Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

シェルスクリプトでランダムにあれをやる - Dec 30, 2015
「何分の一で」とかの情報は出てくるんだけど、知りたかったことそのものズバリの「何パーセントの確率でアレをやる」という例がなかなか見つからなかったので、まとめてみました。
シェルスクリプトで乱数
まず根底にある「ランダムに」っていう所だけど、これはBashかそうでないかでやり方が変わる。
Bashでは$RANDOMを参照すると0から32767の範囲でランダムな結果が得られる。
$ echo $RANDOM
15999
Bash以外では、/dev/urandomとodコマンドを組み合わせて似たような事ができるようだ。
$ od -vAn --width=4 -tu4 -N4 </dev/urandom
1939740834
0~N-1の範囲で乱数を得る
以下、説明を簡単にするために$RANDOMの方でコードを書くけど、違うシェルでは適宜読み替えて下さいという事で。
あと、ここからは数値計算が出てくるので、中に書いた式を計算した結果を得る$((計算式))の書き方(算術展開)を使っていく。
気を取り直して、0~N-1の範囲でランダムに1つを選ぶ方法。
これは割り算の余りを使う。
乱数をNで割った余りを求めれば、0~N-1のいずれかの数字が得られる。
例えば$(($RANDOM % 10))とすれば、0~9のいずれかの数字が得られる(つまり、10パターンに分岐できる)。
$ echo $(($RANDOM % 10))
0
$ echo $(($RANDOM % 10))
5
$ echo $(($RANDOM % 10))
3
1/Nの確率で何かやる
先の結果がどれか1つの選択肢に等しくなった時だけ処理を実行すれば、「約1/Nの確率で実行」ということになる。
[ $(($RANDOM % 3)) -eq 0 ]なら、約1/3の確率で真になり&&以下が実行される。
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
Hit!
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
ここまではすぐ例文が出てくるんだけど、ここから先が出てこなかったので自分で考える必要があった。
N%の確率で何かやる
実際に「ランダムに何かをやりたい」時というのは、多分、だいたいは「パーセンテージとか割合で頻度を指定したい」って場面だと思う。 「60%の確率で分岐したい」みたいな。
これは、「1/Nの確率で」の例を発展させるとできる。
1/100までの精度だったら、まず0~99のいずれか1つをランダムに得る。
次に、これを-lt演算子(less thanだから、左辺が右辺より小さい<の意味)で「何パーセントでやりたい」という数字と比較する。
結果が真の時だけ処理を実行すれば、つまり「何パーセントの確率で実行」ということになる。
絵を描くのが面倒なのでアスキーアートでやると、
0--------------------99
こういう数直線があって
0-----+-------------99
↑30
この位置に線を引いて、0から99までのどれか1つをランダムに選んだ結果が線より左にある時だけ実行するということです。
↓この時だけ実行 ↓こっちだったら実行しない
○ ○ × × ×
0-----+-------------99
↑30
これを踏まえて、30%の確率でRun!という文字列を出すコマンド列なら、以下のようになる。
$ if [ $(($RANDOM % 100)) -lt 30 ]; then echo 'Run!'; fi
30の所を変えれば任意のパーセンテージにできる。
関数にするならこんな感じか。
run_with_probability() {
local probability=$1
if [ $(($RANDOM % 100)) -lt $probability ]
then
echo 'Run!'
fi
}
ほんとに狙ったとおりの結果を得られているか、同じ物を1000回くらい繰り返し実行して確かめてみる。
与えた数の連番を出力するseqコマンドとforループを組み合わせて、先の関数を1000回実行し、Run!が出力される頻度を見てみる。
(forループの出力結果をパイプラインでwc -lに渡して行数を数えれば、実際に出力された回数が分かる。)
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
303
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
292
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
316
1000回中の300回前後なので、まあだいたい30%になっている。 ばらつきがあるけど、試行回数を増やせば指定のパーセンテージに収束していくはず。
実際は「一定の確率で文字列を出力する」というのを汎用的にやりたかったので、こういう風にした。
probability() {
[ $(($RANDOM % 100)) -lt $1 ] && cat
}
# 95%の確率で出力→だいたいは出力される
output_message | probability 95
# 10%の確率で出力→滅多に出ない
output_message | probability 10
入力された複数行の中からランダムに1行抜き出す
ちょっと毛色が違うけど、これもついでに。
入力に対してその中からランダムに1つをピックアップするという場面では、これはQiitaにクロスポストした方の記事のコメントで指摘を頂いて知ったんだけど、そのものずばりのshufというコマンドがある。これは標準入力で受け取った内容を行ごとにシャッフルして出力するコマンドで、-nで取り出す行数を指定できるので、以下のようにすれば「ランダムに1行取り出す」という結果になる。
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | shuf -n 1
shufコマンドの存在を知らなかった時にそれを使わずに解いてみた時には、先の「0~N-1のいずれかを得る」の応用で以下のようにしてた。
choose_random_one() {
// 標準入力を一旦変数に保持
local input="$(cat)"
// 入力の行数を得る
local n_lines="$(echo "$input" | wc -l)"
// 「1~最終行の行番号」の範囲でどれか1つを得る
local index=$(( ($RANDOM % $n_lines) + 1 ))
// 得た行番号を使って、sedで「指定された番号の行だけを取り出す」操作を行う
echo "$input" | sed -n "${index}p"
}
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | choose_random_one
入力を「行数を数える時」と「実際に抽出する時」の2回使わないといけないので、一旦全部catで読み取って変数に保持してるというのがポイントでしょうか。
まとめ
ということで、「シェルスクリプトでランダムにアレをやる」色々でした。
なんでこんな事やってるかというと、シス管系女子の宣伝を自動化したくて、宣伝用アカウントの運用をボットにやらせたかったのですが、「コマンド&シェルスクリプト」の連載なんだからボットもシェルスクリプトの方がネタになるよね&自分で作れば「お、作者はちゃんと技術分かってる人なんだな」と技術的な信頼に繋がるかな?と思って、TwitterクライアントとボットをBashでゴリゴリ書いているからなのでした。 ……って、単に宣伝を投稿するだけならTwitterクライアントができた時点でcronjobでやってしまえばよかったはずなのに、「何パーセントの確率で会話を継続する」とかそんな領域に足を踏み入れてるのは明らかにおかしいですね。ほんとに「どうしてこうなった」だ。
BtoBの仕事だったり実用のアドオンだったりでしかコード書いてないと、一定の確率で何かやるという事が必要になる場面が全く無くて(確実に何かやる、という事ばっかりだから……)、ぱっとやり方を思いつけなくて参りました。 という情けないお話。
system-admin-girl.comのこと - Dec 04, 2015
シス管系女子の特設サイトができました、というか例によって自分で作りました。 3日ほど夜なべして。
どうしてこうなった
電子書籍はいわゆる印税契約だけど紙の方は原稿料買い切り(書籍じゃなくムックだから)なので、プロモーションに工数かけてもあまり得にならないんですよね。なのに何故やったのかというと……要するに、欲しかったんですよ!!! 僕が!!!!!
