 コピー本の内容はpixivにまるっと上げてあります。 そのうちシス管系女子の特設サイトにも載せるつもり。
<script src="http://source.pixiv.net/source/embed.js" data-id="57590783_33fd1695fde5334093fd08b34d503ac6" data-size="medium" data-border="on" charset="utf-8"></script><noscript>
シス管系女子BEGINS 第0.1話 by Piro on pixiv
</noscript>最初は普通にスペースに置いておいて、本を買って下さった方に渡したり、見てくれた人に「無料です」と言ってそのまま持って行ってもらったりというつもりでいたため、100部持ち込んで(コミケの技術島だったら「多すぎやろ」レベルの数)余ったらOSC等の会場でチラシのスペースに置いてもらうとかすればいいかなーと思っていたのですが、ヘルプで入ってもらった売り子さんの提案で「どうせ無料ならどんどん配った方がいいのでは?」という事になって、配り始めたらあっという間に足りなくなってしまいました。幸い、会場から徒歩で行ける距離にキンコーズがあったため、なくなりそうになったら行ってセルフコピーで200部増刷するという事を2回繰り返して、閉会30分前くらいの時点で合計500部を配りきりました。 (イベント側でも当日増刷システムなどの試みをしていたようですが、自分は制作フォーマットが違った&毎度の通り作業がギリギリになってしまって申し込めなかったので、自力解決したという次第……)
ムックの方は各30部ずつ持ち込んで、それぞれ残り5~6冊くらいになるまでは出ました。という所から売り上げはすぐに計算できるのですが、まぁ企業として動くには明らかに赤字なので、今回は日経BPサイドにはプロモーションと割り切って頂いた感じです。
見ていた感じだと、手に取っていただいた方には「初めて知った」という人が多かった印象で、費用対効果はさておき「今まで到達できていなかった人に認知してもらう」という事はそれなりに実現できたのではないか?と思っています。 内容の質にはわりと自信がありますので、今後もこんな感じで、今まで届けられていなかった方に届けられる方法を考えていきたいです。
あと、今回スケブ依頼は無かったのですが、会場では何人かの方にサインのご依頼を頂いたので書かせて頂きました。焦りもあって線が結構ヨレヨレになってしまいました……すみません。
会場の様子
着いてみると結構会場が狭くて、開会直後から行列がすごいことになっていたようですが、早々に入場方式を整理券方式に切り替えたらしく、会場内の人口密度が一定以上にならないようコントロールされていました。そのため、外の「何時間待ち」といった情報とは裏腹に、中は割合ゆったりとした雰囲気が保たれていたのが印象的でした。 技術系の同人誌は試し読みをするにもじっくり読む必要のある物が多いと思われるので、これは本当に良い判断だったと思います。運営のファインプレーですね。
自分も比較的ゆっくり会場を回って他のスペースの頒布物を見て回ることができ、会場の空気にあてられて結構買い込んでました。
 技術系の同人誌は分厚かったり部数が少なかったりで製造原価が高いために、頒布価格の相場が結構高いのが、普段自分がコミケ等で参加するマンガ系ジャンルとは違うものなんだなあ……と今更実感。
技術系の同人誌は分厚かったり部数が少なかったりで製造原価が高いために、頒布価格の相場が結構高いのが、普段自分がコミケ等で参加するマンガ系ジャンルとは違うものなんだなあ……と今更実感。
前例の無いイベントということで一体どれくらいの人が来るのか全く予想ができず、もしかしたら会場内のサークル参加者同士でお互いに見て回って終わりくらいの規模になるのかもと思っていたのですが、主催者発表によると一般入場者が最終集計で1300人に達していたとのことで、想像を遙かに上回る盛況ぶりに参加者として驚くばかりです。
商業出版物の流通経路に載せるほどの売り上げは見込めないけれども、この事について書きたいんだ!とか、こういう技術本を作りたいんだ!というような作り手側の思いから作られた作品達。 そういった物が集まり、読み手は作り手から直接その思いを聞けて、作り手は読み手の反応をダイレクトに得られる、というのはオフラインイベント独特の魅力だと改めて感じました。 技術書典 当日の様子でも次回開催を望む声が多く見られますし、小説・評論ジャンルのオンリーイベント「文学フリマ」が回を重ねるのみならず地方開催も行っているように、技術書典も「技術ジャンルのオンリーイベント」として確かな地位を確立していってくれるといいなあ、と思います。
続き:技術書典2のレポート
シェルスクリプトでだいたい1時間の間隔であれをやる - Jan 03, 2016
前のエントリに引き続いて、またシェルスクリプトの話。
「1時間間隔で決まった処理を行う」という目的だと、普通に考えたらまあcrontabを使う場面ですよね。
だから素直にそうしときゃいいんだけど、シェルスクリプト製のTwitter用botで自発的な自動投稿をやらせるにあたってどういうわけか「きっかり同じ時間間隔じゃなくて、確率でちょっとだけ揺らぎを持たせたい。その方が人間くさいよね。」と思ってしまって、それをやるのに一苦労しました……という話です。これは。
目指す状態
そもそも「きっかり同じ時間間隔じゃなくて、ちょっとだけ揺らぎをもって定期実行したい」というのは、一体どういう状態のことを指しているのか。 これをはっきりさせないことには話が始まりません。
僕が思ってる事をアスキーアートで図にすると以下のようになります。
00:00 基準時刻
|
00:15
|
00:30
|
00:45
|  ̄\
01:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
01:15
|
01:30
|
01:45
|  ̄\
02:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
02:15
|
02:30
|
人間の行動で言うと、こんな感じ。
- 時計を持って「1時間に1回これをやるように」と言われて、時計を見てその時刻に近かったらそれをやる。
- ちょっと早くても「まぁもうやっちゃってもいいか」ということでやる。
- ちょっと遅くても「まぁこのくらいの遅れは大丈夫でしょ」ということでやる。
- 「やらない」という選択肢は無い。「やべっ時計見落としてた!」と気がついたらその時点で慌ててそれをやる。
ちょっとばかり時間にルーズな人の取るような行動、という事ですね。
これをもうちょっと厳密に、コンピュータにも分かりやすいであろう表現に直すと、以下のように言えるでしょうか。
- 目標時刻の前後N分の範囲の時間帯を、処理を実行する可能性がある時間帯とする。
- それより早かったり遅かったりしたら実行しない。
- 目標時刻に近ければ近いほど実行の確率は高く、遠ければ遠いほど実行の確率は低い。
- 目標時刻ちょうどで最大確率、目標時刻のN分前およびN分後の時点で最低確率とし、その間は確率が線形に変化するものとする。
- ただし、その範囲の時間帯が過ぎようとしている時にまだ1回も処理が実行されていなければ、時間帯の終わりで必ず実行する。
- 計算は分単位で行う。(cronjobでも1分未満の指定はできないので)
実行確率をパーセンテージで算出できれば、あとは前のエントリでやった「何パーセントの確率であれをやる」がそのまま使えます。
となると、問題は「どうやって実行の確率を計算するか」という話になります。
今の時刻が目標時刻から何分ずれているかを計算する
先の定義に基づいて「ある時点での実行確率」を計算しようと思った時に、時刻を時刻の形式のまま扱おうとするとややこしいというか自分にはお手上げなので、「その日の0時0分を起点として、そこから何分経過したか」を使って計算していこうと思います。
