Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

テキストファイルの中に書いたinclude文をsedで解決する - Mar 02, 2017
このエントリはQiitaとのクロスポストです。
複数のファイルに共通する部分があるとき、共通箇所をまとめて切り出しておいて、各ファイルからはそれらを参照するだけにする、というのはよくある話です。C言語なら#include <stdio.h>という書き方をしますし、Web制作をやる人なら、CSSの@import規則をご存じだと思います。
しかしたまに、これに似たことを静的なファイルで行って「include文の位置に参照先のファイルがそのまま埋め込まれたファイル」を作りたいという場面が出てきます。
この記事では、そんな「静的なファイルを生成するために、ソースとなるテキストファイルに書かれたinclude文をシェルスクリプトで処理して、参照先ファイルの内容をその位置に埋め込んだ結果のファイルを得たい」というニーズに対する、なるべく効率のよい実現方法を模索してみます。
やりたいこと
以前、さくらのレンタルサーバーの一番安いプランでWebサイトを公開するノウハウという記事で、「ssh接続できない月額129円の激安レンタルサーバーでも、手元にLinuxな環境があるならコマンドラインのFTPクライアントとシェルスクリプトでrsyncっぽいことができるよ! ついでに色々前処理もさせられるし、シス管系女子のサイトのようにチープな静的コンテンツだけのサイトなら全然余裕で運用できちゃう! やったね!」という事例をご紹介しました。
その際にやりたかった前処理のひとつに前述のinclude文があり、全ページで共通のヘッダやフッタを
html/_parts/metadata.html(共通パーツ):
<meta charset="UTF-8">
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@piro_or">
<meta name="twitter:creator" content="@piro_or">
...
こんな風に断片ファイルとして切り出して用意しておいて、HTMLファイルの中に
html/index.html(ソースファイル):
<!DOCTYPE html>
<html lang="ja" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
<head prefix="og: http://ogp.me/ns# fb: http://ogp.me/ns/fb# article: http://ogp.me/ns/article#">
<!--EMBED(metadata.html)-->
<title>シス管系女子って何!? - 【シス管系女子】特設サイト</title>
...
のように書いておき、アップロード直前に
html_resolved/index.html(埋め込み後):
<!DOCTYPE html>
<html lang="ja" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
<head prefix="og: http://ogp.me/ns# fb: http://ogp.me/ns/fb# article: http://ogp.me/ns/article#">
<meta charset="UTF-8">
<meta name="twitter:card" content="summary_large_image">
<meta name="twitter:site" content="@piro_or">
<meta name="twitter:creator" content="@piro_or">
...
<title>シス管系女子って何!? - 【シス管系女子】特設サイト</title>
...
のように解決する、という事をしていました。
良くない実装例
最初に先の記事を公開した時の実装は、以下のようなものでした(実際にはちょっと違う書き方でしたが、要旨としてはこんな感じ、ということで)。
build.sh:共通パーツを埋め込む:
#!/bin/bash
# 環境によってsedで拡張正規表現を使うためのオプションが違うので、
# egrepコマンドのように使える「$esed」を定義しておく。
case $(uname) in
Darwin|*BSD|CYGWIN*)
esed="sed -E"
;;
*)
esed="sed -r"
;;
esac
rm -rf html_resolved
cp -r html html_resolved
# include文の検出用正規表現。
# ファイル名部分は、後方参照で取り出せるように`()`で囲っておく。
embed_matcher='<!-- *EMBED\( *([^) ]+) *\) *-->'
# 処理対象のファイル(include文があるファイル)を検索する。
egrep -r \
--include='*.html' \
"$embed_matcher" \
html_resolved |
cut -d ':' -f 1 | # ファイルパスだけを取り出す。
uniq | # 1ファイルの中で何カ所も見つかる事があるので、重複を取り除く。
while read path
do
# 見つかった各ファイルに対して処理を行う。
echo "updating $path"
# ファイルを退避し、
mv "$path"{,.tmp}
# ファイルの内容を1行ずつスキャンする。
# `IFS= read -r`とすることで、行頭・行末の連続する空白文字や
# 行の中のエスケープ文字を保持する。
cat "$path.tmp" | while IFS= read -r line
do
# include文がある行だったら、
if echo "$line" | egrep "$embed_matcher" 2>&1 > /dev/null
then
# 埋め込み対象のファイルの内容をcatして、
# リダイレクトで書き出す。
parts_name="$(echo "$line" |