いやね、連載5年目に入ろうとしてるのにWeb上では相変わらず知名度が低くて、知ってる人は知ってる的な立ち位置がいいかげん辛くなってきたというか、この間なんて「たまたま日経Linuxを見たらこんなの(#!シス管系女子Season3 Petitまとめ読み)あったんだけど、これってもしかしてシェルスクリプトマガジンのシェル女子の便乗企画……?」みたいに思われてしまった、というのは被害妄想もいいとこなんですが、「それもこれもみんな、ここ見れば大体分かるっていう位置付けの公式サイトが無いせいなんや!」と大人げなく嫉妬に狂いまして、手元にあった素材と原稿データをイラレの上で切り貼りしていわゆる1枚ペラのページのこんな妄想画像
 を作って「こういうのがほしいんだよこういうのがああああああ!! 日経Linuxのサイトの中に特設ページ作ってもらえませんかね!?」と日経BPサイドに提案してみたものの、会社の方針とかであんまり他のページと違う物は載せられないのでPDF置いとくだけならまぁなんとか……と言われてしまって「そういうことじゃないんだよおおおおお!!!」と血の涙流しながらHTMLとCSSをゴリゴリ書いてさくらのレンタルサーバの一番安いプラン借りてお名前.comでドメイン取って(独自ドメイン取るのこれが初めてですよ! なんと!)突貫工事で作った、というのが真相ですハイ。
説明文が「Piro氏」とか微妙に客観なのは、元が日経BPへの提案用だったからで。
を作って「こういうのがほしいんだよこういうのがああああああ!! 日経Linuxのサイトの中に特設ページ作ってもらえませんかね!?」と日経BPサイドに提案してみたものの、会社の方針とかであんまり他のページと違う物は載せられないのでPDF置いとくだけならまぁなんとか……と言われてしまって「そういうことじゃないんだよおおおおお!!!」と血の涙流しながらHTMLとCSSをゴリゴリ書いてさくらのレンタルサーバの一番安いプラン借りてお名前.comでドメイン取って(独自ドメイン取るのこれが初めてですよ! なんと!)突貫工事で作った、というのが真相ですハイ。
説明文が「Piro氏」とか微妙に客観なのは、元が日経BPへの提案用だったからで。
3日でできたのは十数年越しのイメトレのおかげや……
思い返せばかれこれ14~5年は前ですかね?
CSSコミューンで偉そうなこと言ってて「Web業界に進みたいな」とか一瞬思ってたあの頃。
CSS2の仕様通りに書いた物をInternet Explorerが微妙にまともにレンダリングしてくれなくて、それでもNetscape Communicator 4での悲惨な対応具合に比べればまだマシというネスケ派の自分にとっては「ギギギ……!」と歯ぎしりせずにはおれない状況で、NC4でもIEでもきちんと表示できてW3C的にも(というかAnother HTML-lint的に?)Validで且つそこそこ凝った見た目を実現して「W3Cの理想は非現実的な絵空事なんかとちゃうんやで!!!」と世界の片隅でアピールしたい!という思いからこんなスタイルシートやあんなスタイルシートやそんなスタイルシートといったいろんな実験作を書いて粋がってた日々。
当時最もCSS2の実装が進んでたGeckoエンジンでさえできることは全然限られていて、「あぁ……この仕様にある:nth-child(2n-1)ってのが使えれば装飾の左右振り分けも簡単なのに……!」と思いながらclass="even"とかclass="odd"とか書いて騙し騙しやってましたとも。
ドロップシャドウひとつ作るのにも画像を作ってスライスして……よくあんなめんどくさいことやってたもんだ。
しかも人力で。
(素人でお金も無いのでDream WeaverだのFireworksだのは手が出なかった)
素人の僕でこんなんだった訳だけど、当時から業務として手がけておられた方々は僕なんかよりはるかに切実な思いでこういう事と向き合っていたのであろう。 CSS昔話 Advent Calendar 2015 - Adventarにはそういう時期の苦労話がたくさん集まってきそうな気配を感じている。
それが、今じゃどうですか。
<ruby><rb>文字の影</rb><rp>(</rp><rt>text-shadow</rt><rp>)</rp></ruby>も<ruby><rb>ボックスの影</rb><rp>(</rp><rt>box-shadow</rt><rp>)</rp></ruby>も<ruby><rb>角丸</rb><rp>(</rp><rt>border-radius</rt><rp>)</rp></ruby>も背景色の半透明もグラデーションも<ruby><rb>奇数番目と偶数番目での振り分け</rb><rp>(</rp><rt>:nth-child(2n-1)</rt><rp>)</rp></ruby>も、テキストでちょちょいっと書けば即反映ですよ。
当時は想像もしてなかった、CSSメディアクエリーなんて物もできてるし。
あの頃「こういう風に作れればいいのになあああ!!!」とイメージトレーニングしていた理想のCSS世界がまさに目の前にあるという感慨深さよ。
document.querySelectorAll()で要素をガッと集めてきて制御したり、今画面内にある画像をdocument.elementFromPoint()でダイレクトに取得して位置合わせしたり、Firefoxのアドオン開発でも苦労してた部分があっさりクロスブラウザで動いてくれちゃってて。
FirefoxとChromeのWindows版とAndroid版でだけ検証してリリースしちゃいましたが、後でIE11で見たら全く支障なく完璧に表示されてたし。
あまりのあっけなさに目がテンになり、その後感涙でむせび泣きかねない勢いでした。
SNSでシェアしやすく
……とまあ、昔取った杵柄で一枚ペラ&試し読み簡易マンガビューワーを作るところまではよかったんですが、宣伝のためのサイトなのにSNS連携のシェア用ボタンを入れてなかったり、FacebookやTwitterでシェアされたときにいい感じに画像を出す工夫をしてなかったり、「それやらないの今時あり得ないでしょ……」な手落ちだらけで、「エッなにそれいつの間にそんな事になってたの」と完全に浦島太郎でした。 かろうじてGoogleアナリティクスは存在を知っていたので、それだけは入れてましたが。
- ページ内に埋め込む「シェア」「Tweet」などのボタン群は、いいねボタン ツイートボタン ソーシャルボタン まとめて設置で作成しました。
- シェアされた時に狙った画像を出すogp:imageはさかどんに教えてもらいました。 メタ情報の設定後にデバッガーで強制再Fetchしないと変更が反映されないというのをいわいさんに教えてもらわなかったら、いまだに「なんでやーーー!!」と頭を抱えていたことでしょう。
- Twitterでの投稿時に狙った画像を出すTwiter Cardはちょまどさんに教えて頂きました。 ogp:imageを設定済みなら重複する情報は書かなくてもいいというのはこたろっくさんに指摘されるまで気付いてませんでした。
皆さんの助けが無ければ、作ったはいいものの結局やっぱり誰にも見られない廃墟サイト化一直線……という末路を辿っていたところでした。 大変お世話になりました。
良い物作ってるつもりでもプロモーションできてなきゃ存在しないのと同じ