そのために、こんな関数を用意しました。
# "03:20"のような時刻を与えると、00:00からの経過分数を出力する
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
これに与える現在時刻は、コマンド置換とdateコマンドを使って$(date +%H:%M)とします。
例えば現在時刻が07:58なら、以下のような出力が得られます。
$ time_to_minutes $(date +%H:%M)
478
これを「処理を実行したい時間間隔(分)」で割った余りを得ると、現在時刻が目標時刻から何分ずれているかが分かります。 60分間隔ならこうです。
$ interval=60
$ lag=$(( 478 % $interval ))
$ echo $lag
58
58分ずれている……という結果ですが、これはどっちかというと「目標時刻からマイナス方向に2分ずれている」と扱いたいところです。 なので、実際のずれが実行間隔の半分よりも大きい場合は「マイナス方向にN分のずれ」と見なすようにします。
$ half_interval=$(( $interval / 2 ))
$ [ $lag -gt $half_interval ] && lag=$(( $interval - $lag ))
$ echo $lag
2
これで「目標時刻ピッタリから何分ずれているのか」が求まったので、次はいよいよ確率の計算です。
今の時刻での実行確率を計算する
目標時刻ピッタリで確率100%としてしまうとそこで必ず実行されてしまうので、目標時刻ちょうどでの最大の確率を90%、許容されるずれの最大時点での最低の確率を10%とすることにします。
全体の振れ幅は10%から90%までの「80」ですので、「目標時刻ちょうどで100%、目標時刻からのずれが許容範囲の最大になった時を0%」とした割合に80をかけた結果に10を足せば、確率は10%から90%までの範囲に収まることになります。 式にすると、こうです。
$ probability=$(( (($max_lag - $lag) / $max_lag) * 80 + 10 ))
$ echo $probability
10
……おや? どうも計算結果がおかしいですね。
実は算術展開の$((~))は整数のみの計算なので、計算の過程で小数が出てくると小数点以下切り捨ての計算になってしまうのです。
こうならないようにするには、小数が出てこないように注意して計算するか、小数があっても大丈夫な計算方法を使う必要があります。 例えば、先に100倍してパーセンテージを求めてから後で100で割るという方法を取るなら以下のようになります。
$ probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
$ echo $probability
58
小数として計算するのであれば、数値計算用のコマンドのbcを使います。
これは、標準入力で与えられた式の計算結果を出力するコマンドなのですが、scale=1;という指定で計算時の小数点以下の桁数を指定すると、小数部を考慮した計算結果を返してくれます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc)
$ echo $probability
58.0
ただし、if [ ... ]での条件分岐では今度は整数しか扱えないので、出力される計算結果の小数部は取り除いておく必要があります。
これはsedで行えます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc | sed -r -e 's/\.[0-9]+$//')
$ echo $probability
58
ということで、ここまでをまとめて「算出した実行確率を出力する関数」にしてみましょう。
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
# 最小の実行確率より小さい時=実行する可能性がある範囲の
# 時間帯の外の時は、確率0%とする
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
同じ時間帯では重複実行しない
単にこの確率に基づいて実行するかどうかを決めるだけだと、00:55から01:05までの範囲で「実行時刻が揺らぐ」のではなく「その範囲で、確率次第で何度も実行される」という結果になります。 そうしないためには、同じ時間帯の中での再実行を防ぐ必要があります。
そのためには、最後に処理を実行した時刻を保持しておいて、現在時刻が最終実行時刻から一定の範囲内にある時は問答無用で処理をスキップする、ということになります。 とりあえず、最終実行時刻(として、00:00からの経過時間)を保存するようにしてみます。
current_minutes=$(time_to_minutes $(date +%H:%M))
probability=$(calculate_probability $current_minutes)
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
ここで保存した値を次の実行の可否の判断時に使うのですが、「最後の実行からN分間は絶対に実行しない」という条件を加えても良ければ、以下のようにできます。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
現在時刻から最後の実行時刻を引いた結果の「最終実行時刻からの経過時間」を求めて、それが指定の範囲内であれば何もしないで終了するということです。
比較の演算子が-lt(<)ではなく-le(≦)である点に注意して下さい。
-ltで比較してしまうと、00:55に実行してから10分後の01:05ちょうどの時点で「10分未満の範囲で実行されていないので、再実行してよい」と判断されてしまいます。
ただ、これだけだと日付をまたいだ時に判定が期待通りに行われません。
最後の実行時刻が例えば前日23時ちょうどだったとすると、last_doneは23*60=1380ですが、現在時刻が00:04だったとすると4-1380=-1376になってしまって、負の数は「何分間は再実行しない」という指定=正の数よりも必ず小さいので、永遠に再実行されないことになってしまいます。
なので、現在時刻から最終実行時刻を引いた結果が負の場合は、「最終実行時から0時までの経過時間」と「0時から現在までに経過した時間」の和を「最終実行時刻からの経過時間」として使う必要があります。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
その時間帯で投稿が無い時は時間帯の最後のタイミングで必ず実行する
ここまで来たらあともう一息。 最後は「その時間帯で必ず1回は実行する」という要件です。
とはいえ、これはそんなに難しく考えなくても大丈夫。 前項の段階で「指定の範囲内の時間での再実行はしない」という判定が既に行われているので、その判定の後であれば、「実行するべき時間帯の最後の瞬間で、その時間帯の中ですでに実行済みである」という場面はあり得ない事になります。 なので、単純に「今この瞬間は、実行しても良い時間帯の範囲の最後の瞬間かどうか?」を判断して、そうであれば確率100%で実行するということにすればいいです。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
# 目標時刻からのずれを計算
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
# ずれが、許容されるずれの最大値と等しければ、今がまさに
# その時間帯の最後の瞬間である。
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
...