$esed -e "s/^.*$embed_matcher.*/\\1/")"
cat "html/_parts/$parts_name" >> "$path"
else
# それ以外の行はそのまま書き出す。
echo "$line" >> "$path"
fi
done
rm "$path.tmp"
done
これでも一応目的は達成されていたのですが、以下のような問題が残ってしまっていました。
- ソースの1行ずつに対してBashの
whileループを回すので、とにかく遅い。 - 行の中にinclude文があると、include文の位置ではなくその次の行にファイルが埋め込まれる。
1は、処理対象のファイルの行数とファイル数が増えるごとに大きな負担となります。前の記事を書いた時には「変更が無かったファイルは無視する」という別方向からの対策を取ってみましたが、それでも全ファイルを対象に処理し直す時にはずいぶん待たされてしまいます。
2は、とりあえず今のところ問題にはなっていませんが、include文をHTMLのコメントの形式にしたので、もしかしたらこの制約の事を忘れて行中に書きたくなってしまうかもしれません。その時に「えっそんな制約あったなんて……」と戸惑う羽目になる前に、なんとかできるものならなんとかしておきたいところです。
より良い実装
その後長らくそれっきりになっていたのですが、仕事の中でまた似たようなことをやりたい場面(Firefoxの法人導入では管理者による設定を静的なJavaScriptファイルとして用意するのですが、「大部分は共通だけれども一部分だけが異なる」という設定ファイルを複数種類用意する必要が生じたのでした。共通部分を括り出すのでなく、ソースファイルに書かれたプレースホルダの位置に、環境ごとの別のソースファイルの内容を埋め込んで各環境ごとの静的なファイルをビルドしたい、という感じです)が出てたので、これを機にもっとマシなやり方を探してみました。すると、sedのrコマンドというまさにこういう事をやるためにあるような機能の情報が見つかりました。
ということで、ここからがこの記事の本題です。
マッチした箇所に他のファイルの内容を埋め込む、を高速にやる
sedのrコマンドは、「カーソル行の直後(次の行の直前)に別のファイルの内容を読み込んで挿入する」という物です。パターンマッチと組み合わせれば、「include文をパターンマッチで見つける→見つけたinclude文の箇所にinclude対象の外部ファイルの内容を埋め込む」という事もできるはずです。
例えば、最初に示した例をべた書きするとこうなります。
$ cat html/index.html |
sed '/<!--EMBED(metadata.html)-->/r html/_parts/metadata.html' \
> html_resolved/index.html
sedの機能なので、Bashのwhileループと比べると圧倒的に高速です。これで、問題の1つ目の「とにかく遅い」という点が解消されます。やりましたね!
マッチした箇所の次の行、ではなく、マッチしたまさにその箇所に他のファイルの内容を埋め込む
ただ、まだ問題はもう1つ残っています。sedのrは「マッチしたまさにその箇所」ではなく「マッチした箇所が含まれる行とその次の行の間」にファイルの内容を出力するため、行の中程にinclude文があると「include文の前の文字列→include文の後の文字列→参照されたファイルの内容→次の行」という結果になってしまいます。
この問題を解消するには、include文の後で必ず改行するように事前処理してしまうのが手っ取り早いです。
$ cat html/index.html |
$esed "s/($embed_matcher)( *[^$])/\1"\\$'\n''\3/g' |
sed '/<!--EMBED(metadata.html)-->/r html/_parts/metadata.html' \
> html_resolved/index.html
何だかゴチャゴチャ書いてあって分かりにくいですが、置換の指定としては以下のような内容になっています。
- 置換前→
(<include文>)(<改行と空白以外でinclude文より後の文字列>) - 置換後→
<マッチしたinclude文><改行文字><include文より後の文字列> - 行内のマッチ箇所をすべて置換(
gフラグ)
sedで置換後の文字に改行文字を含めれば行の途中で改行することができますが、それには色々と工夫が必要です。詳細はsedで改行を出力するをご覧下さい。
このように置換してからsedのrでinclude文を処理すれば、ちゃんと「include文の前の文字列→参照されたファイルの内容→include文の後の文字列→次の行」という順で出力されるようになるわけです。
ファイル内のすべてのinclude文を処理する
ここまでのコマンド列にはinclude文を解決するための指定をべた書きしていましたが、実際には任意のファイルでいろんなファイルに対するinclude文を処理する必要があります。後方参照でsed -r '/<!--EMBED\((metadata.html)\)-->/r html/_parts/\1'みたいなことができると楽なのですが、残念ながらsedのrコマンドの読み込み対象ファイルの指定には後方参照は使えません。
解決策としては、sedを実行するコマンド列をsedで組み立てるという方法があります。
$ embed_matcher='<!-- *EMBED\( *([^) ]+) *\) *-->'
$ embed_mark_to_resolver="s|($embed_matcher)| -e '/\\1/r html/_parts/\\2'|"
$ cat html/index.html |
egrep -o "$embed_matcher" |
sort |
uniq
<!--EMBED(metadata.html)-->
<!--EMBED(footer.html)-->
<!--EMBED(header.html)-->
...