思い出話8割に実用情報2割くらいでこんなエントリを書き記して何やってんのって自分でも思いますが、今僕が主たる仕事の場にしてるフリーソフトウェアの世界でも、プロモーションはやっぱ大事だなって思うんですよね。 先行実装があってそれなりに頑張って丁寧に作ってたのに、その存在を知らなかった人が後から作った荒い出来の物が「これ新しい!!! こんなの欲しかった!!!!」って人気をかっさらってって、先達の頑張りが全く誰からも評価されないまま消えていってしまう……俺達は、あと何回そんな悲劇を目にすればいい? 俺はあと何回、顧みられることの無い先駆者を目にすればいいんだ?
というわけで、今後仕事絡みで何か作って公開する時にまた参照したいので自分用のメモとして今回参照した情報をまとめたというのがこのエントリの趣旨なのでした。
まぁ、このsystem-admin-girl.comが実際どれだけ成果が出るかというのは分からない、ともすれば結局やっぱり廃墟になっちゃったねというオチもあり得そうではありますが、「だからこういう風にして欲しかったんだよぉぉおおおお!!」と地団駄踏んで不満溜め込んでるよりは、「思ってたやりたかったとおりの事やったけど駄目でしたわハハハ……」となる方がまだ精神衛生上良さそうなので、これで安心して眠れます。 おやすみなさい。
ページ内の見出し一覧をMarkdownのリスト形式で出力するbookmarklet - Jul 05, 2012
前に似たような事をやった気がするけど。
javascript:
var tab = ' ',
min = prompt('Input minimum level of the headings (default=1)');
function tabs(n) {
var ret = [];
for (var i = 0; i < n; i++) ret.push(tab);
return ret.join('');
};
function collectHeadings(minLevel) {
var rawHeadings = document.querySelectorAll('h1, h2, h3, h4, h5, h6');
var headings = [];
var heading, node;
for (var i = 0, maxi = rawHeadings.length; i < maxi; i++)
{
node = rawHeadings[i];
heading = {
node: node,
id: node.id,
label: node.textContent,
level: parseInt(node.localName.charAt(1))
};
if (heading.level >= min)
headings.push(heading);
}
return headings;
}
function generateList(headings) {
var list = [],
h,
id,
item,
nest = 0;
for (var i = 0; i < headings.length; i++)
{
h = headings[i];
id = h.id || h.node.parentNode.id || h.node.parentNode.parentNode.id;
item = (id) ? '['+h.label+'](#'+id+')' : h.label ;
if (i > 0) {
if (h.level > headings[i-1].level) {
nest += 1;
} else if (h.level < headings[i-1].level) {
nest -= 1;
}
}
if (nest == 0) {
list.push(' * '+item+'\n');
} else {
list.push(tabs(nest)+'* ' + item + '\n');
}
}
return list.join('');
}
var headings = collectHeadings(Math.max(1, min));
var list = generateList(headings);
if (list) window.open('data:text/plain,'+encodeURIComponent(list));
見出しレベルの関係がちゃんとしてないとうまく動かない。あとsection/headingのネストには対応してない。
JSDeferred - Why this code doesn't work? - Jun 12, 2012
I got a mail.
I've started to use jsdeferred 2 days ago and I'm really really happy with it because I consider it's really easy to use, light and it looks very powerfull. Anyway, I have one little doubt I hope you can help me about.
Here's the thing, I would like to deferredize some functions to use in some chains, but I haven't figured out what's the best way to get it, I put you a little example
If I try something basic like this:
function my_deferred(data) { var deferred = new Deferred(); deferred.call(data); return deferred; } function main() { Deferred.define(); my_deferred("foo"). next(function(data) { console.log(data); }); }The chain is not executed (I don't know why). But if I change to something like this, using setTimeout, it works:
function my_deferred(data) { var deferred = new Deferred(); setTimeout(function() { deferred.call(data); },1); return deferred; } function main() { Deferred.define(); my_deferred("foo"). next(function(data) { console.log(data); }); }The question is, wouldn't it be possible to get the right behaviour of the chain without using setTimeout? I would like to deferredize some functions without the penalty of using setTimeout.