まとめ
ここまでのコード片を全てまとめた物が、以下になります。
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
人間くさい振る舞いをする何かを作る時の参考にしてみて下さい。
追記:もっと単純なやり方
Qiitaのクロスポストの方に頂いたコメントで、以下のようにcronjobを設定すれば良いのでは?とのご指摘がありました。
55 * * * * sleep $(( $RANDOM \% 10 ))m; (実行したい処理)
実行の可能性がある時間帯の最初の瞬間にsleepを呼び、何秒間待つかは0~10分の間でランダムに決定する。その後、やりたい処理を実行する。という方法です。
「指定の時間間隔ちょうどの実行確率を最も高くしたい」「その時間帯の最初の瞬間から最後の瞬間までの間に運用を開始した時も、すぐに動作させたい」といったいくつかの要件を除外すれば、この方法が最もシンプルですね。 というか最初この指摘を見た時には「完全に置き換え可能じゃん!」とすら思ってしまいました。 (よくよく見返して、要件のいくつかがカバーされていない事にようやく気づくレベル)
無駄に複雑な要件を全て満たそうとすると手間がかかるけれども、要件の8割9割ほどを満たせれば良いという割り切りができれば手間を大きく減らせる場合がある、「そもそも本当にその要件は必要なの?」というレベルからの再考次第で実現手法を大きく簡素化できるという、いい例だと思いました。 そのあたりの絞り込みが足りないままこの記事を世に出してしまって、お恥ずかしい限りです……。
シェルスクリプトでランダムにあれをやる - Dec 30, 2015
「何分の一で」とかの情報は出てくるんだけど、知りたかったことそのものズバリの「何パーセントの確率でアレをやる」という例がなかなか見つからなかったので、まとめてみました。
シェルスクリプトで乱数
まず根底にある「ランダムに」っていう所だけど、これはBashかそうでないかでやり方が変わる。
Bashでは$RANDOMを参照すると0から32767の範囲でランダムな結果が得られる。
$ echo $RANDOM
15999
Bash以外では、/dev/urandomとodコマンドを組み合わせて似たような事ができるようだ。
$ od -vAn --width=4 -tu4 -N4 </dev/urandom
1939740834
0~N-1の範囲で乱数を得る
以下、説明を簡単にするために$RANDOMの方でコードを書くけど、違うシェルでは適宜読み替えて下さいという事で。
あと、ここからは数値計算が出てくるので、中に書いた式を計算した結果を得る$((計算式))の書き方(算術展開)を使っていく。
気を取り直して、0~N-1の範囲でランダムに1つを選ぶ方法。
これは割り算の余りを使う。
乱数をNで割った余りを求めれば、0~N-1のいずれかの数字が得られる。
例えば$(($RANDOM % 10))とすれば、0~9のいずれかの数字が得られる(つまり、10パターンに分岐できる)。
$ echo $(($RANDOM % 10))
0
$ echo $(($RANDOM % 10))
5
$ echo $(($RANDOM % 10))
3
1/Nの確率で何かやる
先の結果がどれか1つの選択肢に等しくなった時だけ処理を実行すれば、「約1/Nの確率で実行」ということになる。
[ $(($RANDOM % 3)) -eq 0 ]なら、約1/3の確率で真になり&&以下が実行される。
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
Hit!
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
ここまではすぐ例文が出てくるんだけど、ここから先が出てこなかったので自分で考える必要があった。
N%の確率で何かやる
実際に「ランダムに何かをやりたい」時というのは、多分、だいたいは「パーセンテージとか割合で頻度を指定したい」って場面だと思う。 「60%の確率で分岐したい」みたいな。
これは、「1/Nの確率で」の例を発展させるとできる。
1/100までの精度だったら、まず0~99のいずれか1つをランダムに得る。
次に、これを-lt演算子(less thanだから、左辺が右辺より小さい<の意味)で「何パーセントでやりたい」という数字と比較する。
結果が真の時だけ処理を実行すれば、つまり「何パーセントの確率で実行」ということになる。
絵を描くのが面倒なのでアスキーアートでやると、
0--------------------99
こういう数直線があって
0-----+-------------99
↑30
この位置に線を引いて、0から99までのどれか1つをランダムに選んだ結果が線より左にある時だけ実行するということです。
↓この時だけ実行 ↓こっちだったら実行しない
○ ○ × × ×
0-----+-------------99
↑30
これを踏まえて、30%の確率でRun!という文字列を出すコマンド列なら、以下のようになる。
$ if [ $(($RANDOM % 100)) -lt 30 ]; then echo 'Run!'; fi
30の所を変えれば任意のパーセンテージにできる。
関数にするならこんな感じか。
run_with_probability() {
local probability=$1
if [ $(($RANDOM % 100)) -lt $probability ]
then
echo 'Run!'
fi
}
ほんとに狙ったとおりの結果を得られているか、同じ物を1000回くらい繰り返し実行して確かめてみる。
与えた数の連番を出力するseqコマンドとforループを組み合わせて、先の関数を1000回実行し、Run!が出力される頻度を見てみる。
(forループの出力結果をパイプラインでwc -lに渡して行数を数えれば、実際に出力された回数が分かる。)
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
303
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
292
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
316
1000回中の300回前後なので、まあだいたい30%になっている。 ばらつきがあるけど、試行回数を増やせば指定のパーセンテージに収束していくはず。
実際は「一定の確率で文字列を出力する」というのを汎用的にやりたかったので、こういう風にした。
probability() {
[ $(($RANDOM % 100)) -lt $1 ] && cat
}
# 95%の確率で出力→だいたいは出力される
output_message | probability 95
# 10%の確率で出力→滅多に出ない
output_message | probability 10
入力された複数行の中からランダムに1行抜き出す
ちょっと毛色が違うけど、これもついでに。
入力に対してその中からランダムに1つをピックアップするという場面では、これはQiitaにクロスポストした方の記事のコメントで指摘を頂いて知ったんだけど、そのものずばりのshufというコマンドがある。これは標準入力で受け取った内容を行ごとにシャッフルして出力するコマンドで、-nで取り出す行数を指定できるので、以下のようにすれば「ランダムに1行取り出す」という結果になる。
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | shuf -n 1
shufコマンドの存在を知らなかった時にそれを使わずに解いてみた時には、先の「0~N-1のいずれかを得る」の応用で以下のようにしてた。
choose_random_one() {
// 標準入力を一旦変数に保持
local input="$(cat)"
// 入力の行数を得る
local n_lines="$(echo "$input" | wc -l)"
// 「1~最終行の行番号」の範囲でどれか1つを得る
local index=$(( ($RANDOM % $n_lines) + 1 ))
// 得た行番号を使って、sedで「指定された番号の行だけを取り出す」操作を行う
echo "$input" | sed -n "${index}p"
}
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | choose_random_one
入力を「行数を数える時」と「実際に抽出する時」の2回使わないといけないので、一旦全部catで読み取って変数に保持してるというのがポイントでしょうか。
まとめ
ということで、「シェルスクリプトでランダムにアレをやる」色々でした。
なんでこんな事やってるかというと、シス管系女子の宣伝を自動化したくて、宣伝用アカウントの運用をボットにやらせたかったのですが、「コマンド&シェルスクリプト」の連載なんだからボットもシェルスクリプトの方がネタになるよね&自分で作れば「お、作者はちゃんと技術分かってる人なんだな」と技術的な信頼に繋がるかな?と思って、TwitterクライアントとボットをBashでゴリゴリ書いているからなのでした。 ……って、単に宣伝を投稿するだけならTwitterクライアントができた時点でcronjobでやってしまえばよかったはずなのに、「何パーセントの確率で会話を継続する」とかそんな領域に足を踏み入れてるのは明らかにおかしいですね。ほんとに「どうしてこうなった」だ。
BtoBの仕事だったり実用のアドオンだったりでしかコード書いてないと、一定の確率で何かやるという事が必要になる場面が全く無くて(確実に何かやる、という事ばっかりだから……)、ぱっとやり方を思いつけなくて参りました。 という情けないお話。
system-admin-girl.comのこと - Dec 04, 2015
シス管系女子の特設サイトができました、というか例によって自分で作りました。 3日ほど夜なべして。
どうしてこうなった
電子書籍はいわゆる印税契約だけど紙の方は原稿料買い切り(書籍じゃなくムックだから)なので、プロモーションに工数かけてもあまり得にならないんですよね。なのに何故やったのかというと……要するに、欲しかったんですよ!!! 僕が!!!!!