grepやegrep(grep -Eと同等)に-oオプションを指定すると、「マッチした文字列がある行」ではなく「マッチした文字列そのもの」、ここではinclude文の部分だけが出力されます。それをsed -r "s|($embed_matcher)| -e '/\\1/r html/_parts/\\2'|"で置換して-e 'sedスクリプト'というコマンドラインオプションに変換すると、こうなります。
$ cat html/index.html |
egrep -o "$embed_matcher" |
sort |
uniq |
sed -r -e "$embed_mark_to_resolver"
-e '/<!--EMBED(metadata.html)-->/r html/_parts/metadata.html'
-e '/<!--EMBED(footer.html)-->/r html/_parts/footer.html'
-e '/<!--EMBED(header.html)-->/r html/_parts/header.html'
...
この出力に対してtr -d '\n'で改行を削除し(1行に繋げ)てsedのコマンドライン引数に指定すれば、ファイル内のすべてのinclude文を一気に処理することができます。
$ resolve_embedded_resources="sed $(cat "$path" |
egrep -o "$embed_matcher" |
sort |
uniq |
$esed -e "$embed_mark_to_resolver" |
tr -d '\n')"
$ cat html/index.html |
$esed "s/($embed_matcher)( *[^$])/\1"\\$'\n''\3/g' |
eval "$resolve_embedded_resources" \
> html_resolved/index.html
ちなみに、-eオプションの指定の中には丸括弧など拡張正規表現では特別な意味を持つ文字があるので、これらは本来スケープする必要があります。が、$esedではなくsedを使うようにすればエスケープは不要です。
$resolve_embedded_resourcesと直接書くのではなく、わざわざevalコマンドを使ってeval "$resolve_embedded_resources"と書いているのは、組み立てたコマンドラインオプションの'が値の一部にならないようにするためです。というのも、そのままパイプラインの中に
cat ... | $resolve_embedded_resources | ...と書くと、シェル変数が展開されてsed -e "'/<!--EMBED(metadata.html)-->/r html/_parts/metadata.html'" ...のように書かれた扱いとなってしまい、sedに「'なんてコマンドは無い」と言われてしまからです。evalを使えば、指定文字列を改めてシェルのコマンド列としてパースするため、sed -e '/<!--EMBED(metadata.html)-->/r html/_parts/metadata.html' ...と書いたのと同じに扱われるようになります。
また、これだけだとinclude文自体がソースの中に残ってしまうので、ついでにそれらを消す置換操作の指定も加えるとこうなります。
$ embed_mark_to_resolver="s|($embed_matcher)| -e '/\\1/r html/_parts/\\2' -e '/^ *\\1 *$/d' -e 's/ *\\1 *//'|"
1つのinclude文から3つの-eオプションができる形ですね。
さらに、これだとマッチしたinclude文の中にファイルパスのデリミタの/が入った時に破綻してしまうので、マッチングパターンの正規表現を囲う文字を/から;に変えておきます。
$ embed_mark_to_resolver="s|($embed_matcher)| -e '\\\\;\\1;r html/_parts/\\2' -e '\\\\;^ *\\1 *$;d' -e 's; *\\1 *;;'|"
sコマンドでは単に;で囲うだけでいいですが、rコマンドとdコマンドについては\;マッチングパターン;という風に最初に\を付ける必要があります。それをまた全体として1つの文字列の中に入れているので、エスケープがたくさん並ぶ読みにくいスクリプトになってしまいました……まぁこれはしょうがないです。
まとめ
以上を踏まえて前述のスクリプトの例を書き直すと、こうなります。