You should use Deferred.next() ( it is available as a global function
next() if you use Deferred.define() ) instead of setTimeout(), like:
function my_deferred(data) {
var deferred = new Deferred();
Deferred.next(function() {
deferred.call(data);
});
return deferred;
}
Deferred.next() works just like setTimeout(), but in most cases it works
faster than setTimeout().
deferred.call() just calls the next job which is registered as a
callback function given to its .next() method. So, you have to call
deferred.call() after you register the next job.
However, In your case, any "next job" has not been registered yet when
you call deferred.call(). As the result, the "next job" registered after
deferred.call() was called won't be called by anyone.
function my_deferred(data) {
// (3) Now, we are in this function.
var deferred=new Deferred();
deferred.call(data); // (4) deferred.call() is called, then
// the next job ( registered via
// deferred.next() ) is also called.
// However, it has not been registered yet.
// As the result, nothing happens.
return deferred; // (5) We return the deferred object and
// exit from this function.
}
function main() {
// (1) Starting position of this event loop.
Deferred.define();
// (2) The function is called.
my_deferred("foo").
next(function(data) {
// We never come here!!
console.log(data);
}); // (6) You register the next job to the returned deferred
// object, via its next() method. However, because
// deferred.call() was already called, the job will
// never be called by anyone.
// (7) End of this event loop.
}
Instead,
function my_deferred(data) {
// (3) Now, we are in this function.
var deferred=new Deferred();
Deferred.next() {
// (8) Now, the next event loop is started.
deferred.call(data); // (9) deferred.call() is called, then
// the registered next job is also called.
}); // (4) We just reserve the task for the next event loop.
return deferred; // (5) We return the deferred object and
// exit from this function.
}
function main() {
// (1) Starting position of this event loop.
Deferred.define();
// (2) The function is called.
my_deferred("foo").
next(function(data) {
// (10) We are here!
console.log(data);
}); // (6) You register the next job to the returned object.
// (7) End of this event loop.
}
As above, you must register the next job to the deferred object before its call() is called.
ちょよんごさんによると、このメールの送り主の人(ここでは省いたけど、WebGL用のスクリプトを書いてるそうです)は、JSDeferredを使ってるとおぼしき開発者に手当たり次第質問を投げてるらしい。そんなこととはつゆ知らず「僕作者じゃないんだけどなあ」と呑気にちょよんごさんに転送してしまって、余計なストレスをかけてしまったようなので罪滅ぼしと思って真面目に返信してみた。伝わってるかどうかは分かんないけど。
これはJSDeferredの結構典型的なハマリ所だと思う。XMLHttpRequestとかNode.jsの非同期なメソッドみたいに、コールバック関数が必ず次以降のイベントループで呼ばれる物に対してであれば、このメールの送り主の人が書いてるような
var Deferred = require('jsdeferred').Deferred;
var fs = require('fs');
function statDeferred(filePath) {
var deferred = new Deferred();
fs.stat(filePath, function(error, stats) {
if (error)
deferred.fail(error);
else
deferred.call(stats);
});
return deferred;
}
statDeferred('/tmp/foobar')
.next(function(stats) {
if (stats.isDirectory()) {
...
}
});
こういう流れの書き方で何も問題ない。
問題は、やらせたい処理が同期的であった場合で、
function statDeferred(filePath) {
var deferred = new Deferred();
try {
var stats = fs.statSync(filePath);
deferred.call(stats);
} catch(error) {
deferred.fail(error);
}
return deferred;
}
これでは動かないのですよね。
何故かというと、 deferred.call() は「その deferred の next() に渡された関数、という形で あらかじめ 登録されていた『次のジョブ』を実行する」物だから。
この例だと statDeferred() が deferred を return する前に deferred.call() を呼んでしまっているから、その後で次のジョブを登録しても、登録した「次のジョブ」を呼ぶ人が誰もいないわけです。
function statDeferred(filePath) {
// (2) 関数の中に入った。
var deferred = new Deferred();
try {
var stats = fs.statSync(filePath); // (3) 処理を実行した。
deferred.call(stats); // (4) 登録済みの「次のジョブ」を実行しよう……
// とするんだけど、まだ何も登録されてないので、
// 当然何も起こらない。
} catch(error) {
deferred.fail(error);
}
return deferred; // (5) 関数を抜けた。
}
// (1) 今のイベントループでのスタート地点。
statDeferred('/tmp/foobar')
.next(function(stats) {
// 「次のジョブ」の登録後に deferred.call() が呼ばれないので、ここには到達しない。
if (stats.isDirectory()) {
...
}
}); // (6) 戻り値の next() を呼んで、「次のジョブ」を登録した(今更)。
// (7) 今のイベントループの終わり。
だから、 setTimeout() なり Deferred.next() なりを使って、 deferred.call() を呼ぶ処理を「次のジョブを登録する処理」よりも後(=次のイベントループ)に実行する必要がある。そうすれば、
function statDeferred(filePath) {
// (2) 関数の中に入った。
var deferred = new Deferred();
Deferred.next(function() {
// (7) 次のイベントループで、予約されたこの処理が始まる。
try {
var stats = fs.statSync(filePath);
deferred.call(stats); // (8) 登録済みの「次のジョブ」を連鎖的に呼ぶ。
} catch(error) {
deferred.fail(error);
}
}); // (3) 次のイベントループで実行するように予約。
return deferred; // (4) 関数を抜けた。
}
// (1) 今のイベントループでのスタート地点。
statDeferred('/tmp/foobar')
.next(function(stats) {
// (9) 「次のジョブ」として、この処理が始まる。
if (stats.isDirectory()) {
...