いやね、連載5年目に入ろうとしてるのにWeb上では相変わらず知名度が低くて、知ってる人は知ってる的な立ち位置がいいかげん辛くなってきたというか、この間なんて「たまたま日経Linuxを見たらこんなの(#!シス管系女子Season3 Petitまとめ読み)あったんだけど、これってもしかしてシェルスクリプトマガジンのシェル女子の便乗企画……?」みたいに思われてしまった、というのは被害妄想もいいとこなんですが、「それもこれもみんな、ここ見れば大体分かるっていう位置付けの公式サイトが無いせいなんや!」と大人げなく嫉妬に狂いまして、手元にあった素材と原稿データをイラレの上で切り貼りしていわゆる1枚ペラのページのこんな妄想画像
 を作って「こういうのがほしいんだよこういうのがああああああ!! 日経Linuxのサイトの中に特設ページ作ってもらえませんかね!?」と日経BPサイドに提案してみたものの、会社の方針とかであんまり他のページと違う物は載せられないのでPDF置いとくだけならまぁなんとか……と言われてしまって「そういうことじゃないんだよおおおおお!!!」と血の涙流しながらHTMLとCSSをゴリゴリ書いてさくらのレンタルサーバの一番安いプラン借りてお名前.comでドメイン取って(独自ドメイン取るのこれが初めてですよ! なんと!)突貫工事で作った、というのが真相ですハイ。
説明文が「Piro氏」とか微妙に客観なのは、元が日経BPへの提案用だったからで。
を作って「こういうのがほしいんだよこういうのがああああああ!! 日経Linuxのサイトの中に特設ページ作ってもらえませんかね!?」と日経BPサイドに提案してみたものの、会社の方針とかであんまり他のページと違う物は載せられないのでPDF置いとくだけならまぁなんとか……と言われてしまって「そういうことじゃないんだよおおおおお!!!」と血の涙流しながらHTMLとCSSをゴリゴリ書いてさくらのレンタルサーバの一番安いプラン借りてお名前.comでドメイン取って(独自ドメイン取るのこれが初めてですよ! なんと!)突貫工事で作った、というのが真相ですハイ。
説明文が「Piro氏」とか微妙に客観なのは、元が日経BPへの提案用だったからで。
3日でできたのは十数年越しのイメトレのおかげや……
思い返せばかれこれ14~5年は前ですかね?
CSSコミューンで偉そうなこと言ってて「Web業界に進みたいな」とか一瞬思ってたあの頃。
CSS2の仕様通りに書いた物をInternet Explorerが微妙にまともにレンダリングしてくれなくて、それでもNetscape Communicator 4での悲惨な対応具合に比べればまだマシというネスケ派の自分にとっては「ギギギ……!」と歯ぎしりせずにはおれない状況で、NC4でもIEでもきちんと表示できてW3C的にも(というかAnother HTML-lint的に?)Validで且つそこそこ凝った見た目を実現して「W3Cの理想は非現実的な絵空事なんかとちゃうんやで!!!」と世界の片隅でアピールしたい!という思いからこんなスタイルシートやあんなスタイルシートやそんなスタイルシートといったいろんな実験作を書いて粋がってた日々。
当時最もCSS2の実装が進んでたGeckoエンジンでさえできることは全然限られていて、「あぁ……この仕様にある:nth-child(2n-1)ってのが使えれば装飾の左右振り分けも簡単なのに……!」と思いながらclass="even"とかclass="odd"とか書いて騙し騙しやってましたとも。
ドロップシャドウひとつ作るのにも画像を作ってスライスして……よくあんなめんどくさいことやってたもんだ。
しかも人力で。
(素人でお金も無いのでDream WeaverだのFireworksだのは手が出なかった)
素人の僕でこんなんだった訳だけど、当時から業務として手がけておられた方々は僕なんかよりはるかに切実な思いでこういう事と向き合っていたのであろう。 CSS昔話 Advent Calendar 2015 - Adventarにはそういう時期の苦労話がたくさん集まってきそうな気配を感じている。
それが、今じゃどうですか。
<ruby><rb>文字の影</rb><rp>(</rp><rt>text-shadow</rt><rp>)</rp></ruby>も<ruby><rb>ボックスの影</rb><rp>(</rp><rt>box-shadow</rt><rp>)</rp></ruby>も<ruby><rb>角丸</rb><rp>(</rp><rt>border-radius</rt><rp>)</rp></ruby>も背景色の半透明もグラデーションも<ruby><rb>奇数番目と偶数番目での振り分け</rb><rp>(</rp><rt>:nth-child(2n-1)</rt><rp>)</rp></ruby>も、テキストでちょちょいっと書けば即反映ですよ。
当時は想像もしてなかった、CSSメディアクエリーなんて物もできてるし。
あの頃「こういう風に作れればいいのになあああ!!!」とイメージトレーニングしていた理想のCSS世界がまさに目の前にあるという感慨深さよ。
document.querySelectorAll()で要素をガッと集めてきて制御したり、今画面内にある画像をdocument.elementFromPoint()でダイレクトに取得して位置合わせしたり、Firefoxのアドオン開発でも苦労してた部分があっさりクロスブラウザで動いてくれちゃってて。
FirefoxとChromeのWindows版とAndroid版でだけ検証してリリースしちゃいましたが、後でIE11で見たら全く支障なく完璧に表示されてたし。
