Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

Jetpackを読み解く - Nov 10, 2010
Developers Conferenceでの発表向けの内容に盛り込めそうにない話を書いていく。
話のテーマを決めるにあたって、とにかく最初は1つJetpack SDKでアドオンを書いてみようと思ったんですよ。
でも、「こう書くと動きますよ」って言われてもなんだか信じられなかったというか、どういう経路でどういう風にしてそのコードが読み込まれるのか分からなくて、スクリプトの書き方次第じゃ他のコードに悪影響を及ぼしたりすることもあるんじゃないのか?(prototoype.jsのObject汚染みたいな感じで)とか、名前空間の衝突は大丈夫なのか? とか、そういうどーでもいい所が気になって気になって、仕組みが分からないまま使うのは怖いと思った。何をやってよくて、何をやったら駄目なのか、というのが分からないのが怖かった。
その境目を見極めたくて、Jetpack自体の成り立ちを探ってみたのですよ。
特に謎だったのが、他のモジュールを読み込むrequire()。これが一体どこで処理されているのか。main.js(Jetpackでアドオンを作る時の主たる実装になるファイルの固定の名前)もどこかからrequire()されているのなら、require()の実装を見たら謎が解けるんじゃないかなーと思った。
- 核になるのは packages/jetpack-core/lib/securable-module.js の内容。Jetpackで頻出の
exportsやrequire()はここで定義されている。- コードを見ると、CommonJS風のやり方だけでなく、JataScriptコードモジュール形式の書き方(
EXPORTED_SYMBOLSを使うやり方)にも対応してるみたい。
- コードを見ると、CommonJS風のやり方だけでなく、JataScriptコードモジュール形式の書き方(
- コードを追っていくと、最終的に
Components.utils.evalInSandbox()が呼ばれていることが分かった。ライブラリのモジュールもmain.jsも全部これで実行される。- ということで、JavaScriptの名前空間の中での事に関してはどんな無茶をしても大丈夫そうという事が分かった。
- もうひとつ、packages/jetpack-core/lib/cuddlefish.js も重要っぽい。
- Jetpack自体の組み込みのライブラリでしょっちゅう使われてるユーティリティっぽいモジュールであるところの
require("chrome")の実態が、これ。 - Cuddlefish Labというアドオンの形で導入することもできるみたい?
- Labs/Jetpack/JEP/28に、詳しい事が書かれてる。
- Jetpack自体の組み込みのライブラリでしょっちゅう使われてるユーティリティっぽいモジュールであるところの
Jetpackとは、この基本的な仕組みに基づいて、個々のモジュールの名前空間を分け、それらを安全に連携できるようにしたもの。と言える。MozLabでmodule_manager.jsというものが過去に使われていて、それを想起させられた。
module_manager.jsはJavaScriptコードモジュールが無かった頃にJavaScriptそのものの言語仕様を超えた所で高度なモジュール化を行おうとしていたらしく、渡されたモジュールの名前からパスを生成してファイルを読み込んでサンドボックス内で実行してそのグローバルオブジェクトを保持し続けて……ということを普通のJavaScriptの機能とmozIJSSubScriptLoaderでやってた。Jetpackの仕組みはそれのずっとスマートなバージョンなのかなと思った。
今までの開発手法しか知らなくてJetpackがさっぱり分からないという僕みたいな時代後れの人でも、securable-module.jsとcuddlefish.jsを起点にすれば、他のモジュールも無理なく読んでいけるんじゃないだろうか。
Jetpackへのモヤモヤを全部吐き出そう - Nov 08, 2010
僕はJetpackに対していろんな意味で期待していたはずなのに、自分がJetpackでバリバリ開発する姿はいまいち想像できないでいる。Jetpackの話が出始めた頃よりも、JetpackがrebootされてSDKとなってからの方がむしろ、「あれ、なんか僕ってJetpack使ってなさそうなんじゃね?」感が強くなっていっている気がする。Jetpackは僕を幸せにしてくれるのか? くれないのか? それが分からない。
Firefox Developers Conferenceでの発表について「Jetpackからよりディープな世界へのステップアップや、あるいはその逆に、これまでの手法でアドオンを開発していた人達がJetpackにステップアップするには? という風な話題」というオーダーをもらって、ようやっと重い腰を上げてJetpack SDK(とPython)をインストールしてみた。で、とりあえずJetpackの流儀というのを理解しなきゃと思って実際にアドオンを書いてみようとしていきなり挫折して、ドキュメントを読んでみようとしたけどどこから読めばいいのかすら分からなくて頭クラクラで、ヤケクソでJetpack SDKそのもののコードを読んでみたりして、という事をやりながらモヤモヤと考えてた。何故僕はこんなにも、Jetpackに乗り切れていないのか。
現実的にはJetpackを使った方がいい・使わざるを得ないという状況になってきている
Jetpack SDKのドキュメントをちょっと読んで雰囲気を眺めただけでも、僕の今までの知識はまるで役に立たないということはよく分かった。
アドオンを構成するコードは、大雑把に言うと
- 「タブの上でダブルクリックしたらタブを閉じる」とか「twitterで新しいツイートがあったらポップアップを表示する」とかの、ユーザ視点での便利さの向上に繋がる機能のためのロジック。Railsでいうなら、generateで生成されるRailsアプリケーション。
- 「タブの上で行われたマウスの操作を拾って任意の関数を実行する」とか「ポーリングやソケット通信を使ってサーバから必要な情報を取ってくる」とか「自動的に消えるパネルをデスクトップ上にフェードイン・フェードアウトで表示させる」とかの、前項のロジックを実際のアプリケーションで実現するための基盤。RailsでいうならRailsというフレームワークそのものにあたる部分。
の2つのレイヤに分けることができる。
これまでのアドオン開発においては、2の部分の開発コストが非常に大きかった。W3CのDOMであるとかCSSであるとかのWeb標準の知識がベースにあるとはいっても、XULやXPCOMというMozilla specificな技術を覚えなければならないし、覚えた上で、さらに工夫しないといけない。はっきり言って、アドオンのコードのほとんどは2のための物で、1のためのコードなんてのはほんの一部分だけだったりする。2の部分をどうやって解決するかというのが問題の大部分を占めていて、ほとんどの人はおそらくその段階で挫折してしまって、本題である1の部分に取りかかる事すらできないのだと思う。
僕は、そこ(2のレイヤ)に膨大な時間を注ぎ込んできた。そこに時間を取られるせいでFirefox本体の開発に貢献とかそんなとこまで頭が回らないよ、というくらいの勢いで。その結果蓄積された大量のバッドノウハウこそが、今の僕の武器であり価値なんだと思う。
でも、そういうバッドノウハウはすぐに陳腐化する。また、せっかく覚えたXULやXPCOMの知識も無駄になる時がある。特に、Gecko 2.0からはすべてのインターフェースが凍結されなくなるということは、これからはnsIPrefBranch::getBoolPref()のような頻出のインターフェースすら安心して使えなくなるという事で、かかるコストと得られる物が全然釣り合わないんじゃないのか。
という事を考えると、「だからこそJetpackなんだよ」という話は理解できる。Jetpack SDKは、2の部分をアドオン開発者の代わりにカバーするライブラリ集でもある。Gecko 2.0以降のインターフェースの不安定さをJetpack SDKが吸収して隠蔽してくれるから、開発者は2の部分のためにかける労力が要らなくなって、全力を1の部分の開発に注げるようになる。という寸法だ。1と2の両方に(特に2の部分に異常に多くの)力を注がなくてはいけないロートルの開発者と、1のことだけ考えて開発していればいい新しい開発者、どっちの方が生産性が高くてクリエイティブな結果を沢山生み出せるか。あるいは、どっちの方が労力が少なく済んで、長くメンテナンスし続けられるか。そういう話だ。
その謳い文句、本当なの?
しかし、ホントにそんなにうまくいくのかな?
今でも、過去にFUELという「アドオン開発者向けの、Firefox組み込みのライブラリ」が作られて、それが「XULやXPCOMといった小難しい物を隠蔽すること」を目指していたはずなのに、仕様が十分に錬られてないわ利用者(アドオン開発者)にとっての使いやすさという視点が欠けてるわ実装もあまりにやっつけ仕事でヘビーな利用には全然耐えられないわ(普通に使うとメモリリークしまくる)で、あっという間に「ああ、そんな物もあったっけ……でも使ってる人いるの?」な位置に落ちぶれてしまった。搭載当初は何も特別な準備をしなくても使えるように作られてたのに、Firefox 4からは「コイツの初期化に時間かかるから、初期状態で使えるようにわざわざしておく必要ないよね」と「一級市民のAPI」の地位を追われてしまった。という事実がある。あの頃「FUELで状況はよくなるはずだよ!」という風な事を言って、紹介を書いたりして安易に勧めていた人達は、自分も含めて戦犯として裁かれなきゃいかんね。
そういう前例を見ると、Jetpackも、今は威勢のいいことを言っていても、これから先Firefoxの仕様が変わった時に、「JetpackのライブラリのAPIを維持してFirefoxの仕様変更を頑張って吸収する」方向ではなく「JetpackのライブラリのAPIを変えてFirefoxの仕様変更に合わせる」方向に流れてしまうんじゃないのか、「XULやXPCOMといったコロコロ変わる厄介なAPIの上に、Jetpackというこれまたコロコロ変わる新しい厄介なAPIが加わっただけ」になってしまうんじゃないだろうか、と僕は思ってしまうんだ。それじゃあただの第2のFUELだ。
そこで頑張って自分で貢献するんだよ、って言われても、そもそも前述の2の所の開発で悩まされる事から解放されるためのJetpackのはずなのに……って思うわけですよ。
APIが窮屈
また、Jetpack SDKの提供するAPIをキモく感じてしまった、というのもある。APIで提供される機能がどうこう以前に、API越しでしかFirefoxに触れないっていうことがストレスになった。
例えばタブのコンテンツ領域になってるフレームの生に近いAPIには、今までだったらgBrowser.mTabContainer.childNodes[n].linkedBrowser.docShellでアクセスできた。べつにフツーにフツーのアドオンを作るだけだったらそんなとこ触る必要ないけど、いざというときにはそういう低レベルのAPIから裏口を叩けば何とかなるという、なんていうんだろ、安心感? みたいな? そういうのがあった。
しかしJetpackではこれが隠蔽される。APIで用意された範囲の機能にしかアクセスできない。ということは、やりたいことができそうに無かった時、今までよりもずっと手前の時点で諦めなきゃいけないんじゃないかって気がして、今すぐそれをやりたいかどうか以前に、もう、それができなくなるってだけで息苦しくて窮屈で「うああああ嫌だ嫌だ嫌だ」となってしまう。
まだJetpackがrebootされるよりも前の頃、生のXUL要素に触れるrawというプロパティがあった事について、僕はそれを激しく非難した。そんなのがあったら将来的なAPIの互換性を保てなくなってしまうじゃないか、と。その認識は今でも変わっていない。しかし自分がいざ当事者になってみて初めて、その窮屈さ不自由さを身に染みて実感した。(僕がChromeの拡張機能に手を出そうとしなかったのは、これを本能的に避けていたからなのかもしれない。)
Web標準から離れていく?