}
}); // (5) 戻り値の next() を呼んで、次のジョブを登録した。
// (6) 今のイベントループの終わり。
……という順番で処理が進むから、期待通りに動くようになる。
どの処理が一体何をしているのか、どの関数が何を返しているのか、自分が呼んでいるメソッドは誰のメソッドなのか、といった事をちゃんと理解しておくと、この話がすっと頭に入ってくると思うんだけど、ただの構文として覚えてしまっていると、メールの送り主の人みたいに「何で動かないの……」って詰まってしまうんだと思う。
という風に偉そうな事を言ってるけど、僕自身も最初は多分ただの構文として覚えてた方で、ただ、「同期処理の時は setTimeout() なり Deferred.next() なりを使って deferred.call() を呼ぶ」という所までを「構文」として暗記していたから、結果的にはちゃんと動いてくれてたという状態だったんだと思う。その後若手IT勉強会の中でコードリーディングをやってだんだん仕組みが分かってきて、「ああなるほど、こういうことだったんだ」と理解できるようになった。
Firefox Hacks Rebootedでもいっぱい書いたけど、JSDeferredの本質は、「あらゆる処理について、その次にやらせたい仕事を next() のコールバック関数という形で後から登録できるようにする」ものだ、と僕は認識してる。「後から登録する」という都合上、この性質は非同期処理(関数を抜けた時点でまだ処理が始まっていないという種類の処理)と非常に相性がいい。けれども、非同期処理じゃないと使えないわけではない。ただ、「後から登録する」というのは、普通に順番通りに進む同期的な処理の中では行えないイレギュラーな事だから、 setTimeout() や Deferred.next() を使わざるを得なくて、それで初見の人に分かりにくくなってしまう。そこがもどかしい所だ。
CSS3のborder-imageを先行実装した-moz-border-imageの仕様変更とその対策 - Jan 14, 2012
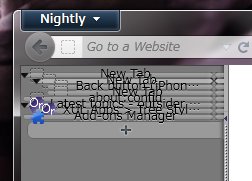
ツリー型タブの組み込みのテーマで主にMac OS X向けに用意してある「Metal」の表示が、Nightly 12.0a1で盛大にぶっ壊れてた。原因は、CSS3のborder-imageの先行実装である-moz-border-imageの仕様が変わったせいだった。
当初の実装では、-moz-border-imageはこんな風に書くようになってた。
-moz-border-image: url("tab.png") 10 5 10 10 / 10px 5px 10px 10px stretch stretch;
 「Metal」の場合、右の辺だけ5ピクセル幅でそれ以外の辺は10ピクセル幅という事にしていた。しかし、単にこう書くと、「タブの内容」の周囲に「10ピクセル幅の枠線」が付くことになるので、タブの高さが上下合わせて20ピクセル広がってしまう。なので、「タブの内容」の方に
「Metal」の場合、右の辺だけ5ピクセル幅でそれ以外の辺は10ピクセル幅という事にしていた。しかし、単にこう書くと、「タブの内容」の周囲に「10ピクセル幅の枠線」が付くことになるので、タブの高さが上下合わせて20ピクセル広がってしまう。なので、「タブの内容」の方に
margin: -10px -5px -10px -10px;
padding: 10px 5px 10px 10px;
という感じでネガティブマージンとそれを相殺するパディングを指定して、枠線とタブの内容を重ねることでタブの大きさをそれほど大きく変えないようにしていた。
それが、Nightlyではこんな事になってしまってた。
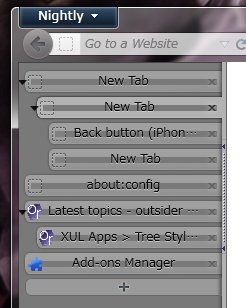
 新しいborder-imageの仕様に合わせて実装が変わったということなのか、「タブの内容の周囲に10ピクセル幅の枠線が付」いても、その分ボックスの大きさが広がるという事が無くなったようだ。にもかかわらずネガティブマージンを適用していたがために、今度は逆にタブの高さが上下合計で20ピクセルも小さくなってしまって、このスクリーンショットのように極細なタブになってしまっていた……という事だった。
新しいborder-imageの仕様に合わせて実装が変わったということなのか、「タブの内容の周囲に10ピクセル幅の枠線が付」いても、その分ボックスの大きさが広がるという事が無くなったようだ。にもかかわらずネガティブマージンを適用していたがために、今度は逆にタブの高さが上下合計で20ピクセルも小さくなってしまって、このスクリーンショットのように極細なタブになってしまっていた……という事だった。
そこで、とりあえずネガティブマージンの指定を外してみたところ、タブの高さが変になる現象は改善された。が、今度はborder-imageに指定した画像の真ん中が抜けてしまう(今までは画像の中央部分が拡大されて背景画像代わりになっていた)という、また別の現象が起こっていた。
最初は「バグか?」と思ったんだけど、Firefox自身の既定のスタイルシートでどう使われてるのかソースコードを調べてみたら、理由が分かった。以下の例のように、「fill」というキーワードを明示的に書かないと真ん中の部分は埋められないようになったということのようだった。
-moz-border-image: url("tab.png") 10 5 10 10 fill / 10px 5px 10px 10px stretch stretch;この変更はBug 497995で行われたもので、提案されてる最新の仕様が変わったので書き方も変えましょう、という話なんだけど、アドオンで古いバージョンのFirefoxにも対応させてる場合はそうもいかないんだよね。この仕様変更はFirefox 12から反映されることになるようなんだけど、もうすぐ出るというESR(主に企業向けの長期サポート版)はFirefox 10ベースで、そっちは古い仕様に基づいた実装のまま出回っちゃうわけです。Firefox 3.6の後を引き継ぐ形のFirefox 10はやっぱり一応サポートしといた方がいいと思うわけで、でもFirefox 12のためにCSSの記述を変えたらFirefox 10では枠線用の画像が全く表示されない(fillなんて未知のキーワードは文法違反!ということで-moz-border-imageの指定自体が無視される)し、かといってFirefox 10用の記述にしておくとFirefox 12でタブの真ん中が透明になってしまうし……あちらを立てればこちらが立たずの典型だ。
ネガティブマージンを使ってる部分はいかにもハック的だから、別のファイルに分けてchrome.manifestで条件付きのディレクティブで読み込ませるのもいいと思うんだけど、fillキーワードの方はそれはちょっと気が進まなかった。たった4文字のためにファイル分けるなんて、メンテナンスコストの増え方と得られる効果が割に合わない気がした。
それで少し悩んだんだけど、おそらくこの変更によって-moz-border-imageの扱いが「いろんな機能を持ってる単一のプロパティ」から「複数のプロパティの値を一括して指定するためのプロパティ」に変わった(DOM Inspectorで見てみたら見慣れない「-moz-border-image-なんちゃら」系のプロパティがいくつも表示されてた)ということが、解決の糸口になった。fillキーワードはそれらの個別プロパティの中の「-moz-border-image-slice」というプロパティに指定する物らしかったので、以下のように並べれば、1行目でFirefox 10とFirefox 12の両方に対して基本的な指定を適用して、2行目でFirefox 12用に正しい値を個別に上書きする(Firefox 10にとっては-moz-border-image-sliceは未知のプロパティなので、古い環境では2行目は無視される)ということだ。これなら、メンテナンスコストをそれほどかけずにFirefox 10にもFirefox 12にも対応できる。