あまりのあっけなさに目がテンになり、その後感涙でむせび泣きかねない勢いでした。
SNSでシェアしやすく
……とまあ、昔取った杵柄で一枚ペラ&試し読み簡易マンガビューワーを作るところまではよかったんですが、宣伝のためのサイトなのにSNS連携のシェア用ボタンを入れてなかったり、FacebookやTwitterでシェアされたときにいい感じに画像を出す工夫をしてなかったり、「それやらないの今時あり得ないでしょ……」な手落ちだらけで、「エッなにそれいつの間にそんな事になってたの」と完全に浦島太郎でした。 かろうじてGoogleアナリティクスは存在を知っていたので、それだけは入れてましたが。
- ページ内に埋め込む「シェア」「Tweet」などのボタン群は、いいねボタン ツイートボタン ソーシャルボタン まとめて設置で作成しました。
- シェアされた時に狙った画像を出すogp:imageはさかどんに教えてもらいました。 メタ情報の設定後にデバッガーで強制再Fetchしないと変更が反映されないというのをいわいさんに教えてもらわなかったら、いまだに「なんでやーーー!!」と頭を抱えていたことでしょう。
- Twitterでの投稿時に狙った画像を出すTwiter Cardはちょまどさんに教えて頂きました。 ogp:imageを設定済みなら重複する情報は書かなくてもいいというのはこたろっくさんに指摘されるまで気付いてませんでした。
皆さんの助けが無ければ、作ったはいいものの結局やっぱり誰にも見られない廃墟サイト化一直線……という末路を辿っていたところでした。 大変お世話になりました。
良い物作ってるつもりでもプロモーションできてなきゃ存在しないのと同じ
思い出話8割に実用情報2割くらいでこんなエントリを書き記して何やってんのって自分でも思いますが、今僕が主たる仕事の場にしてるフリーソフトウェアの世界でも、プロモーションはやっぱ大事だなって思うんですよね。 先行実装があってそれなりに頑張って丁寧に作ってたのに、その存在を知らなかった人が後から作った荒い出来の物が「これ新しい!!! こんなの欲しかった!!!!」って人気をかっさらってって、先達の頑張りが全く誰からも評価されないまま消えていってしまう……俺達は、あと何回そんな悲劇を目にすればいい? 俺はあと何回、顧みられることの無い先駆者を目にすればいいんだ?
というわけで、今後仕事絡みで何か作って公開する時にまた参照したいので自分用のメモとして今回参照した情報をまとめたというのがこのエントリの趣旨なのでした。
まぁ、このsystem-admin-girl.comが実際どれだけ成果が出るかというのは分からない、ともすれば結局やっぱり廃墟になっちゃったねというオチもあり得そうではありますが、「だからこういう風にして欲しかったんだよぉぉおおおお!!」と地団駄踏んで不満溜め込んでるよりは、「思ってたやりたかったとおりの事やったけど駄目でしたわハハハ……」となる方がまだ精神衛生上良さそうなので、これで安心して眠れます。 おやすみなさい。
絵に描く主に女性キャラの身長体重について思ったこと - Oct 12, 2015
萌えキャラの設定体重が軽すぎる、という話を時々目にする。今日見たのは碧志摩メグがらみのやつ。
この手の議論で僕の見たことのある非難のポイントはだいたい以下の2つだった。
- 「この見た目でこの体重は物理的にあり得ない」的な、科学的整合性の問題の話
- 「こんな体重は不健康。男の欲望のために不健康な細さを女性に押し付けるとはけしからん」的な、社会的にどうあるべきかという話
1つ目の方は、適当にイメージで設定した数字が突拍子もなかったという作り手の落ち度と、絵のリアリティレベルを無視して無粋なツッコミを入れている受け手の落ち度の両方のケースのどっちもあるけど、まあ、結局の所は巨大ロボットの設定重量はどうあるべきかというのと同じ話なんで……
ややこしいのは2つ目の話。これは「フィクションを真に受けるなよ」と言っておしまいにはできない。フランスで、痩せ過ぎのファッションモデルに影響されて一般の女性が無理なダイエットをして健康を害するというのが問題になって、痩せ過ぎのモデルを使ってはならないなんて規制が設けられた事例が実際にある。「女性の理想的なスタイル」をどう表現するかは、製作者や消費者だけの問題とは言えないという面がある事は否定できない。
自分自身、シス管系女子という漫画(の形式の技術記事)を描いてて、意識的・無意識的に女性キャラに自分の好みを反映させている所はあるので、自分の好みを軽々しく表明することが社会的に問題ありと言われると……というか、「おまえそんな女なんか現実におらんのじゃこのクソキモオタ童貞が!!! おまえがゲスな欲を丸出しにするせいで女は迷惑しとんのじゃ!!!」みたいに言われると、申し訳なく思いつつ、しかしカチンとも来る。そんなに悪し様に言われるほど悪いことしてるか?って。
んで思ったんだけど、こういうのって、「見た目」と「体重」という実は関係が薄い物を、作り手も受け手も、関係が深いと誤解してることから悲劇が生まれてる部分があるんじゃないか?って。
ダイエットというか体作りの話で、見た目の体型の良し悪しは身長体重BMIよりも体脂肪率の方が影響が大きい、という話を教えてもらった。検索してみると、そういう記事や画像が結構見つかる。
 (LifestyleSupportのタイムラインより引用)
(LifestyleSupportのタイムラインより引用)
見た目の良さは体重やBMIでは測れない。何故か?