そもそも自分がMozillaに肩入れしてるのは何でだったのか。よく考えてみるまでもなく何度も言ってるけど、プロダクトそのものがW3CのWeb標準の技術に基づいているから、そしてそれらの技術にちゃんと対応してたから、というのが一番最初にあった理由なんだよね。
「W3CのDOM? XML? CSS3? そんなの全然Webで使えないじゃん、IEで使えない物に意味なんてないよ。」
「W3Cの仕様なんて、現実見てない頭でっかちの奴らが決めたものだろ? 名前がやたら長ったらしい(例:document.getElementById(id)はIEのDOM0だとdocument.all.idに相当)し、キモすぎる。」
「デファクトスタンダード(事実上の標準仕様)こそがすべてだよ。デジュールスタンダード(標準はこれです、という形で作られた標準仕様)なんかに意味はないよ。」
そんなWeb標準冬の時代に、CSS2のポジショニングにも疑似要素にも疑似クラスにもかなりのレベルで対応してて、W3Cの仕様書にある通りの書き方でちゃんとレンダリングしてくれるGeckoは、実に素晴らしいものだと本気で思ったし、ブラウザのUI自体すらもW3Cの仕様通りのWeb標準技術をベースにして作られてると知った時にはもう、泣いて喜ぶ勢いでしたよ。
「ああ、世間であんなに冷遇されてるWeb標準が、ここにはちゃんと息づいてる!!」それが僕のMozillaとの関わりの始まりだった。僕にとってMozillaは、Web標準の象徴だった。W3C信者だった僕にとっては、魅上照ばりに「あなたが神か」てなもんでした。
でも気がついたら、RDFを使う部分はどんどん減らされて、MNGサポートもドロップして代わりにAPNGなんてMozilla独自の画像形式になってしまって、SOAPサポートもドロップして(だったよね?確か。)……そんな感じで「世間ではまだ広く使われてないけどWeb標準の技術に対応してる、だからまだマイナーなWeb標準の技術でも実際に動くアプリケーションを僕でも作って実証できる、Web標準はちゃんと役に立つんだって事を証明できる」と思ってた余地がどんどん減っていって。その一方で、「次のスタンダードはWebKitだ!」と「標準」のお株を奪われて、新しいWeb標準への準拠度で後れを取って、性能面でも引き離されちゃって。
さらにはユーザの側からも開発者の側からも「XULなんてクソ重い無駄なもんなくしちまえ」みたいな声が出てきて。Jetpackって、XPCOMが廃止されてもXULが廃止されても拡張機能向けのAPIの互換性を保てるようにっていうことで出てきたんだったと記憶してるんですけど、ということは、Jetpackが最高にうまくいったらXULもなくなっちゃうって事ですか? CSS3で外観を変えたり、XPathでUI要素をゴソッと収集したり、そういうのがなくなっちゃうって事ですか? みたいな。
切ないね……
だいたいさあ、安定したAPIになる保証もないのにオレオレAPIをどんどん重ねてくっていうのが気にくわんのですよ!! document.allとかlayersとか混沌として色々分断されてた世の中が、せっかくWeb標準のおかげで見通し良くなってまとまってきたと思ったのに! prototype.jsとかDojoとかMochikitとかjQueryとかYUIとかExtJSとかオレオレな実装が乱立してきてさあ!! なんなの!! もう!!! Web標準だけあればいいじゃん!!!! そんでもってUI用の言語として開発されたXULでいいじゃん!!!! なんでHTMLで無理矢理UI作ろうとするんだよ!!!!! XMLっていう仕組みがあるんだから、それに則った上で用途に適した道具を選ぼうよ!!!!! そういう事を考えもしないで、見慣れてるからってだけでdivだのspanだのでオレオレUI作ってさあ!!!!!!!! なんなんだよそれ!!!!!!!!!
はあ……
しかし光明もある
そんな感じで考えれば考えるほどダウンな気持ちになってきたんだけど、さらに調査を進めていく中で、Jetpackの今のAPIの基礎になる部分はCommonJSの仕様に則る形で開発されているという事を知って、「おおっ!?」と思った。
僕がJetpackの前のAPIでとても「うへぇ」ってなってたのは、ライブラリの読み込み方の部分だった。Greasemonkey等で広く使われてたDocComment風の記法じゃない、jetpack.future.XXXとかのアクセス方法、あれがすごい気持ち悪かった。なんでここでまた無駄にオレオレルールを増やすかなあ!? と思って色々萎えた記憶がある。
でも今のJetpackでは、ライブラリを呼ぶ時はrequre('ライブラリ名')、ライブラリを作る時はexports.プロパティ名に値や関数をセットするというルールになっていた。これは、サーバサイドでJavaScriptを実行するnode.js等の環境でAPIを共通化しようということで議論が進められている、CommonJSのルールだ(そうだ)。これは、Webの開発者にとって親しみやすい物にしよう、独自拡張オレオレルールでなんでもやるんじゃなくて足並み合わせる所はきちんと合わせていこうという意図の顕れだと、僕には思えた。MNGとAPNGの件では見損なったけど、この件では見直した。
あと、Mozillaの中の構造とか全然知らない人にペアプログラミング形式で「ちょっとしたアドオンを作ってみましょうか」とJetpackベースでのやり方を指南(?)しようとして、ああやっぱりこのアプローチは間違ってないんだなということを実感した。
- 使えるAPIの数が限られてるから、「どのやり方でやるべきか、どの方法を教えるべきか」で迷わないで、「この目的を達成するならこのAPIでやろう(っていうかそれ以外の方法がない)」とサクサク進める。
- 実際に書くコードの量は少なくなるから、見通しが良くなる。
- SDKにFirefoxのテスト実行モードがあるから、トライ&エラーで開発できる。「あれー、ダメだった。なんでだ? じゃあここをこうしてみるか」ですぐやり直せるし、「よし、まずはここまでできた。OK? じゃあ次のステップに進もう」という風にちょっとずつ教えられる。
- 今回は使わなかったけど、自動テストのための仕組みもSDKに含まれてる。
初学者とかWebデベロッパーとか、Mozillaヲタじゃなくてもアドオンを作りやすくなってると思う。Pythonをインストールしなきゃならんとかコマンドラインでやらなきゃならんとかの点は、これからどうにでもなることだ。今まで取りこぼされていた人達をすくい上げる基礎になる物が、今のJetpackには確かに揃いつつあるのだと思う。今までの「動的に適用されるパッチ」でしかなかったアドオンの路線のままでは絶対になし得なかったことが、Jetpackでなら確かに可能になるのだと思う。
どう見ても老害です
しかしまあ、改めて考えると、僕がやっていた事も先人から見れば十分「なんだあの窮屈な世界は」てなもんなんだろうね。C++の生の実装に触ることなくその上に幾層にも積み上げられた物の上で僕はずっと遊んできたわけだけれども、その世界での制限には目を向けることもなく、全てを所与の物として受け入れてありがたがっていた。そんな僕が、GreasemonkeyやGoogle Chromeの拡張機能やJetpackに対して「なんだあの窮屈な世界は」なんて言うのはまったく笑い話でしかないのだろう。
下の層に目を向ければ、ハードウェア寄りのレイヤではそれこそ鬼のような非互換の嵐で、それを吸収するためのOSのレイヤがあって。上の層に目を向ければ、プラットフォームどころかデバイスの違いすら吸収するWebがあって。その中間層であるところのブラウザを作る段階で、プラットフォーム間の互換性がどうだのバージョン間の互換性がああだの言ってるのは、ちゃんちゃらおかしい。
そういう中途半端な所に(Web製作の世界から)逃げ延びて住み着いていた僕が、上の層から僕の居場所をなくそうと迫ってくるJetpackに恐怖を抱いて、拒絶反応を示していた。版図を広げようとしている若手の前で竹槍を振り回してた。ああ、実に老害だ……
それに、Web標準Web標準とわめいてみても、WebKitが中心になってしまった今のWebじゃあGeckoの方がはるかにオレオレ実装なはぐれ者だしおまけに10年以上前のコードを引きずってる骨董品だし、XULもXBLもXMLという仕組みの上に成り立っているとはいってもそれ自体はみんなの合意が得られた標準仕様じゃないわけだし。「神!私は仰せの通りに!」と崇めてるうちに、僕はWeb標準とMozillaのオレオレの見境が付かなくなってたのか……
まとめ
とりとめがないままにモヤモヤした物を吐き出してきたわけだけれども、それと平行してJetpackの内側を覗いてみたりして、光明も見えたりして、自分の勘違いも見えてきて、いくらかスッキリした気はする。
あと、最近は人生っていいものかもしれないなあと思うようになってきたので、老害と言われようともそれでも往生際悪く地味に追いすがっていこうと思ってます。オメガギーク!