build.sh:共通パーツを埋め込む(改良版):
#!/bin/bash
case $(uname) in
Darwin|*BSD|CYGWIN*)
esed="sed -E"
;;
*)
esed="sed -r"
;;
esac
rm -rf html_resolved
cp -r html html_resolved
embed_matcher='<!-- *EMBED\( *([^) ]+) *\) *-->'
embed_mark_to_resolver="s|($embed_matcher)| -e '\\\\;\\1;r html/_parts/\\2' -e '\\\\;^ *\\1 *$;d' -e 's; *\\1 *;;'|"
egrep -r \
--include='*.html' \
"$embed_matcher" \
html_resolved |
cut -d ':' -f 1 |
uniq |
while read path
do
echo "updating $path"
resolve_embedded_resources="sed $(cat "$path" |
egrep -o "$embed_matcher" |
sort |
uniq |
$esed -e "$embed_mark_to_resolver" |
tr -d '\n')"
mv "$path"{,.tmp}
cat "$path.tmp" |
$esed "s/($embed_matcher)( *[^$])/\1"\\$'\n''\3/g' |
eval "$resolve_embedded_resources" \
> "$path"
rm "$path.tmp"
done
筆者が普段使用している環境で新旧それぞれのスクリプトをtime ./build.sh -fという感じで実行して計測してみたところ、
| 環境 | 改修前のrealtime | 改修後のrealtime |
|---|---|---|
| Ubuntu on Let's note CF-SX3 | 3.217秒 | 0.644秒 |
| Raspbian on Raspberry Pi2 Model B | 20.072秒 | 2.475秒 |
という感じで実時間で5~8倍の高速化となりました。ラズパイでも、カジュアルに全ファイルを処理させても気にならない程度まで高速になっています。万歳!
sedやawkだけでも頑張ればこういう事ができるのかもしれません。でも、ごく基本的な機能だけしか知らなくても「コマンドの実行結果でコマンド列を作る」という一工夫によってできる事の幅はかなり広がると思います。実際、この記事に「grepの結果をcut | uniqで加工しなくてもgrep -lでいける」というフィードバックを頂きましたが、これもまさに「grepの-lオプションを知らなくても、基本的な文字列加工コマンドの組み合わせで目的は達成できる」という事の一例と言えるでしょう。
この記事をご覧になった皆さんも、「自分はどうせ基本的な使い方くらいしか知らないから……ガッツリ覚えるつもりもないし……」と卑屈にならず、ぜひ柔軟な発想で問題を解決してみてはいかがでしょうか?
別解:Cプリプロセッサ(cppコマンド)を使う
ここまで「include文のようなことをsedでやる」という事を頑張ってみましたが、C言語のプリプロセッサ向けのinclude文そのものと同じ仕様でよければ、それこそCプリプロセッサをそのまま使うという方法もあります。
C言語のプリプロセッサはcppというコマンドとして単体で使う事ができ、UbuntuやDebianであればその名もcppというパッケージでインストールできます。Gemのパッケージ等でバイナリをビルドする必要がある物をインストールする際の依存関係で既にインストールされているという人も多いのではないでしょうか。これがインストールされている環境であれば、
html/index.html(ソースファイル):
<!DOCTYPE html>
<html lang="ja" xmlns:og="http://ogp.me/ns#" xmlns:fb="http://www.facebook.com/2008/fbml">
<head prefix="og: http://ogp.me/ns# fb: http://ogp.me/ns/fb# article: http://ogp.me/ns/article#">
#include "html/_parts/metadata.html"
<title>シス管系女子って何!? - 【シス管系女子】特設サイト</title>
...