-moz-border-image: url("tab.png") 10 5 10 10 / 10px 5px 10px 10px stretch stretch;
-moz-border-image-slice: 10 5 10 10 fill;FirefoxのmozRequestAnimationFrame()の仕様が変わってた - Dec 02, 2011
2011年11月30日付けのNightly 11.0a1でツリー型タブが動かないっていう報告を受けたので調べてみたら、なんかJavaScriptベースでアニメーション効果を実装する時に使えるFirefox 4から(だったっけ?)の新しい機能に基づいたアニメーション管理のための仕組みが期待した通りに動かなくなってて、あれこれ試してるうちにどうもmozRequestAnimationFrame()の使い方のうちDOMイベントベースでやる方のが動かなくなっててコールバック関数を使う方法でならうごくっぽいという事が分かったので、ツリー型タブ0.12.2011120101からはそのように変更した。
えむけいさんが教えて下さった所によると、これはBug 704171 – Remove the no-argument form of requestAnimationFrameでの変更による物で、要するに「DOMイベントベースの方法は正式な仕様になりそうにないし誰も使ってないし、もう廃止してよくね?」ってことで、Geckoでしか使えなかったDOMイベントベースの方法は廃止されて、WebKit等でも利用できるのと同じ形式のAPIに統一されたんだそうだ。まさにその当日にMDNのドキュメントを調べてて、その廃止された方の使い方が解説されていて、MDNにも書いてある使い方なのにおっかしーなーと首をひねってたんだけど、単にドキュメントの更新が間に合っていなかっただけだった。
現実的には妥当な決定だと思うけど、なんか釈然としない。例外のメッセージで「仕様が変わった、古い使い方はもう使えない」とかそういう情報を出してくれれば、もうちょっとすんなり原因に気がつけただろうに……
JSDeferredを小さくする - Feb 27, 2011
JSDeferredは非同期処理の制御に特化しててサイズも小さくて素敵な軽量ライブラリだ!と僕は思ってるんだけど、世の中を見回してみると「軽量ライブラリ」って言われてる物は3KB未満とかそういうのが結構あるようだし、jQueryも1.5.1のminified版は28KBって書いてあるし、そうなるとjsdeferred.jsのコメント付き版が0.3.4で19KBというのは「軽量」と呼ぶにはひょっとしてちょっとでかいのかな……という気がしてきた。
なので、JS MinifierとかPackerとかそういう風なやつでどれくらい小さくなるのか実験してみた。
/packer/はそのままだと構文エラーで動かなくなってしまった。}Deferred. って部分が7箇所あってこれがエラーになってるので、全部 };Deferred. に置換(Base62圧縮後だと }4. を };4. に置換)したら一応エラーは出なくなった。/packer/の構文解析が貧弱なせいっぽいので、JSDeferredの側で問題になる所にあらかじめセミコロンを入れておけば、この問題は無くなるっぽい気がする。……と書いたからか、ちょよんごさんが対応してくれた。ありがとうございます!
あと、closure-compiler を通すと 2668bytes でした (jsdeferred のレポジトリで rake すると URL が出るようになってます)
というアドバイスも頂いたので早速Closure Compilerにかけてみた所確かに小さくなったのですが、シンボル類まで全部失われちゃってこれ単体だと他のスクリプトと組み合わせられないのが残念ですね。(Closure Compilerは他のスクリプトも全部合わせて一緒にコンパイルして使うのが前提ってことなんだろう)
Excelの「AA」とかのカラム名とカラム番号の数値を相互変換する - Feb 15, 2011
96桁目のセルに所定の値が入ったCSVを作る、みたいな事をやらなきゃいけなくなったんだけど、GnumericにしろExcelにしろカラム名が数字じゃなくてA, B, C, ... Z, AA, AB, ... ZZ, AAA, ...というヘンテコ表記になってるからどこのセルに値を入れればいいかわかんないよウワァァァァン!!!! となったのでJavaScriptで解決した。
var input = prompt('input number or column name');
if (!input) return;
var symbols = 'abcdefghijklmnopqrstuvwxyz';
var result;
if (/^[0-9]+$/.test(input)) {
input = parseInt(input);
result = [];
while (input > 0) {
result.unshift(symbols.charAt((input - 1) % symbols.length));
input = Math.floor((input - 1) / symbols.length);
}
result = result.join('').toUpperCase();
}
else {
result = 0;
input = input.toLowerCase().split('').reverse();
for (var i = 0, maxi = input.length; i < maxi; i++) {
result += (symbols.indexOf(input[i]) + 1) * Math.pow(symbols.length, i);
}
}
alert(result);
カラム名→カラム番号の計算方法は分かったけど、頭が悪い僕にはカラム番号→カラム名の計算式が分からなかったので、検索して出てきたエクセルの1000列目は ALL - つまみ食うのアルゴリズムを丸パクリした。阿呆ですんません……
なんでそこで詰まったかっていうと、単純な26進数の変換ではうまくいかなかったからなんですよね。A==0、B==1という感じで26進数として扱うと、26==Zで27==BAになるんだけど、実際は繰り上がった後はBAじゃなくてAAにならなきゃいけない。そこの所を考慮した計算を多分簡単なループで実現できるとは思ったんだけど、頭が働かなくて無理だった。
JsDoc ToolkitでJavaScriptコードモジュールのDoc Commentを出力する - Aug 20, 2010
Doc Commentの必要性
最近、JsDoc Toolkitの導入を考えてる。
- ライブラリとして抜き出したコードを公開しておきたいけど、ライブラリ自体の使い方を書いたページを準備するのが面倒だし、多分誰も見てくれなさそう。
- ソースコードの中にコメントとして使い方を埋め込んでおくと、見るべきファイルが1つで済むから良さそうだけど、どんな書式で書くと分かってもらいやすいかが問題だ。
ツリー型タブのAPI紹介等ではXPIDLっぽい書き方にしてみてるけど、オレオレ表記なので分かってもらえない可能性があるという心配はずっとしている。
ところで、Firefox自体のソースを見ていると以下のような書き方をしているのをよく見かける。
(略)
/**
* Given a starting docshell and a URI to look up, find the docshell the URI
* is loaded in.