XBLの使用を避けたがるのは何故か - Oct 22, 2010
僕がアドオン開発でXBLの利用を避けることが多いのは、XBLを使ってると、他のアドオンやサードパーティ製のテーマと衝突した時ににっちもさっちもいかなくなってしまうことが多かった(という印象が強い)り、複数のバージョンのFirefoxに対応しようと思うとドツボにハマったりしたからだ。
例えばツリー型タブのようなアドオンを作る時に、「タブのDOMノードに、子タブの一覧を取得するためのchildTabsというプロパティを追加したいな」と思ったとする。思ったっていうか、タブブラウザ拡張でかつてツリー表示機能を実装した時には実際そうしてたんだけど。それをXBLでやるとこんな風になるだろう。
<binding id="tabbrowser-tab"
extends="chrome://browser/content/tabbrowser.xml#tabbrowser-tab">
<implementation>
<property name="childTabs" readonly="true">
<getter><![CDATA[
...
]]></getter>
</property>
</implementation>
</binding>
同時に、こういうCSSも書くことになる。
.tabbrowser-tab {
-moz-binding: url("mybinding.xml#tabbrowser-tab");
}
XBLではextendsで他のバインディング定義を継承することができる。chrome://browser/content/tabbrowser.xml というのは、Firefox 3.6でタブブラウズ関係の機能を定義してるバインディングなので、これで「Firefox本来のタブの機能に加えて新しい機能を定義する」という事が簡単にできる。
が、これは同時に欠点でもある。XULの機能のかなりの部分はXBLで定義されているので、extendsを書き忘れるとマトモに動かなくなってしまうことが結構ある。だから、独自のバインディングを適用する時は、適用先の要素に既にバインディングが適用されているかどうかを調べて、現在適用されているバインディングのURIを独自のバインディングのextendsに書いておかないといけない。
そして、「元々適用されているバインディングのURI」は簡単には同定できない。Firefoxのバージョンによっても変わるし、WindowsかMac OS Xかによっても変わるし、サードパーティ製のテーマでバインディングが上書きされているかもしれないし、アドオンがバインディングを適用しているかもしれない。ひょっとしたらユーザがuserChrome.cssでバインディングの指定を変えているかもしれない。継承の順番は、自分のXBL→tabbrowser.xml→tabbox.xml→general.xml かもしれないし、自分のXBL→テーマのXBL→tabbrowser.xml→tabbox.xml→general.xml かもしれないし、自分のXBL→他のアドオンのXBL→テーマのXBL→tabbrowser.xml→tabbox.xml→general.xml かもしれない。「こう書いておけば大丈夫」という単一の継承元のURIは存在しないのだ。
さらにタチが悪いことに、XBLの定義ファイルの中に書かれたextendsは動的には書き換えられない。現在適用されているバインディングのURIをgetComputedStyle()で取得しても、それを後からXBLのextendsに指定するという事はできない。(ひょっとしたらdata: URLを使えばできるかもしれないけど、僕はそんなのやりたくないし見たくもない……)
だから、XBLを使うアドオン同士ではバインディングの優先権の取り合いになる。CSSは後から読み込まれたもの・セレクタの指定の詳細度が高いものほど優先的に適用されるから、後からインストールしたアドオンのせいでそれまで使っていたアドオンのバインディングが適用されなくなる、なんてこともしょっちゅうあった。タブブラウザのタブ要素なんて、激戦区中の激戦区と言っていいだろう。
そう考えると、ほんの2~3個のプロパティだとかメソッドだとかを追加するためだけにこれだけのリスクを負うのは到底割に合わない。それだったら、要素のDOMノードに直接プロパティを加えるのを諦めて、コントローラやサービスになるようなクラスを作ってそっちに必要な処理を集約させる方がずっと楽だ。(だからツリー型タブでは、前述の例のようなバインディングを使う代わりに、gBrowser.treeStyleTab.getChildTabs(aTab)で子タブの配列を得るように設計した。)
というのが、僕の出した結論だった。
そういう話なので、僕は、「何が何でもXBLを使うな」とまで言うつもりはない。前述のようなバインディングの適用の優先権争いが起こらない場所、例えば独自のXULRunnerアプリケーションだったり、独自のサイドバーパネルだったり……という部分でなら、XBLはいくらでも使っていいと思ってる。
例えば、派生の要素型がたくさんあるようなケースではXBLの継承が威力を発揮する。会社で一時期やってたXULRunnerアプリのプロジェクトでは、継承を多用することで結構工数を削減できた(と思う)。また、anonymous contentsの追加は(特に、既に存在しているDOMツリーのノードの親子関係の間に安全に割り込むような物は)、XBLでなければできないことだ。
ただ、XBLは、1つのウィンドウの中にいろんな人が好き勝手に書いたコードが同居する「Firefoxのアドオン」という分野とは、すこぶる相性が悪い。JavaScriptで書く物でもCSSで書く物でも「最初にやった者勝ち」な所はどこかしらあるけれども、XBLの場合はそれが顕著だし、「後から来た者が上手く隙間に入り込む」という風な余地が全然無い。だから僕は、XBLをなるべく避ける形でコードを書くように努めてるんだな。
未だにXBLを使うことを避けられない場面 - Oct 22, 2010
XBLはアドオン同士の衝突の原因になりやすい。だからXBLはあまり使わないように僕はしてる。
XBLを使うと、DOMノードにgetterやsetterになってるプロパティを定義したり、独自のメソッドを追加したりできる。でも、それらはJavaScriptのテクニックで代用できないこともない。JavaScriptのレベルで目的を達成するやり方として、僕は最近よく、こんな設計をしてる。
function MyController(aNode) {
this._node = aNode;
this.init();
}
MyController.prototype = {
get property() {
...
},
set property(aVaule) {
...
},
method : function() {
...
},
init : function() {
this._node.addEventListener('...', this, false);
...
},
destroy : function() {
this._node.removeEventListener('...', this, false);
...
},
handleEvent : function(aEvent) {
...
}
};
var node = document.createElement('box');
node.controller = new MyController(node);
かなりの部分はこういったやり方で目的を達成できると思う。ツリー型タブなんかもこれに近い実装になってる。
ただ、オートコンプリートのテキストボックスの挙動を変えるだとかの、本体で定義されている物を置き換える場面では、たまにこの方法だけでは不十分なことがある。例えば<textbox type="autocomplete" />な要素のmaxDropMarkerRowsや<panel type="autocomplete" />な要素のoverrideValueやなんかはreadonlyなプロパティとしてXBLで定義されてしまっているので、これらが返す値を変えたいと思うと結構厄介な事になる。
XBLを使わないでサクッと済ませようとすると、__defineGetter__()を使う方法がまずは思い浮かぶ。Firefox 3.0以降ではDOMノードに対して__defineGetter__()を使えるので、上記の例のコードのinit()あたりでそれを使ってやるという感じだ。実際、XUL/MigemoではoverrideValueで任意の値を返すためにそうしてる。