このようにソースに書いておいて
$ cat html/index.html |
cpp -P \
> html_resolved/index.html
と実行すれば、まさにC言語のソースと同じ要領でinclude文を処理した結果を得る事ができます(cppコマンドの-Pオプションは、プリプロセッサの行番号情報を出力しないようにする指定です。これを指定しないと、# 1 "<command-line>"やら# 1 "html_resolved/index.html" 1やらといった処理中のデバッグ情報的なメッセージまでが出力に含まれてしまいます)。
もちろん、include以外の構文も使えます。ただ、たまたまプリプロセッサ向けの書き方と同じ文字列があると意図せず処理されてしまうというリスクはあります。自分はC言語には詳しくなくて地雷を踏むのが怖いので、しこしこsedで頑張ろうと思います……
GitHubが落ちてても慌てずに済む、SSHとGitだけでのPush/Pull - Dec 24, 2016
このエントリはGit Advent Calendarとのクロスポストです。(→Qiitaの方の投稿)
今日の記事では、「SSHって何?」や「SSHは知ってるし時々使うけど、普段そんなに使う機会は無い」くらいのレベルの方を対象に、SSHとGitの組み合わせだけでこんな事もできるんですよ!という事をご紹介します。アドベントカレンダー的には最後の方の日なのに初心者向けの話で恐縮ですが、まあせっかくなのでおつきあい下さい。
シェルスクリプトの中でjoin()とsplit()相当の事をやる - Dec 15, 2016
このエントリは以下のエントリのフォローアップです。
(また、Qiitaにもクロスポストしています。)
結論を先に書くと、シェルスクリプトの中で普通のプログラミング言語で文字列を区切り文字で分割して配列にする操作、いわゆるsplit()相当の事はtr '区切り文字' '\n'でできます。その逆の、配列を結合して1つの文字列にする操作、いわゆるjoin()相当の事はpaste -s -d '区切り文字' -と覚えておくのが筆者的にはオススメです。
(ちなみに、GNU coreutilsのコマンドでjoinという物がありますが、これは配列のjoin()ではなく、SQLで言うところのINNER JOINとかOUTER JOINとかの方の文脈の「join」に対応する物です。この記事の話とは関係ないので、忘れて下さい。)
以下、どういう場合にそれが言えるのかという事と、その理由の解説です。
絵文字✨とTwitter Bot🤖と私👤とEmoji Editor📝 - Dec 15, 2016
このエントリは絵文字Advent Calendar 2016とのクロスポストです。(→Qiitaの方の投稿)
この記事では、自分が絵文字込みのテキストを楽に編集するために作ったEmoji Editorという簡単なツールを紹介します。
PCでパレットから絵文字を入力したいんです……😭
唐突ですが皆さん、どうやって絵文字を入力されてますか?
Android版のGoogle日本語のように絵文字のパレットが付いていたり、macOSの日本語入力のように標準辞書に入っていて普通に「すし」と入れて変換すれば「🍣」になったりする環境もあるようなのですが、自分が主に使っているWindows 7+ATOK2016の環境とUbuntu 16.04LTS+ATOK X3の環境では良い方法がなさげです。自分は絵文字はパレットから選択したい派、というか顔文字に対応する読みをいちいち覚えてられない派なので、やるなら一覧の中からぽちぽちクリックして選びたいです。しかしATOKに付属の文字パレットというユーティリティの分類には「顔」みたいなグループ分けが無いため、Unicode絵文字を使おうと思うとUnicodeの表のあっちこっちを行き来しながら探さないといけません。(最新のATOK2017ではこの辺どうなんでしょう?)
また、これはカラー絵文字のフォントが無いという古い環境だからのようですが、文字パレット上だけでなくテキストエディタ上でも絵文字は白黒表示です。自分が絵文字を使いたいのは主にTwitterでの投稿なので、見るならTwitter上でどう見えるかが分からないと安心して使えません。
元々絵文字を使う習慣が無かった自分が絵文字に触れる機会が増えたのは、「シス管系女子」の広報用Twitterアカウント(みんとちゃんbot)がきっかけです。いつもの自分のノリでやると堅すぎると思ったので、みんとちゃんbotの発言についてはあえて絵文字を入れて柔らかい印象を持ってもらえるようにしたい、という下心ドリブンです。