- 見た目の体型が同じでも、身長が高ければ体重は当然重くなる。
- 筋肉と脂肪は比重が違うから、同じ体重でも筋肉質なら見た目は細く、脂肪ばっかりなら見た目は太くなる。
- BMIは身長と体重から計算されるから、体重が重ければBMIの値は大きくなり、同じ見た目でも筋肉質ならBMIの値は大きく、脂肪ばっかりなら小さくなる。
じゃあ何を見れば体型の見た目の良さを数値化できるのか? それが体脂肪率だ、という事らしい。
自分が体重を落とした経緯を振り返ったり、周囲の人の事を聞いたりした感じでは、この話は結構信憑性が高いと思ってる。 数字の上で体重だけ減っても、筋肉が無ければ見た目は相変わらず貧弱なままだから、見た目を良くしたいなら筋トレもしなきゃダメなんだなー、と。 で、脂肪が落ちると同時に筋肉が増えてくると、見た目に体が引き締まってきてるのは分かるんだけど体重はあんまり変わらないという、不思議な平衡状態が発生するというのも身をもって体験しまして。
ともかく、見た目の体型は体脂肪率で決まると仮定するなら、キャラの設定は身長と体重ではなく、身長と体脂肪率と筋肉量を記載した方が各方面に誤解が無くて良いんではなかろうか?というのが、僕の提案したい事なのです。
ちなみに、シス管系女子の登場人物達の身長体重は特に設定してないのですが、先の記事にある写真
 (女性が3ヶ月で腹筋を割る方法 | スチームパンク大百科Sより引用)
で言うと、みんとちゃんは体脂肪率21%くらいとされている写真、大野先輩は26%くらいとされている写真がイメージに近くて、筋肉量については2人ともそんなに筋肉質ではないだろう……と思ってます。
(女性が3ヶ月で腹筋を割る方法 | スチームパンク大百科Sより引用)
で言うと、みんとちゃんは体脂肪率21%くらいとされている写真、大野先輩は26%くらいとされている写真がイメージに近くて、筋肉量については2人ともそんなに筋肉質ではないだろう……と思ってます。


僕自身の好みで痩せ型の想定なのは否定できないけど、このくらいの体脂肪率ならあり得ないほど不健康に細いってことはないんじゃないでしょうか?
――ということを書いていたらこういう不思議ちゃんキャラのような設定にしとけばいいんでは? というご意見を頂いたのですが、これ、ボケ方にめっちゃセンスが要求される奴や……!
ちなみにこれ関連の話題としては、進撃の巨人のキャラクターの身長体重がある。 Wikipediaの記事には、一部出典不明だが以下の通り記載されている。
- エレン 身長170cm, 体重63kg
- ミカサ 身長170cm, 体重68kg
- リヴァイ 身長160cm, 体重65kg
彼らは極限まで脂肪を削ぎ落とされた筋肉質の鋼の肉体に尋常じゃない密度の骨を併せ持っているから体重が重いのだ、ということだそうで。(作者の諫山氏が格闘技ファンであることも影響していそう)
2020年10月5日追記。
マリーとか初期のアトリエではキャラプロフィールに体重設定があったのだけど、総じて「重い」という意見をよくもらった。これはみんな冒険者で筋肉質だからという理由でそうしていた。(僕がTRPG畑の人間だったからというのもあるけど)
- 吉池真一 (@yoppy_never) October 4, 2020
これを見て検索したら、冒険者でもあるマルローネは158cm・49kg、親友で病弱なシアは152cm・40kgという情報が出てきて、よく考えられてたんだなあと思ったというメモを残しておきます。
会社に所属しながら書いた技術記事の原稿料収入の確定申告 - Mar 17, 2015
この業界、会社に所属しながら実名あるいはペンネームで技術誌に記事を執筆しているという人はそれなりにいると思います。自分も株式会社クリアコードに所属しながらシス管系女子を連載させていただいております。そういう人が確定申告をするときの話を自分の経験に基づいて書いてみます。
そもそも確定申告ってなんなん?つう話なんですけど、給与所得を得ている人間にとっては基本的に、収入源が会社の収入だけだし、年末調整の時期が近づくと「保険の支払いの書類とかもってきてやー」とアナウンスされてそれを持ってって会社に提出すると事務の方がイイ感じに計算して諸々処理してくれるので、あんまり関係ない話のような気がしています。問題は、そういう風に会社が把握してくれてない部分でお金の出入りがあった場合についてです。冒頭に書いたような技術記事を個人で書いている人間の場合、給与所得とは別に収入があるということになるので、その分の所得税やら何やらを納めないといけないのです。そこで出てくるのが確定申告。
聞いた所によると、給与所得以外で年間20万円以上の収入があると確定申告せんといかんのだそうです。僕の場合は原稿料×ページ数の額が20万円を超えていたので、しないといけなかったのですが、ちゃんと理解してなくて今までスルーしてしまっていました。が、このままではいかんと思ってちゃんとやることにしました。ほったらかしにしてると追徴課税とかシャレにならないことになるかもと思うと怖かったからというのもあります。それに、「シス管系女子」連載がついに本として発売されました、なんて大手を振って宣伝し始めたら、「おうおうおめえさんずいぶん羽振りいいみてえじゃねえか? 所得隠してんじゃねえのか? あぁん?」なんて厳しく追及されるんじゃないか、みたいな。
具体的なやり方についてなんですが、世の中には確定申告について解説した本が山ほどありますし、税務署に行って「確定申告したいんですけど……」と言ったら懇切丁寧に教えてもらえるので、そういうのでちゃんと調べるのがいいと思います(が、僕の場合は税務署に話だけ聞きに行ってもピンと来なくてまるっきり身に付かなかったのでした……)。僕は実際には、以下のような手順でやりました。
申告書の作成は以下の通り。
- 必要書類を揃える。
- 会社の源泉徴収票
- 原稿料の支払い調書
- 原稿作成に必要で購入した物のレシートとか領収証とか
- 国境なき医師団等、個人的にした寄付の領収証