でも、この方法はできれば使わない方がいいのかもなと思ってる。そう思ったきっかけは、同じようなことをやるコードの自動テストを書いていた時。setUpとtearDownで毎回ウィンドウを開いたり閉じたりとやってると時間がかかってしょうがないからUxU組み込みのフレームにページを読み込ませて……という風にしてみたら、セキュリティの制限に引っかかってしまった。object.__defineGetter__(name, getter)のobjectとgetterの属してる名前空間が違うと、Illegal valueとか言われてエラーになってしまった。それでTrunkでの__defineGetter__()の実装を見てみたら、この両者のコンパートメントが違う場合はゲッタの登録を拒否するような設計になってた。こういうセキュリティの制限を回避してreadonlyなプロパティの働きを置き換えようと思ったら、どうもやはり、XBLを使うしかないようだ。
そもそもなんでoverrideValueがreadonlyなんだよ、なんで書き換え可能なただのフィールドになってないんだよ、って思って来歴を調べてみたら、nsIAutoCompletePopupインターフェースのoverrideValueは昔のオートコンプリートの実装におけるgetOverrideValue()メソッドがその祖先で、当時のコードには「こいつの働きを変えたかったらXBLでオーバーライドしろ」ってコメントが書いてあった。今のFirefoxのオートコンプリートの実装にはこのコメントがなかったので、なんでreadonlyになってるんだよという不満しか抱きようがなかった。getXXXとなってたメソッドをプロパティの形に置き換えるなら、確かにそれはreadonlyになるだろう。
でもどうせプロパティに変えたんだったらwritableにしたってよかったはず。ほんとに、何でこんな設計にするんだろう……
拡張機能の標準化の話について思うこと - Oct 20, 2010
- Operaがついに拡張を採用--「Firefoxのように重くはならない」 - CNET Japan
- Opera「ブラウザの拡張の仕様を標準化して、使い回せるようにしませんか?」 - CNET Japan
- Opera「ブラウザの拡張の仕様を標準化して、使い回せるようにしませんか?」 - WebStudio
かつてIE6が一番先進的なブラウザだった頃は、ブラウザに機能を加える物といったら、「ツールバー」か「コンテキストメニューの追加項目」くらいしかなかった気がする。そもそも、「ブラウザにツールバーを追加できますよ」だけでもずいぶんすごいことであったような気がする。僕がそれ以外を知らなかっただけかも知れないけど。(具体的に僕が「その頃」の代表的なブラウザとして今思い浮かべているのはIE6とNetscape Communicator 4.xです。)
その頃は、MicrosoftとかNetscapeとかがリリースしてるメジャーなブラウザの使い勝手に不満があっても、プログラミングの知識がないフツーの人は、我慢するか、既にある別のブラウザ(iCabとかOperaとか)を探すかしか無かった。そもそもこの時代、ちょっと前までブラウザは4000円とか9000円とかお金払って「買う物」であったから、基本的には「買った物をそのまま使うか、買わないか」という選択肢しかなかったとも言える。
それでも、腕に覚えのある人なら、コアであるレンダリングエンジンにはIEの物を流用して、それ以外のブラウザのUI自体を頑張って全部作り直すということは可能だったようだ。それで出てきたのがDonutだったりSleipnirだったりLunascapeだったりのいわゆるIEコンポーネントブラウザだった。メジャーなブラウザがリリース計画とか顧客とか組織とか色んな都合で足踏みしている間に、個人の開発者あるいは小規模な開発チームであるが故のフットワークの軽さによって、凡庸なメジャー製品では手に入らなかった「痒い所に手が届く使い勝手の良さ」を提供したことで、それらIEコンポーネントブラウザはパワーユーザの支持を得るに至ったのだろう。
IEを使うのなら、できる「機能拡張」はせいぜいツールバーの追加かコンテキストメニューの機能追加くらい。なぜなら、IEが開発者向けに開いていた「ブラウザの個々に機能を追加できますよ」というポイントが限られていたから。(あるいは、もっと色々できたのかもしれないけど、それくらいしかできないという印象が強かった。)それ以上の物が欲しかったら、そういう機能を提供するIEコンポーネントブラウザに乗り換えるしかない。それが、あの頃に取り得た現実的な選択肢の全てだったのだと思う。
僕にとっては、そういう「暗黒時代」はMozillaとの出会いで終わった。当時はまだMozilla Suite(Seamonkey)がメインラインで、バージョンはM16とか0.6とか言われてた頃だったか。当初はCSS2に一番真っ当に対応してたブラウザだったからという理由で使い始めたけど、使い続ける理由はいつの間にか、「一番痒い所に手が届くから」になっていた。
Ben Goodger氏が当時を振り返って語ったエントリにもあるけれど、Mozillaの設計上の特性からくる「拡張性の高さ」はホントにぶっ飛んでた。
- タブを並べ替えるという機能がMozilla本体には無いのに、拡張機能によって、タブを並べ替えられるようにできた。
- セッションを保存するという機能がMozilla本体には無いのに、拡張機能によって、前回終了時の状態を丸ごと復元したり、1回閉じたタブを開き直したりという事を実現できた。
- 検索ボックスでキー入力が始まったタイミングで自動的に表示されるポップアップから、別の検索エンジンで検索を実行する、なんてことすら実現できた。
Mozilla以前は、
「標準のUIに不満がある? Googleサジェストが使える検索ボックスが欲しい? じゃあ、このツールバーを追加して下さい。ほら、このツールバーの中でならもっと快適に過ごせますよ! Googleサジェストの結果もポップアップされますよ! まあ、このツールバーの世界から一歩でも外に出ると、また今まで通りの世界に逆戻りですけどね。」
「え、このボタンだけ切り離してウィンドウの下の方に置いておきたい? そんなことできるわけないでしょ。この素敵な便利機能は、このツールバーの世界から外には持ち出せませないんですよ。」
「え、専用のツールバーなんかいらないから、本来のアドレスバーから色んな検索エンジンでWeb検索できるようにしてくれって? そりゃ無理ですよ。このツールバーの枠の中の事ならどうとでもできるけど、枠の外は元々作られてた通りにしか動かないんだもの。」
こうだった。ツールバーという細長い箱の中、コンテキストメニューというメニューの中、そういう様式の中でないと何もできなかったっぽかった。
あるいは、こうだった。
「このブラウザに乗り換えたら、こんな便利な機能が使えますよ!」
「え、こっちのブラウザのこの機能が欲しいって? そんなこと言われても、それは別のソフトだし……正直、そんなもん知らんがな。」
「パソコン盗まれてソースコードが失なわれちゃいました! もうメンテナンスできません!」
でもMozillaではそうじゃなかった。
「標準のUIに不満がある? じゃあ、そこをピンポイントで解決しちゃえばいいよ。」
「ボタンはウィンドウの上じゃなくて下の方にあって欲しい? じゃあそうすればいいよ。ほら、ツールバーのボタンをウィンドウの下に移動できるようになった。」
「アドレスバーから色んな検索エンジンで検索できるようにしたい? じゃあそうすればいいよ。ほら、GoogleやAmazonの検索結果がアドレスバーの履歴と一緒に表示されるようになった。」
こうだ。実にシンプルだった。「イラッ」と来たまさにその点を、イメージしていた通りに、一番ストレスのない形で解決できる。ツールバーという細長い四角い枠の中であるとか、たった1人の作者の都合であるとかに、囲い込まれなくてよかった。使いたい機能を使いたいように組み合わせて使えた。
具体的な例をもっと挙げると、例えば、ツリー型タブとマルチプルタブハンドラと情報化タブの併用みたいなことができるのかどうか、ってことなんですよ。
タブで開いてるページをツリー表示するポップアップを表示する拡張機能。うん、それは多分便利。
開いてるタブのリストを表示して、任意のアイテムを選択してまとめて操作するポップアップを表示する拡張機能。うん、それも多分便利。
開いてる全てのタブの内容をサムネイルで一覧表示するポップアップを表示する拡張機能。うん、それも多分便利。
で、それを1つにまとめて同時に使えるの? ツリー表示されていて、気が向いたらそれを複数個選択してまとめて閉じられて、それらには常時サムネイルが表示されてる、というソリューションは誰でも得られるの? エンドユーザでも? って事なんですよ。
「ツリー表示してサムネイルも表示して複数選択もできるUI、を提供する1つの拡張機能」があればいい? 「ツリー表示してサムネイルも表示して複数選択もできるUI、を持ったIEコンポーネントブラウザ」があればいい? そういう物がもしあるのならそれを使うのもいいだろうし、作れる能力があるのなら作って全然いいと思う。でも、そういう物が無かったらどうなのか? 誰も作っていなかったら? そして自分でそれを作る知識は無いというのなら?