* @param aDocument
* A document to find instead of using just a URI - this is more specific.
* @param aDocShell
* The doc shell to start at
* @param aSoughtURI
* The URI that we're looking for
* @returns The doc shell that the sought URI is loaded in. Can be in
* subframes.
*/
function findChildShell(aDocument, aDocShell, aSoughtURI) {
(略)これはJavaで標準的に使われているJavadocという「ソースコードの中に埋め込まれたコメントを自動的に収集してHTML形式でドキュメントを生成する」仕組みに基づいたもので、同じ形式でコメントを埋め込めるよう、Javadocの仕様に準拠した実装が言語ごとに存在しているようだ。JavaScriptならJsDoc Toolkit、C言語ならGTK-Docが一般的らしい。あとJavaScriptに関してはGoogle Closure ToolsのClosure Compilerも対応しているらしい
事実上の標準としてみんなが見慣れた形式なのであるならば、これに合わせて書くのがいいだろう。と思ったので、とりあえずライブラリとして切り出して公開しているコードにJavadoc形式で使い方の解説を埋め込んでみることにした。
JsDoc Toolkitの使い方
- Javaをインストールする。
- JsDoc Toolkitをダウンロードして展開しておく。
- JsDoc-Toolkitを使うで配布されているバッチファイル「jsdoc.bat」を、JsDoc Toolkitのjsrun.jarとかと同じ位置に置く。
- JavaScriptのファイルの中にDoc Commentを書く。書き方はJsDoc Toolkitによる開発効率向上を目指して - @IT等を見ると例がある。
- jsdoc.batの起動オプションにJavaScriptのファイルを渡して起動する。
- jsdoc.batと同じ位置にjsdocという名前のフォルダができて、その中に生成されたHTMLファイルがあるので、index.htmlをブラウザで開いて眺めてニヨニヨする。
JavaScriptコードモジュールとJsDoc Toolkit
- JavaScriptコードモジュールではファイルの拡張子として「.jsm」を使うことが多いみたいなんだけど、.jsmなファイルにDoc Commentを埋め込んでJsDoc Toolkitに渡してみてもドキュメントを出力してくれなかった。
- UxU用のテストケースまで走査するため、フォルダごと渡してまとめてドキュメントを生成させてみると、ファイル一覧の中にテストケースのファイルまで出てきてしまう。
@exampleに例を書く時に、例の中に<とか>とかのHTML的にまずい文字が含まれていると、出力されるHTMLがぶっ壊れてしまう。
JsDoc Toolkit自体のソースを見てみた所(JsDoc Toolkitはそれ自体がJavaScriptで書かれている。Java上で動作するJavaScript実行環境のRhinoの上で動作している。)、ファイルの拡張子でフィルタリングを行っているらしいということが分かった。あと、テンプレートのファイルの方を編集すれば、例に埋め込んだコードのせいでHTMLがぶっ壊れてしまう問題は回避できるようだった。
そういうわけで当面の所はこんな変更を加えて使ってみることにした。以下はjsdoc_toolkit-2.3.2.zipに対する差分です。
diff -ur jsdoc-toolkit-orig/app/lib/JSDOC/JsDoc.js jsdoc-toolkit/app/lib/JSDOC/JsDoc.js
--- jsdoc-toolkit-orig/app/lib/JSDOC/JsDoc.js 2009-01-24 18:42:04.000000000 +0900
+++ jsdoc-toolkit/app/lib/JSDOC/JsDoc.js 2010-08-20 10:17:17.602464000 +0900
@@ -69,7 +69,8 @@
JSDOC.JsDoc._getSrcFiles = function() {
JSDOC.JsDoc.srcFiles = [];
- var ext = ["js"];
+ var ext = ["js", "jsm"];
+ var ignorePattern = /\.test\.js$/i;
if (JSDOC.opt.x) {
ext = JSDOC.opt.x.split(",").map(function($) {return $.toLowerCase()});
}
@@ -89,7 +90,7 @@
}
}
- return (ext.indexOf(thisExt) > -1); // we're only interested in files with certain extensions
+ return (ext.indexOf(thisExt) > -1) && !ignorePattern.test($); // we're only interested in files with certain extensions
}
)
);
diff -ur jsdoc-toolkit-orig/app/run.js jsdoc-toolkit/app/run.js
--- jsdoc-toolkit-orig/app/run.js 2009-01-08 06:32:58.000000000 +0900
+++ jsdoc-toolkit/app/run.js 2010-08-16 17:28:28.673092400 +0900
@@ -337,7 +337,7 @@
if (!path) return;
for (var lib = IO.ls(SYS.pwd+path), i = 0; i < lib.length; i++)
- if (/\.js$/i.test(lib[i])) load(lib[i]);
+ if (/\.jsm?$/i.test(lib[i])) load(lib[i]);
}
}
Only in jsdoc-toolkit: jsdoc.bat
diff -ur jsdoc-toolkit-orig/templates/jsdoc/class.tmpl jsdoc-toolkit/templates/jsdoc/class.tmpl
--- jsdoc-toolkit-orig/templates/jsdoc/class.tmpl 2009-09-03 06:37:31.000000000 +0900