- e-Taxのページを開いて、確定申告書の作成→初めて確定申告される方→「確定申告書作成コーナー」と辿って、「申告書・決算書・収支内訳書等 作成開始」というボタン状のリンクをクリック。
- 別ウィンドウ(タブ)で確定申告書作成のためのページが開かれる。提出方法の選択画面になるが、e-Taxを利用するにはICカードリーダー・ライターと電子署名のための証明書が必要になるので、そちらは何も手続きをしていないと利用できない。なので「書面提出」を選択する。
- 利用環境のチェックのページの次に、作成する申告書の種類を選ぶページが表示される。青色申告というのをやるには事前の申請が必要だけれどもそんな物はやっていないので、「平成N年分 所得税及び復興特別所得税の確定申告書を作成」というリンクをクリックする。
- 昨年よりも前の年の分の申告書を作る時は、下の方の「平成N年分の申告書等を作成する」というリンクを辿る。
- 「収入が給与1か所のみ(年末調整済み)の方」「左記に該当しない方」「質問に答えて作成」という3つの選択肢が表示されるので、「質問に答えて作成」を選択する。
- ウィザード形式で色々聞かれるので、情報を埋めていく。
- 最後に印刷用のPDFを保存する画面が出るので、PDFを保存・印刷する。また、入力中のデータを保存できるので、それも保存する。
- 3〜7を繰り返して、必要な年の分の申告書を全部作成する。
- できた書類を持って、税務署または確定申告に詳しい人に相談して、間違っている所を教えてもらう。
- 駄目出しを貰ったら、先の「確定申告書作成コーナー」で「作成再開」というリンクを辿って、7で保存したデータファイルを読み込ませる。するとウィザードの画面に戻るので、訂正箇所を直す。
- 7〜10を、不安がなくなるまで繰り返す(面倒なので1回で終わらせましょう……)。
ここでちょっと「源泉徴収」について説明しておく。原稿料を貰う時に、「1ページあたりいくらです」と言われた金額よりもちょっと少ない金額が振り込まれていて、送られてきた支払い調書を見たら「源泉徴収分としていくら引きました」みたいに書いてあると思うけど、これはどういうことなのかという話。
所得税は稼いだお金の額に応じて課されるんだけど、総額に対して何パーセントという形ではなくて、経費がいくらかかりましたとか、医療費にこれくらいかかりましたとか、控除分とされる金額をマイナスした額に対して課税される。でも、そういうのって1年が終わってみるまで結局いくらだったのか分からない。かといって、最後にまとめて税金を払いますということにすると、極端な話、税金を1円も払わないでバックレてしまえる。なのでそうならないように、雇用者や原稿料を支払う側があらかじめ何パーセント分かを仮の税金として引いて、先に税務署に納めておく、これが源泉徴収。その後、1年の最後の最後に諸々の収入や支出が確定した段階で改めて「本当に納めないといけなかった税金は一体いくらなんだ?」というのを計算する、これが年末調整とか確定申告とかの作業なんですね。
それで、源泉徴収されてた分が本来納めるべき税金より多すぎたなら差額が返ってくる(これがいわゆる還付金)し、逆に、本来納めるべき税金より少ない額しか源泉徴収されてなかったなら差額を払わないといけない。この分はその年の期限までに払えばその金額で済むけど、滞納してると、ほったらかせばほったらかすほど利子みたいなものが膨らんでしまう。そういう訳なので、皆さん毎年ちゃんと確定申告しといた方がいいですよ、という話になるのです。
申告書ができたら提出と所得税の納付です。これは以下の通りの手順でやりました。
- 印刷された物の中に資料の貼り付け用シートというのがあるので、給与所得の源泉徴収票と、寄付金の領収証を糊付けする。
- 副収入の支払い調書や、副収入の必要経費を証明する領収証・レシートは、ここには貼り付けないでいいです。これらは提出書類の要件には含まれません。ただし、確定申告書の提出後に税務署が「これ収入少なすぎ。これ経費使いすぎ。おかしい。脱税の恐れあり。」みたいに怪しんだら、申告書に書いた内容は本当に正しいですよという事を証明するためにこれらの書類が必要になってくるので、捨てないで取っておきましょう。
- 最寄りの税務署に行く。
- 税務署内に確定申告書の提出コーナーがあるので、書類を提出する。
- 形式的なチェックの後、提出分・控え分の両方にハンコをもらえたら、提出分はこの時点で回収されるので控え分だけ受け取る。
- 税務署内に所得税の納付コーナーがあるので、そこに行って「納付したいんですけど」と言って申告書の控えを見せる。
- 職員の方の指示に従ってお金を払って領収証を貰う。
書類の提出も所得税の納付も、郵送とか振り込みとか引き落としとかで済ませられるみたいなんですけど、僕は「ほんとにこれでええんか? ええのんか?」と不安が大きかったので、駄目だったらその場で指摘してもらえる税務署窓口での直接提出・直接納付にしました。
以上のようなやり方でやった結果、僕の場合は平成23年(2011年)は所得税の納税の必要ありでだいたい1割くらいの延滞料込みの納税、平成24年(2012年)は納税も還付も無し、平成25年(2013年)はぶっ壊れた作業用PCの新調やらCintiq Companion Hybridの導入やらで必要経費が多かったので還付、平成26年(2014年)は納税の必要ありだけど割り増し無しの額面通り、という感じでした。
とりあえず、分からないことは税務署の人に聞けば教えてもらえるので、確定申告がどうこうと世の中が忙しくなってる時以外の時期に、税務署まで足を運んでみるといいと思います。税務署怖くないよ。バックレるつもりの無い真面目な納税者には優しいよ。
シス管系女子で取り扱っている解説の妥当性、危険性について - Mar 15, 2015
シス管系女子(正確には「#!シス管系女子 Season3」)の現在発売されている号の日経Linux 2015年4月号掲載分について、hostnameコマンドは与えられた引数でホスト名を設定する物なので、ホスト名を取得するためだけにhostnameコマンドを使うのは、誤操作で問題が起こり得るから危険だという指摘がありました。