また、3つの機能を持った物くらいならともかく、要求事項が4つ5つと増えていったらどうなるか。条件が増えれば増えるほど、既製品で要求を完全に満たす物は見つけにくくなるだろう。妥協が増えてくるだろう。その逆に、個々の要求事項を満たす物を集めてきてそれで1つの物として使えるのなら、何も我慢しなくて済む。
だから僕は、Firefoxを捨てられないんだ。「Operaならあれもできるよ、これもできるよ」って言われても、「Chromeなら爆速だよ」って言われても、「ほうほう、ではこのポップアップパネルの下の端にこれこれこういうボタンを置いておきたいんだけど、そういうことはできるのかね? え、できない? ああそう……それじゃ日々の『イラッ』はなくならないなあ」と思ってしまうんだな。(だからFirefoxが好きなんですよ、っていうのが全く無いとは言い切れないけど、むしろ、他の物もそうだったらいいのに、でも残念ながらそうじゃないから諦めてFirefox使い続けるしかないのか、って思ってる所も結構ある。)
でも、時代は今また「用意された枠の中でならなんでもできますよ、でもそこからは一歩もはみ出せませんよ」の方向に戻ろうとしている。(いや、あの頃に比べたらずっと洗練されたAPIで、できることの幅も広がっているようなのだけれども。)何故なのか。
理由はたくさんあるようだけど、多分一番重要なのは、「みんな、そんなに自由でなくていい」って事なんだろうね。
頑固で融通の利かない馬鹿で順応性が低い僕にとっては、こうだ。「イラッと来たまさにその部分がピンポイントで解決されてくれないと、我慢ならない。ちょっとでも遠回りしないといけないのは、もう嫌。このツールバーの中でならそんな不満は起こりませんよ、なんて言われても、ツールバーなんていらんし。そんなん興味ない。今目の前にあるコイツがどうにかなってくれないと嫌なの。」でも、普通の人は僕なんかよりもっと頭が柔らかくて順応性が高いから、苦にならないんだろう。「こういうとこが不満で、なんとかして欲しいんだけど。え、代わりにこれを使わないといけないの? ふーん、まあ、いいけど。」で受け入れてしまえるのだろう。
(というか多分そもそも「こういうとこが不満で」なんて思わなくて、今ある物でだいたい満足できてしまうんだろう。思い入れも無ければ、一日中それと接するわけでもない、1日1回1時間くらいしかブラウザを操作しない、だからそんな深刻な不満を抱きようがないんじゃあないかな。頭が固いとか柔らかいとか以前に。)
(あと、これは、「普通の人」を揶揄する話ではない。そういう人達の方が環境の変化に柔軟に適応できる能力があるって事で、それは人として素晴らしいことだと僕は思う。こうやりたいと決めたやり方以外だとストレスを感じてしまうとか、そういうどうでもいいことにこだわってしまう性根というのは、人として問題があると思う。)
Jetpackがrebootされる前、まだJavaScriptのファイルいっこで完結してた頃、僕は「JetpackはGreasemonkeyやChromeの拡張機能とAPIのレベルで互換性を設けるべきだ」と強く思っていた。なので今回のOperaの「拡張機能を標準化しよう」っていう話に僕は賛成する。既に、ChromeとSafariの間では既にそういう状況になっていると聞いた気がする。大抵の人がそれで満足できる、ツールバーのボタンなり、Webページ内で自動実行されるスクリプトなり、そういう「どのブラウザでも共通して利用できそうな物」には、互換性があっていいと思う。僕だってひょっとしたら、ユーザになるかもしれないし。OperaやSafariをメインで使ってる人が作った拡張機能の恩恵に僕がFirefoxで与れる、そういうことがあり得るかも知れないし。
ただ、Firefoxと同じくらいになんでもできる環境になってくれない限りは、僕自身は軸足をChromeとかその後に出てくる物とかには移せないんじゃないかなー、と思ってる。些細な「イラッ」に目を瞑らずにストレートにそれを解消することができる、という居心地の良さに、僕はあまりにドップリと浸かりきってしまっているので。あまりに「自分を変えなくていい」事に慣れきってしまっているので。
Jetpack作った - Oct 11, 2010
今のFirefox用アドオンの開発にかかる手間を省いて、インストールやアンインストールの際にFirefoxを再起動しなくても済むようにする、Firefox 4向けの新しいアドオンの仕組みであるところのJetpack。
 最初はGreasemonkeyとuserChrome.jsの合いの子みたいな感じでスタートしてたみたいですが、いつの間にかRebootedになって、SDKを使って開発するという形の物に変わってしまっていました。Rebootedになってからの情報はGomitaさんが色々と記事を書いて下さっています。
最初はGreasemonkeyとuserChrome.jsの合いの子みたいな感じでスタートしてたみたいですが、いつの間にかRebootedになって、SDKを使って開発するという形の物に変わってしまっていました。Rebootedになってからの情報はGomitaさんが色々と記事を書いて下さっています。
Rebooted前に僕もちょっとだけJetpack用にテキストリンクやクリップボード監視を書き直してみたりしたんですが、Rebootedになってからは全くフォローできていませんでした。
で、この度改めてちょっと本腰入れてJetpack作ってみようと思ったんです。
はい、できました。

うん。どこから見てもJetpack。

SDKベースになっても作るのは簡単でした。Jetpack素晴らしいですね。
そういうわけでリアルJetpackです。制作期間は大体1.5週間くらいでしょうか。夏コミの時にふぉくす子コスで手伝ってもらったhknさんがはやぶさで有名な秋の『』さんに会場で偶然遭遇したそうで、背負い物イイナー!ということで面白そうだから冬までには作ってみようと思っていたのですが、去る10月10日に開催された痛Gふぇすた2010にふぉくす子の参加要請があったため、それに合わせて突貫作業で作ってみました。
芯にペットボトルを使い、先端部分とノズル周りと背負うためのベルトさえ作れば簡単にできるんじゃね? と思ってやってみたんですが、リアル工作なんてものすげー久しぶりだったので少々苦労しました。ちゃんとした設計図を作らないまま現物合わせで切ったり貼ったりしたのであちこち微妙に歪んでいますが、遠目に見たら分からないので気にしないことにします。
制作は先端部分から取りかかりました。芯にしたのはペプシコーラのペットボトルで、口をノズル側にした(今回はやらないけど、いつかチャンスがあったらペットボトルロケット的なギミックを仕込んだバージョンを作る事を想定して、そのようにしています)ので先端側にはペットボトルの尻が来たわけですが、5角形というか星形というかそういう変な形をした尻だったので、先端の断面の形に切った厚紙5枚を組み合わせてガムテープでぐるぐる巻にして大まかな形を作った後、普通の紙粘土で覆って表面を丸っこくしました。

乾燥させて紙ヤスリで表面をなめらかにして色を塗ればそれで十分かなーと思ってたんですが、この紙粘土が乾燥してもメチャメチャ脆くて、塗装中も段ボールに先っぽをぶつけただけでボロッと崩れるとか、掃除機で表面の削りカスを吸い取ろうとしたら芯への食いつきが悪いせいで端の方からベリッとはがれるとか、こいつのせいで手間がだいぶ増した気がします。とにかくこんなに脆いんじゃそのまま使うとヤバイと思ったので、塗装した後で透明ニスを何回も重ね塗りして補強しておきました。ニスを塗る工程は当初は想定してませんでしたが、小さい頃に紙粘土工作をした後に必ずニスを塗らされたのはこういう事だったのだなあと、今更になって当時やった事の意味をを思い知らされました。
あと、形を出した後で思い出しましたが、確かハンズにこういう形の発泡スチロールの塊が売られていた気がしますので、最初からそれを使えばよかったなあと後悔しました。紙粘土は表面だけに使ったといっても、大きさが大きさだったので結局ここだけで500グラム以上になってたみたいですし。軽く作る工夫は大事です。
胴体は元のデザインにあるスリットを開けておいたボール紙をペットボトルに巻き付けただけです。

ノズル部分は、戦闘機のベクタードスラストノズルみたいなデザインだと思い込んでいたためにその前提でプランを考えていたのですが、胴体のスリットを開口するために元のデザインを確認したら、全然違ってました。でも先すぼまりな形を継ぎ目無しに作るのはボール紙じゃキツいわと思ったので、元デザイン無視でやはりベクタードスラストっぽいデザインを意識した物にしてみました(配色もそれを意識してます)。
 あと、先端を紙粘土にしたことによってすごいトップヘビーになってしまったので、バランスを取るために、外からは見えませんがペットボトルの口の周りに紙粘土を重りとして巻いてあります。これで結局、全体で1kg以上はある感じの重たい装備になってしまいました。
あと、先端を紙粘土にしたことによってすごいトップヘビーになってしまったので、バランスを取るために、外からは見えませんがペットボトルの口の周りに紙粘土を重りとして巻いてあります。これで結局、全体で1kg以上はある感じの重たい装備になってしまいました。
胴体のボール紙の継ぎ目とか先端と胴体の間の所とかをごまかすために細切りのボール紙を巻いて、隙間をホットボンドで埋め、形としては完成しました。
着色は、スプレーで先端とノズルに色を付けた後、先端とノズルをマスキングして胴体のシルバーをスプレーで塗るつもりだったのですが、前述した通り紙粘土部分がメチャメチャ脆くて、これじゃマスキングテープで確実に表面がボロボロはがれるわと思ったので、先に先端(とノズル)だけニスでコーティングすることにしました。2時間以上乾燥→重ね塗り、で2~3重に塗ったので、結構頑丈になったと思います。あと、塗装は缶スプレーだけでいいかなと思ってましたが、実際やってみると赤色は結構下地のアラが目立ってしまいましたので、先にサーフェイサーで灰色一色にしてから赤や茶色を塗りました。胴体は、銀色の隠蔽力の高さに期待して特にそういう事はせず、ボール紙に銀色のスプレーを吹いてニスを塗っただけです。ニスが乾いた後で、ノズルがテカテカ光ってるのは変かなーと思ったので、最後に胴体をマスキングしてノズルの部分だけつや消しクリアーを吹いてあります。