+++ jsdoc-toolkit/templates/jsdoc/class.tmpl 2010-08-18 15:10:02.542253900 +0900
@@ -300,7 +300,10 @@
<if test="data.example.length">
<for each="example" in="data.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -399,7 +402,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -466,7 +472,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -565,7 +574,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
モックが必要な場面、モックが有効な場面 - Aug 11, 2010
モック(Mock)とスタブ(Stub)の違いがよく分かってなかったんだけど、何が違うのか、そしてモックはどう使う物なのかということを、すとうさんに教えてもらって今更理解した。あとで会社のブログに書くつもりだけど、メモとして要点だけまとめておく。
- テストは基本的に、粒度の細かいブラックボックステストにした方がいい。
- 内部に持ってる隠しプロパティの値が正しいかどうか?という風な実装べったりのテストは、実装の変更に非常に弱い。
- なので、関数の返り値だけ見て検証できるような設計が、自動テストしやすい設計という意味で「良い設計」と言える。
- しかしブラックボックステストには限界がある。
- 色々な副作用を伴う機能だったり、非同期で処理するような機能だったり、1回の実行で複数の状態を遷移する機能だったり、という風に、単純に関数の実行→返り値を検証 とするだけではテストできない機能もある。
- ユニットテストのレベルでそういう機能があるのは設計が良くない証拠なので、こういう物は関数を細かい単位に解体して、単純に関数の実行→返り値を検証 というブラックボックステストを行えるような設計に直すべき。
- 処理待ちしてやりさえすればいいような場合、処理待ちのための機能を持ったテスティングフレームワークを使うと、単純な非同期処理なら簡単にブラックボックステスト化できる。
- 色々な副作用を伴う機能や、状態遷移があるような機能をブラックボックステストできるようにしようと思うと、「内部で状態の遷移のログを取っておいて、最後にそのログの内容が期待通りになっているかどうかを検証する」という風な形にならざるを得ない。
- ということをやろうと思うと、本番用のコードの中に「ログ取り用の処理」のような「実際に使う場面では無駄」なコードが増えていってしまう。
- テストしやすくするためにテスト対象の実装に手を入れるのはよくあることだし、そうやって手を入れた結果として関数が小さな単位に分割されていったり関数名と入出力の対応が分かりやすくなっていったりするのなら、それによって動作が安定するようになったりコードのメンテナンス性が高くなったりするから、いいことだ。でも「テストのためだけの実装」が増えていって、動作が不安定になったりコードのメンテナンス性が落ちたりするのでは本末転倒だ。
- 色々な副作用を伴う機能だったり、非同期で処理するような機能だったり、1回の実行で複数の状態を遷移する機能だったり、という風に、単純に関数の実行→返り値を検証 とするだけではテストできない機能もある。
- ブラックボックステストにし続けるためのコストが、本来の実装に悪影響を及ぼすようなレベルになってしまったら、そろそろホワイトボックステストに移行していい頃合いだ。
- 検証対象の機能の粒度が大きくなってくると、これはもう避けられない事と考えた方がいい。
自分は今まで、とりあえずユニットテストに注力していて、ある意味脅迫観念的な勢いで、ブラックボックス度合いを高くする事を心がけてた。今まではそれでだいたい問題なかった。でも最近になって、ブラックボックステストにしようとすると無理があるというケースにぶち当たるようになった。1つの機能の中でコロコロと遷移する内部状態を、どうにかして検証したいというようなケースが出てきた。
それですとうさんに相談したら、そういう時はモックを使えばいいと言われた。でも、話を聞く限りだとモックというのはテスト対象の実装の中の処理の流れを追う物のようなので、それじゃブラックボックステストにならないじゃないかと思った。それをそのまま言ったら、確かにテストはできるだけブラックボックステストになってた方がいいけど、機能テストやインテグレーションテストのような粒度の大きな単位のテストでは、処理の中で起こる様々な出来事や副作用を色々モニタリングして、すべての処理が期待通りに動いているかどうかを検証しないといけないから、必然的にホワイトボックステストにならざるを得ないと言われた。
それを聞いて、目の覚めるような思いをした。そうか、ブラックボックステストとホワイトボックステストの使い分けはそこが基準になるのか、と。今まで自分がホワイトボックステストを書かずに済んでいたのは、状態の遷移を伴うような機能を作る必要がなかったからだったんだ、テストをどうも書きにくいなあと思っていた機能は本当はホワイトボックステストにしたほうがいい物だったんだ、と。
そんなわけでUxUにモックの機能を実装した。
「JavaScript Mock」で検索するとJSMockとjqmockが上位に出てきたので、最初はそれらを参考にするように(メジャーな実装があるんだったらそれをそのまま取り入れるなりAPIを合わせるようにするのが望ましい)と言われたんだけど、ドットで繋げるメソッドチェインの記法がガンガン出てきて頭パンクした。
もう少し下の方までスクロールするとMockObject.jsというのが出てきて、こっちはファイル全体で3KBに満たない小さなライブラリなので、まずはここから始めることにした。何せコードが短いから、読むのもそんなに苦にはならない。モックの概念を言葉で説明されてもさっぱりだったけど、一通りの処理の流れを見たら、「モックというのは一体何をやらなきゃいけないのか」「どういう振る舞いが期待されているのか」ということがよく分かった。
MockObject.jsと同等の機能を一通り実装した後でもう一度JSMockの方を見たら、なるほどこれはこういう意味だったのかというのがやっと分かった。サンプルコードを見ても、モックという物の意味をそもそもよく知らない時点では、どこからどこまでがJSMockの部分なのかさっぱり分からなかったんだよね。ということで、MockObject.jsに加えてJSMock互換のAPIも付け加えてみた。jqunitの方は……もう別言語だからシラネ。
あと有名なのはJsMockito? これも頑張ったらできるかなあ、というかMITライセンスだしそのままぶち込んだ方が早いか……