別の話として、実際に指摘を見かけたことはまだ無かった気がしますが、過去の回でcrontab -eを紹介するにあたって色々調べ直していた時に、crontab -eは、確認なしでの削除であるcrontab -rとミスタイプしやすいから使ってはいけないという話も見かけました。
どちらの事例も、「その機能が正常に使われている限りにおいては問題ないが、ヒューマンエラーが発生した時のリスクが大きいので、そもそもその機能を使うべきではない」という、安全側に倒した考え方であるように自分は受け取りました。運用という側面から「シス管」を考えた場合には、尤もな指摘だと言えると思います。
hostnameについては、なぜ$HOSTNAMEを参照するようにしなかったのかというと、以下のような所が理由となります。
- 自分がその方法で覚えてしまっていた。
- ホスト名を変えるために
hostnameコマンドを使う、ということが普段無いために、そのリスクに無頓着だった。(hostnameコマンドによるホスト名再設定は、再起動したら状態が戻ってしまうことから「使えねー」「役に立たねー」と思ってしまい、それ以後存在自体をすっかり忘れ去ってしまっていた) - なんとなく、環境変数の値は誰かが書き換えうるものという認識があり、コマンドの出力を見た方が安定した結果を得られそうに思った。(環境変数でもコマンドの結果でも同じ情報が得られるのであれば、コマンドの方を使うほうが安心、という認識がある)
crontab -eについては、「そんなん間違えへんやろ」と思っている部分が正直大きいです。が、自分がそう言えるのはcrontab -eというコマンド列を日常的に頻繁に利用するわけではないからかもしれないとも思っています。入力する回数が多いとcrontab -rというtypoの出現頻度が現実に問題となり得るレベルにまで高くなってくるものなのだ、と考えると、管理運用を業務とする人ほど敏感になるというのはありうるかも、と思います。
自分がこの連載で紹介する内容を考える時の判断基準としては、
- オプションの指定が不要なやり方と必要なやり方の両方があって、結果が同じなのであれば、オプションの指定が不要なやり方の方を紹介する。
- 簡単なやり方と難しいやり方の両方があって、結果が同じなのであれば、簡単なやり方の方を紹介する。
- 設定が不要なやり方と設定が必要なやり方の両方があって、結果が同じなのであれば、設定が不要なやり方の方を紹介する。(screenではなくtmuxを紹介したのはこれが最大の理由です)
- 確実なやり方と不確実なやり方の両方があって、結果が同じなのであれば、確実なやり方の方を紹介する。
- 安全なやり方とリスキーなやり方の両方があって、結果が同じなのであれば、安全なやり方の方を紹介する。
といったいくつかの基準があるのですが、「簡単だけど危険」「安全だけど難しい」のように判断が難しい時にどうするかというのは悩み所です。自分の中で決着が付かなければそもそもその話題は紹介せずに置いておくということもあります。が、多くの場合はcrontab -eのように、リスクを過小評価して利便性の方に舵を切ってしまいがちな気はしています。
ただ、可能な限り「簡単で、設定いらずで、確実で、安全で」という風に懸念点の少ないやり方を紹介していきたいという思いはあります。連載時の内容についての指摘は再録のタイミングで直せるので、全面的な改稿となると無理ですけども、セリフ回しや1コマの描き直し程度で乗り切れそうないい改善提案がもしあれば、Twitterアカウントへのリプライ等で情報を提供していただけると嬉しいです。
- 今の所、Season2でやったSSHの公開鍵の登録について
ssh-copy-idを使ったほうがラクという指摘は頂いており、これは何かの機会に反映したいと思っています。 - このエントリに書いている
hostnameの事については、既にuname -nやhostname -sなどの別案を頂いていますが、hostnameコマンド一発で済ませられるやり方に比べると若干面倒さが増す感があるので、「まんがでわかるLinux シス管系女子」での追加コンテンツのような形で「より安全にやりたいならこういうやり方もある」という補足情報を載せる方向で行くのがいいかなあ、と思っています。
総じて、この連載については「初級者レベルの人がちょっとステップアップする」「文字の説明だけ見ても分かりにくい事を、ビジュアライズして説明する」という所にテーマを設定しているので、安全性最重視の解説にはしにくいと思っており、そこの所は本誌の他の記事の方々に期待しております(丸投げ)。
シス管系女子の刊行物の関係まとめ - Mar 07, 2015
「シス管系女子」関係の刊行物が色々あって状況がカオスなので、図でまとめてみました。
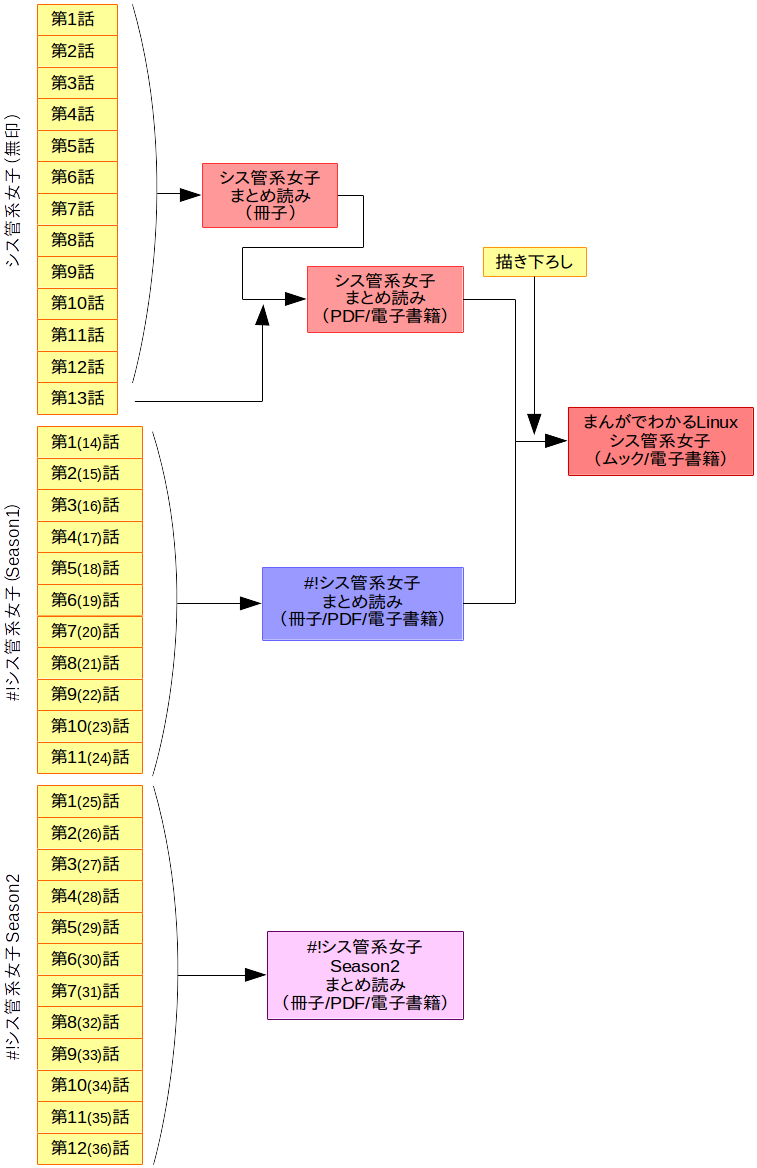
「まとめ読み」は、日経Linux本誌の付録としてだいたい年に1回ペースで制作されている物です。「まんがでわかるLinux シス管系女子」は、「シス管系女子」第1話から第13話、「#!シス管系女子」第1話(通算第14話)から第11話(通算24話)に加えて描き下ろしを収録した物となっており、作者の主観的にはこれが「初の単行本」という認識です。
各話は「まとめ読み」に再録する段階で一部修正していて、「まんがでわかるLinux」再録の段階でもまた修正しています。そこにさらに描き下ろしが加わっているので、今お買い求め頂ける物ではまんがでわかるLinux シス管系女子が最も内容が充実していておすすめです。「#!シス管系女子 Season2」については、「まんがでわかるLinux」の売れ行きが良ければ、今連載中の「#!シス管系女子 Season3」と合わせてまた本になるんじゃないかなあ……と思います。