左右の胴体の連結やベルトの固定方法については、当初は何も考えていなかったのですが、いい材料はないかと思ってホームセンターの商品を眺めていたら簡単に曲げられそうな穴あきの金属の板があったので、それを曲げて形を作って左右の部品をネジ留めしてからタッピングビスで胴体に固定することにしました。

ベルトは100円ショップで買った物を適当に切って使ってます。しかし実際に背負ってみるとベルトが肩に食い込んで痛かったので、そのうちクッション材(カバンの肩紐にあるようなやつ)を付けたいとは思っています。
表面がガタガタであまり見れたものではありませんが、大きな写真をFlickrに置いてあります。ふぉくす子が背負っている様子の写真はもえじらブログの方にあります。
Firefox 4: jar jar jar - Oct 06, 2010
この間悩まされたばかりのomnijarの話である、Taras’ Blog » Blog Archive » Firefox 4: jar jar jarの勝手翻訳です。分からない所が多かったので創作的意訳が多めですが気にしません。
ファイルを開く処理というものは、システムコールのための小さなオーバーヘッドや、ディスクからのデータの先読みによる大きなオーバーヘッドがある、比較的重たい処理です。データの物理的な配置の状態やディスクの種類によっては、この処理は今時の高速なCPUに対して、複数の異なるファイルそれぞれの全ての断片を先読みするためにディスク上をヘッドが激しく行き来する間、長々と無駄に暇をもてあまさせる事にもなり得ます。
最適化その1:裸のファイルをより少なくする
約2年前、私(訳注:元エントリの著者のTaras Glek)はディスク上にある裸のファイルを収集してjarファイルに詰め込む作業を始めました(例:bug 508421)。また、コードのクリーンアップやmmapへの移行などを通じて、私達はjarファイルの読み込み処理の効率も可能な限り改善しました。そして最終的には、通常の起動時にディスクから読み込まれていた、アプリケーションを構成するデータファイルの全てが、jarファイルの中に格納されるようになりました。しかし残念ながら、私達は4つのjarファイル(toolkit、chrome、そして2つのロケール用jarファイル)に構成ファイルをまとめる所までしか至れませんでした−−何ともマヌケな事ですけれども。またXPCOMの制限により、多数の裸のファイルがまだ、Firefoxのアップデートや拡張機能のインストールの度にディスクから読み込まれる状態となっていました。
最適化その2:全てを統べる1つのjarファイル
最近、Michael Wuがomnijarという<ruby><rb>滅茶苦茶にヤバい物を解き放ち</rb><rp>(</rp><rt>非常に影響範囲の大きな変更を導入し</rt><rp>)</rp></ruby>ました。これはAndroid用パッケージ作成での必要に迫られて行われた非常に大きな取り組みです。今や、アプリケーション起動時に必要なデータは常に単一のファイルから読み込まれるようになりました。これはデータの位置の集約化、ファイル走査の手間の短縮、そして待ち時間の短縮に繋がります。複数のファイルを1つに小さくまとめる事の1つの利点としては、OSがディスクからデータを読み込む際に、大抵の場合はアプリケーションが要求したよりも大きな単位で、投機的にディスクからデータを読み込む事も挙げられます。これにより、隣接するファイルの読み込みがより自由に行えるようになります。残念ながら、Firefoxを実際に実行せずにファイルアクセスの順番を予測するための良い方法がなかったため、ここにはさらなる改善の余地があります。
最適化その3:jarファイル内でのファイル配置の最適化
さて、今や全てのデータが1つのファイルの中に置かれましたので、論理的な次のステップは、それらをより賢く格納する事でした。それを行うための唯一の方法は、Firefoxの起動時の処理を分析して、jarファイル内のファイル配置をその結果に基づいて並べ替える事です。残念な事に、jarファイル内の全ての項目を連続的に配置するにあたって、私達はまだ次善の策を取っています。これは、ZIP(jarファイルの実態はZIPファイルです)のインデックスが伝統的にファイルの終端に配置されている事に依っています。Wikipediaの記事にこれを図示した物があります。
先読みの利点を最大限に活かし、ディスクの走査を最小限にするためには、格納されたファイルのインデックスがZIPファイルの先頭に置かれているのが望ましいです。そのため、私は私達のZIPファイル内のデータの配置を、
<項目1><項目2>…<項目N><インデックス><インデックスの終端>
から
<最初に読み込まれる、最後の項目の位置のオフセット値><インデックス><インデックスの終端><項目1><項目2>…<項目N><インデックスの終端>
に変更しました。
ここで私がやったのは、<インデックスの終端>のオフセット値を常に4になるようにした(どうでもいい事に拘るZIPアーカイバはインデックスのオフセットがNULLだとフリーズしてしまう事があるので、これは0にすることはできません)だけです。その際、インデックスは常に前のインデックスの終端に続けて配置されなければならないという仕様を満たすために、私は最初の物と全く同じ2つ目の<インデックスの終端>を加えました。また、私は、過度に用心深いZIPアーカイバによって強制された、どれだけのデータを最初に先読みしておく事ができるかを示す数値を格納するための追加の余白も利用する事にしました。
これによって、最適化されていないomnijarに比べてディスクI/Oの2〜3倍の削減を実現しました。これは裸のファイルをomnijarにすることで20〜100倍以上の高速化が実現できた事の最大の要因です。
私がZIPの仕様を読んでガッカリしたのは、ZIPアーカイバの中にはZIPファイルが仕様が許容しているよりもずっと厳格な形式になっている事を期待している物があるということです。以前のバージョンのFirefoxや、Microsoft WindowsのZIPサポート(訳注:圧縮フォルダ)、WinRAR、UNIXのZIPアーカイバなどは、私の最適化されたjarファイルを受け付けてくれますが、7-Zipや壊れたアンチウィルスソフト(スキャン対象を無闇矢鱈に限定する事はセキュリティ上危険です)はこれらを開く事ができません。
豆知識:これは、受け付けるZIPファイルの内容を選り好みするソフトウェアのせいで困らされた最初のケースではありません。例えば、Android標準のAPK読み込み処理は、Android用のパッケージが0バイトの大きさの項目を含んだZIPファイルである場合に、いちいちしつこくそれを警告してきます。これは、APK形式のファイルをWindowsにおける自己解凍形式のEXEファイルのように使う事ができないということです。Michael Wuはこの問題を解決するための独自の読み込み用ライブラリを書いている所です。
最適化その4:さらなるomnijar
omnijarは十分に素晴らしいとはまだ言えないということで、Michael Wuはさらに先に進んで拡張機能をomnijar化しました(訳注:アドオンがXPIのままで認識されるようになった事を述べたエントリ)。ほとんどの拡張機能はXPIから裸のファイルに展開される必要が無くなる事でしょう。これは、拡張機能の作者が上記のような最適化されたjar形式を、Firefoxの起動を高速化するために利用できるという事を意味します。
その他のjarファイルの最適化
起動処理の高速化用のキャッシュをjarに切り替える事によって、私達は最初の起動処理をさらに最適化できるようになることでしょう。私が最適化されたjarファイルに加えた先読み用の情報を実際に利用する事によって、jarファイルのI/Oを半減できる可能性もあります。
元記事に寄せられたコメント
Benによるコメント(2010-09-23 05:32pm)
2点だけ:
1つ目。あなたがどのように言おうと、これらの「最適化された」jarファイルはもはやZIPファイルではありません。仕様は非常に明確で、インデックスはファイルの末尾になくてはなりません。
あなたがやった事に間違った点はありませんが、しかし、それらのファイルをZIPであるかのように偽ろうとした上で、ZIPを扱うアプリケーションがそれらに対して文句を言わないようになる事を望むというのは、良い事ではありません。それよりもあなたは、最適化されたファイルの拡張子を変更することにして、最適化とその解除を手動で行うためのツールを提供した方がよいでしょう。
私は、例えば7-Zipは仕様に対して非常に厳格に設計されているがために、これらのファイル形式をサポートする事はあり得ないだろうと確信しています。
2つ目。私はFirefoxのコールドスタート(訳注:キャッシュ等にファイルが読み込まれていない状態からの起動)が(特に他のブラウザと比べて)遅いということを体感して、少し調べてみる事にしました。新規作成したプロファイルであってもまだ起動は遅かったです。私は、Firefoxは起動時に18個ものDLL(それらは全て、Firefox/Minefieldのインストール先ディレクトリに置かれています)を読み込んでいるという事に気がつきました。これは非常に良くない事で、ファイルの数の問題だけでなく、Windowsではセキュリティ対策ソフト(既定の状態であればWindows Defender、大抵の場合は何らかのアンチウィルスソフト)においての問題もあります。
私のマシン上では、ファイルのスキャンは1つあたりだいたい50ミリ秒を要していますが、この処理時間はファイルサイズには影響を受けません。Firefoxの場合、起動に数秒を要してしまいます。セキュリティ対策のソフトが大抵の場合は必要が生じた際の動的なスキャンの結果をキャッシュしていて、再起動されるか定義ファイルが更新されるまでの間は再スキャンが行われないために、この問題がウォームスタート(訳注:ファイルがキャッシュ等に読み込まれた状態からの起動)の場合には起こらないという事には注意して下さい。
いくつかの他のブラウザは、起動時にDLLを2つだけ読み込んでいて、他は必要が生じた時(動画の再生、WebGLを使う場合など)に動的に読み込んでいます。これはFirefoxの場合よりもずっといい具合に動作しているように思われます。
検索してみた所、私はLinuxについてのこの件に対するバグをいくつか見つけましたが、Windowsについてのバグは見つかりませんでした。それらが1つの大きなDLL(xul.dll)とそれ以外の小さなDLL(それらは無条件に読み込まれる)となっているので、全てを1つのファイルにまとめるのは理にかなっていると思います。
Taras Glekによるコメント(2010-09-24 09:06am)
Ben、あなたが注目した多数のDLLを提供している点についてはあなたの指摘は的を射ています。それについてのバグは https://bugzilla.mozilla.org/show_bug.cgi?id=561842 です。残念ながら、私達はこの作業をFirefox 4のリリースには間に合わせられませんので、後のリリース版で反映される事でしょう。
私はアンチウィルスソフトが起動時の処理に与える影響についても、より詳しい情報を得たいです。
omni.jarを展開してデバッグした話と、Minefield(Firefox 4)で起動時のセッション復元が働かなくなる問題について - Sep 27, 2010
最近のMinefieldのナイトリービルドで、ツリー型タブがあると前回終了時のセッションが復元されない(タブのタイトルだけ復元されて実際には空のページになる)という現象が起こっている。この問題の原因の究明のためにずいぶん遠回りをした。
- 最初は、SSTabRestoringやSSTabRestoredイベントを監視してる所が悪いのかと思った。なのでツリー型タブのイベントリスナの所をコメントアウトしてみた。しかしそれでもまだ問題が起こる。
- Minefieldの方が壊れてるのか?とも思ったけど、ツリー型タブを無効にしたら問題なくセッションが復元される。なのでどうもやはりツリー型タブが悪いみたい。
こういう時は、処理がどこで止まってしまっているのかを特定するのが僕が知ってる唯一の(そして多分一番ストレートな)原因調査の仕方だ。今回だったらセッション復元が止まってしまってるので、nsSessionStore.jsの中に沢山デバッグ用のdump()を埋め込んで、どこの時点でおかしくなっているのかを調べるという事になる。
が、Minefieldではそれが一筋縄ではいかなくなってた。
構成ファイルのほとんどを1つのアーカイブの中に入れてしまうというomni.jarという変更が反映されて、今までだったらcomponentsフォルダの中にそのまま置かれていたnsSessionStore.jsも、omni.jarの中に格納されている。なので上記のような調査法を取ろうとすると、omni.jarの中にあるファイルを書き換えないといけない。
ところが7-Zipではこのomni.jarを開くことができない。多くの場合、jarファイルはただのZIPアーカイブなので7-Zipのファイルマネージャで開いて中身を編集→再圧縮ということが簡単にできるんだけど、omni.jarの場合はアーカイブ自体が壊れていると判断されてしまって中身を見ることすら適わない。
検索してみたら同じようなことで悩んでる人が他にもいたみたいで、リンク先に書かれてる情報によるとExplzhを使えばomni.jarを開けるらしい。
ということで早速Explzhを入れてみた。Explzhでomni.jarを開いてみると、確かに中身を見ることができる。しかし、中にあるファイルを編集してエディタを終了すると、omni.jarの再圧縮に失敗してしまう。ファイル名を変えるとかファイルを1個だけ削除するとかするとなんとか編集後のファイルをアーカイブに含められたんだけど、その状態でMinefieldを起動すると、ファイルが部分的に読み込めなくなってウィンドウの背景が透明になってしまうとかの謎なトラブルが発生してしまった。Explzhでもomni.jarを部分的に変更しようとすると駄目みたいだ。
追記。Windows XP以降の「圧縮フォルダ」機能でもomni.jarを展開できるらしい。圧縮フォルダなんて微妙に不便だから使ってなかったのに、こんな所で役に立つとは……
まとめると、トラブルが起こらないようなomni.jarの編集方法は、こう。
- omni.jarを作業フォルダにExplzhで展開する。
- 必要な変更を行う(デバッグ用のコードを埋め込むなど)。
- 展開されたファイル群を7-Zip等でZIP形式で圧縮する。
- ファイル名をomni.jarに変更する。
- 4で作ったomni.jarで、Minefieldのomni.jarを置き換える。
- %localappdata%\Mozilla\Firefox\Profiles\プロファイル名\ の中にあるキャッシュファイルを消す。
この方法で、Minefieldが正常に起動する状態を保ちながらomni.jarの中にあるファイルに変更を加える事ができた。
nsSessionRestore.jsに大量のdump()を入れて調べてみた所、最初のタブ(現在のタブ)の復元が終わった後で次のタブを復元する時に、すぐに処理が終わってしまっていた。さらによく調べると、復元対象のタブを決定する時にもしタブのセッション情報の_tabStillLoadingというフラグがfalseになっていたら(=タブのセッションが復元完了していたら)、そのタブをセッションの復元対象から除外するという設計になっていた。
_tabStillLoadingというフラグには見覚えがあったのでツリー型タブのソースを検索し直してみたら、別のバグの対策でこのフラグを敢えてfalseにするような処理を入れていて、これが誤爆しているせいで上記の問題が起こっているようだった(本当はそのタブはまだセッションが復元されていない・読み込み中の状態なのに、_tabStillLoadingがfalseにセットされてしまうため、タブがセッション復元の対象から除外されるようになってしまっていた)。
まとめると、こういう事だった。
- Firefox 4 の最適セッションリストア(原文)で行われた変更で、ブラウザ起動時のセッション復元が、すべてのタブを一度に復元するのではなく、3個ずつ復元するように変更された。
- その時、まだ復元が完了していないタブがいつまでも「読み込み中」の状態に見えてしまうと格好が悪いので、タブの要素の
busy属性を取り除いて、一見すると既にタブの復元が完了しているかのように見せるようになった。その代わり、まだタブの復元が必要であることを示す_restoringというフラグをbrowser要素の方に立てるようになった。→Bug 602555でリファクタリングされて、また仕様が変わった。前述の「_restoringのフラグが立っている状態」に相当するのは「browser要素の__SS_restoreStateが1の時」になった。 - ツリー型タブは、タブの
busy属性だけを見て、そのタブが読み込み完了しているかどうか・セッション復元中かどうかを判断して、読み込みが完了していると判断したタブのセッション情報の_tabStillLoadingを強制的にfalseにして、タブの読み込みが完了しているとnsSessionStoreに認識させるようにしていた。 - そのため、Minefieldでは「一見すると読み込みが完了しているように見えるが、内部的にはまだセッション復元が完了しておらず読み込み中の状態である」タブまでもがツリー型タブによって「内部的にも読み込みが完了した状態である」という扱いになるようになってしまっていた。よって、タブのセッションが復元されないという現象が発生してしまっていた。
別のバグの対策用のコードの条件分岐にもうひとつ条件を足して、「一見すると読み込みが完了しているように見えるが、内部的にはまだセッション復元が完了しておらず読み込み中の状態である」というケースを判別するようにしたら、この問題は起こらなくなった。同じコードを他にもいくつかのアドオンで使っていたので、それらも合わせて修正しておくことにした。もし同じ事をやっている人が他にもいたら、十分気をつけて欲しい。
アドオンマネージャの歴史 - Sep 22, 2010
History of the Add-ons Managerのオレオレ翻訳です。誤訳がありそうですが気にしません。
Firefox 4用の新しいアドオンマネージャのために行ってきた作業を通じて、これは興味深い話題だろうと思ったので、Firefoxのアドオンマネージャについてのこれまでの歴史と今後についてざっとまとめてみました。
Phoenix 0.2
Firefoxの最初期のバージョンにおいても、拡張機能は古いXPInstall形式のパッケージの仕組みを用いてサポートされていました。拡張機能の削除や無効化のための仕組みがFirefox自体に含まれていなかったため、これらの初期のアドオンマネージャは根本的な部分でいくつか問題がありました。また、あなたが初めてアドオンをインストールした後に目にするような拡張機能マネージャのウィンドウもありませんでした。拡張機能とテーマの一覧がFirefoxに初めて追加されたのはバージョン0.2の時で、その頃はこの製品はPhoenixと呼ばれていました。それは非常に基本的なUIで、設定ウィンドウの中に表示されていました。
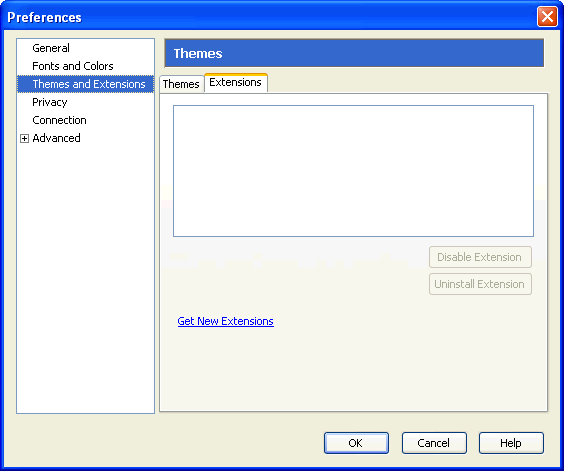 Phoenix 0.2の「拡張機能」(2002年)
Phoenix 0.2の「拡張機能」(2002年)Firebird 0.6
製品がFirebirdという新しい名前を得た後、拡張機能マネージャは設定ウィンドウ内の「テーマ」と「拡張機能」という個別のペインとして生まれ変わりました。
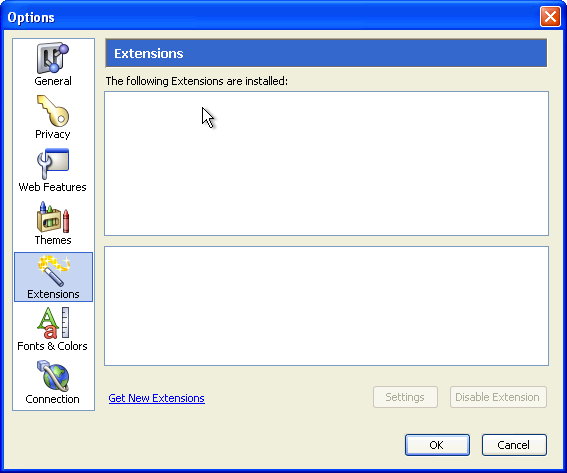 Firebird 0.6の「拡張機能」(2003年)
Firebird 0.6の「拡張機能」(2003年)Firefox 0.9
Firefox 0.9ですべてが変わりました。拡張機能マネージャは個別のウィンドウとなり、
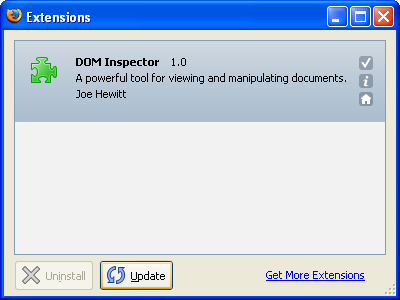 Firefox 0.9の拡張機能マネージャ(2004年)
Firefox 0.9の拡張機能マネージャ(2004年)テーマと拡張機能はそれぞれ別々のウィンドウで表示され、基本的な自動更新のための仕組みが搭載されました。これらはFirefox 1.0に向けたバックエンドのコードにおいて改良されることになっていました。この最初のバージョンは主にBen Goodgerによって書かれました。
Firefox 1.5
Firefox 1.5では拡張機能マネージャの表面的な部分について、ほんの少しだけ違いが見られます。このバージョンではFirefoxの他の部分の外観のスタイル付けに合わせるためにごくわずかな変更が行われました。
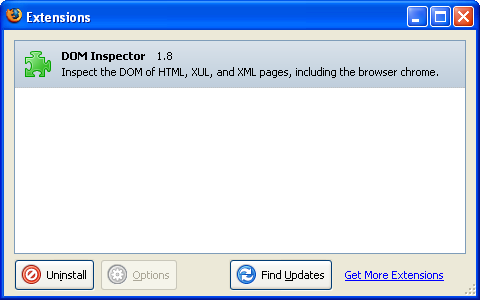 Firefox 1.5のスクリーンショット(2005年)
Firefox 1.5のスクリーンショット(2005年)この舞台裏で、Darin Fisherは大きな変更を行いました。彼は拡張機能マネージャに対して、Windowsのレジストリを含む、システム上の異なる場所から拡張機能を読み込むことを可能にしたのです。彼はまた、拡張機能をプロファイルフォルダ内に抽出することを可能にし、次にFirefoxが起動された時に自動的にそれらを認識できるようにもしました。この時、リリースに向けて拡張機能マネージャを安定させるために、Rob Strongがモジュールオーナーの権限を引き継ぎました。また、このバージョンには拡張機能マネージャに対する私(※訳註:原文の著者のDave Townsend氏)の最初のパッチも含まれています――bug 307925においての物で、ごく小さな物ですが。
Firefox 2.0
Firefox 2.0では最終的に、分割されていた拡張機能とテーマのウィンドウが一つのアドオンマネージャに統合されました。
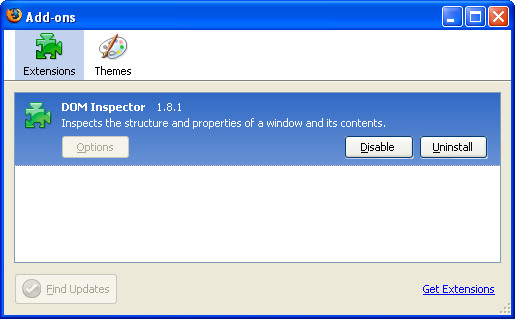 Firefox 2.0のアドオンマネージャ(2006年)
Firefox 2.0のアドオンマネージャ(2006年)水面下では、ユーザにとって危険と判断された拡張機能をMozillaの手で外部から無効化する事を可能にするためのブロックリスト機能の最初のバージョンを含む、さらに多くの変更が行われていました。この機能が作られて以来、私たちはこの機能を本当にごく希にしか使っていませんが、セキュリティ上の弱点やクラッシュを防ぐ際の助けとなってきました。
Firefox 3.0
Firefox 3において、私たちはプラグインをアドオンマネージャの中に含めるようにし、また初めての利用において皆さんがアドオンマネージャを使ってaddons.mozilla.orgからアドオンを直接ダウンロードしてインストールできるようにしました。これは私(※訳註:原文の著者のDave Townsend氏)がFirefoxにおいて作業した最初の大きな機能で、この機能がどれだけ使われているかをアドオンチームから聞く度に、私はいつも非常に嬉しい気持ちになります。
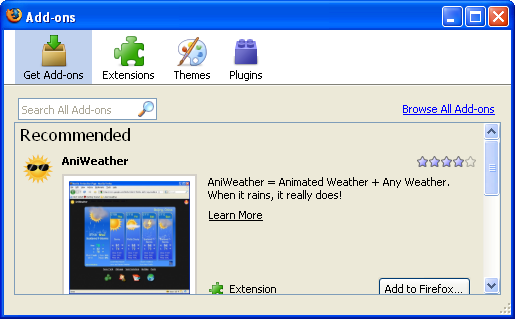 Firefox 3.0のアドオンマネージャ(2008年)
Firefox 3.0のアドオンマネージャ(2008年)内部的には、ブロックリスト機能はプラグインをブロックできるように拡張され、Windows以外のプラットフォームにおいてもシステム上の他のアプリケーションとの連携に対応するためにインストール対象となるファイルの置き場所が新しく追加されました(※訳註:bug 311008)。
Firefox 3.5と3.6
Firefox 3.5と3.6においては視覚的な変更点は全くありませんでしたが、Firefox 3.5ではブロックリスト機能がいくつかの異なる重要度のレベルに対応できるように再度改良され、Firefox 3.6ではシステム上にあるアップデートが必要なプラグインについてユーザに警告を行う機能への対応に加えて、Firefoxのメインウィンドウの単調な背景を簡単に切り替えられるようにする、産まれたばかりのペルソナがアドオンマネージャに搭載されました。
Firefox 4.0 beta
Firefox 4では、再起動が不要な拡張機能への対応の追加や、ユーザの操作をより妨げない自動的な更新のための仕組み、そして新しいアドオンに出会うためのより便利な方法などを含む、アドオンマネージャの全面的な再設計が見られます。
 Firefox 4 betaのアドオンマネージャ(2010年初頭)
Firefox 4 betaのアドオンマネージャ(2010年初頭)
裏側においては、新しいアドオンマネージャは新しい種類のアドオンを、これまでよりもさらに簡単に管理できるようになっています。
Firefox 4.0
ユーザ・エクスペリエンスチームは、Firefox 4のリリース版でアドオンマネージャがどのように見えるようになるかの最終的なデザインを作成するために、一生懸命働いています。あくまで仮の物ですが、これは彼らが行おうとしていることのスケッチです:
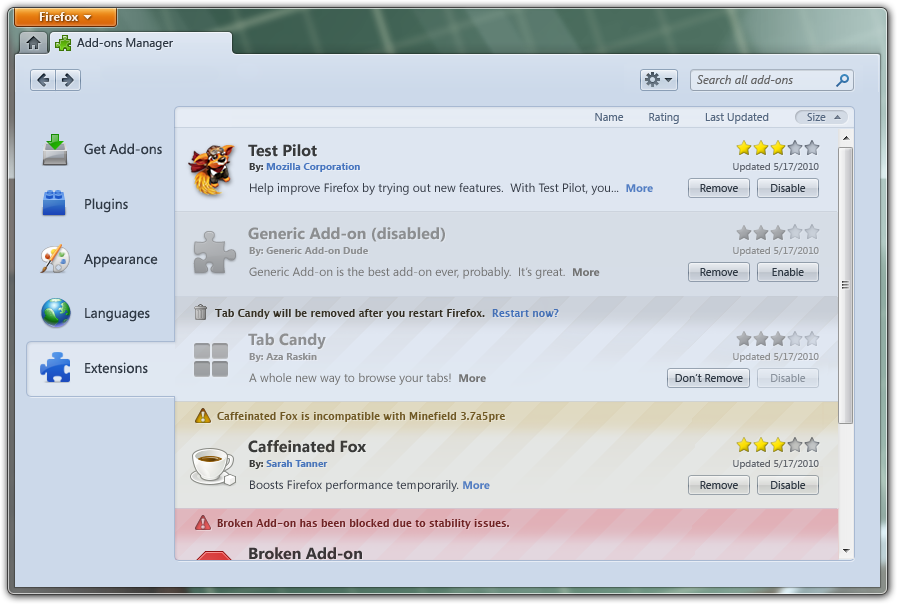 Firefox 4最終版用に検討中のデザイン(2010年末頃?)
Firefox 4最終版用に検討中のデザイン(2010年末頃?)
将来的に、私たちはさらに多くの種類のアドオンをこのマネージャの中に持ち込むことを計画しています。現在はそれ用の独自のウィンドウで管理されている検索プラグインなどのような物は、ここにうまく収まるでしょう。また、私たちは皆さんが拡張機能をより単純な形でカスタマイズするようにしたいとも考えています。可能性は低いですが、私たちは拡張機能の開発者達に対して、独自の設定ウィンドウを作る事を許容するのをやめて、新しいウィンドウを開くことを必要とせずに、単純な設定をアドオンマネージャの中で直接変更できるようにする機能を加える事を検討しています。私たちは、皆さんがインストール済みのプラグイン――それは時にセキュリティ上の問題や、安定性を損なう問題の元になります――を自動的に更新する方法を実現できたらと考えていますし、テーマの選択について、どんなテーマが利用可能かを見たり、それらを切り替えたりするのを、より簡単に行えるよう大幅な改良を行いたいとも考えています。
これらのことのうちのいくつかはFirefox 4.0までの時間で実際に行われるかもしれませんが、最終的なリリースの前に新しい物を取り入れるには、時間は残り少ないです。
DOM要素に対して起こったイベントのロギング - Sep 17, 2010
transitionendをトリガーとしてタブを閉じる処理が完了されるはずなのに、それが実行されなくて閉じられないタブが残ってしまう問題について、実際にどのアニメーションが成功したのか・失敗したのか、何がトリガーになっているのか、というのをデバッグしたかったんだけど、「閉じられないタブ」が発生した後からそれを調べる方法がなかったので、じゃあ先にログを収集しておこうという事でこういうコードを書いてみた。
var startDOMLogging = function(aElement) {
var log = aElement.DOMLog = Array.slice(aElement.DOMLog || []);
aElement.addEventListener('DOMAttrModified', function(aEvent) {
if (aEvent.originalTarget != aEvent.currentTarget) return;
log.push({
type : aEvent.type,
attrName : aEvent.attrName,
prevValue : aEvent.prevValue,
newValue : aEvent.newValue,
timeStamp : Date.now()
});
}, false);
aElement.addEventListener('transitionend', function(aEvent) {
if (aEvent.originalTarget != aEvent.currentTarget) return;
log.push({
type : aEvent.type,
propertyName : aEvent.propertyName,
elapsedTime : aEvent.elapsedTime,
timeStamp : Date.now()
});
}, false);
};
gBrowser.tabContainer.addEventListener('TabOpen', function(aEvent) {
startDOMLogging(aEvent.originalTarget);
}, false);DOM InspectorでJavaScript Objectを表示してSubjectのEvaluate JavaScriptで alert(JSON.stringify(target.DOMLog)) とすれば、そのDOM要素で何が起こっていたのかが分かる。
エラーコンソールとかデバッグ系のツールで最初からこういう事ができるといいのにね。UxUにそういうユーティリティを追加してみようかな。