当初はAndroidのGoogle日本語入力から絵文字を入れていましたが、運用のためのbotスクリプトを作成して、発言データにするためのテキストを大量に用意する段階になってPC上で作業に入ろうとしたときに、前述のような状況に気が付きました。
そこでとりあえずTwitter絵文字が使えるパレットを探してみた所、テスト用にちょっと投稿するだけならTwitterの絵文字をデスクトップPCから使おう! Ver2というサービスで絵文字の入力自体はできる事が分かりました。が、このページは既に作成済みのデータの編集には使えません。やはりここは、Twitter絵文字を含んだプレーンテキストをWYSIWYGで編集できるツールが欲しくなるところです。
探し方が悪かったのかもしれませんが、自分はその時「まさにこれだ!」と思える物を見つけられなかったため、無いなら作るか……という事で作りました。その名もEmoji Editor(名前が安直すぎる)。HTMLファイル1つだけで完結する、フレームワークも何も使ってないSPAとも呼べないような代物です。
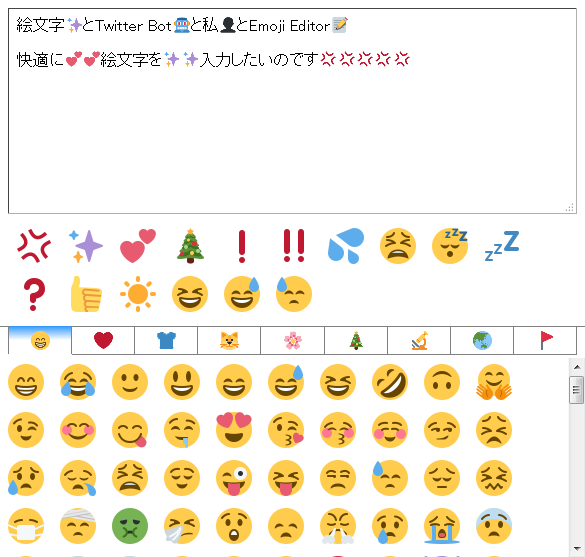
このエントリの公開を機に、GitHubにリポジトリを作りましたので、forkしたりプルリクしたりして頂ければ幸いです。
プログラマーの君! 騙されるな! シェルスクリプトはそう書いちゃ駄目だ!! という話 - Dec 08, 2016
このエントリはShell Script Advent Calendarとのクロスポストです。(→Qiitaの方の投稿)
前回は自作のBashスクリプト製Twitterクライアントをネタに実装を解説しましたが、今日は他の言語で多少のプログラミング経験はあるんだけど、どうにもシェルスクリプトは苦手だ……という人のための、シェルスクリプトによるプログラミングの勘所を解説してみようと思います。多分、プログラミング入門レベルの人や上級レベルの人よりは、中級レベルにいる人や、初級から中級以上に成長したいという感じの人にとって役に立つ話だと思います。
結論から先にいうと、「引数」と「配列」の事を忘れればシェルスクリプトはグッと書きやすくなります。というおはなしです。タイトルからして期せずして前の日の方の話の全否定になっちゃいました。ごめんなさい、他意は無かったんです……
シェルスクリプト(Bash)で作るTwitter bot - Dec 05, 2016
このエントリはチャットボット Advent Calendarとのクロスポストです。(→Qiitaの方の投稿)
チャットボット Advent Calendarをご覧になっているような方々はフレームワークやニューラルネットでディープラーニングなAIといった最新のbot事情に関心の強い方が多いと思うのですが、今日の記事は時代に逆行しまくって、Bashスクリプトで昔ながらの人工無脳botを作りましたというお話です。
この記事では以下のことを書いています。
- Bashスクリプト製Twitter bot tweetbot.shの使い方説明
- tweetbot.shの実装の解説
- マルチプロセス設計
- 親プロセスが停止させられたら子孫プロセスまでまとめて停止する
- 一定間隔でREST APIを呼ぶ(ポーリング)
- 独り言や返事の発言内容の選択
- Twitter以外の他のサービスへの応用
シェルスクリプト(Bash)で作るTwitterクライアント - Dec 05, 2016
このエントリはShell Script Advent Calendar 2016とのクロスポストです。(→Qiitaの方の投稿)st
Linux Advent Calendarの方にGUIアプリのスクショを定期的にSlackに流すシェルスクリプトの話でエントリーしたのですが、Shell Script Advent Calendar的にはそれをこっちを投稿した方が良かったかもと今更思いつつ、今日は別の話題です。
シェルスクリプト製Twitterクライアントには恐怖!小鳥男やtweet.sh(同名の別実装)などいくつか実装例がありますが、自分も2015年末頃からtweet.shという汎用のTwitterクライアントを開発しています。この記事ではtweet.shをネタに、以下の事を解説します。
- Bashスクリプト製Twitterクライアント tweet.shの簡単な使い方の解説
- tweet.shの実装の解説
- 文字列をBashと
nkfといくつかの一般的なコマンドでURLエンコードする - たくさんあるパラメータを見やすい形で定義する
- 改行区切りのパラメータのリストを
キー1=値1,キー2=値2,...の形に変換する - OAuth 1.0認証によるWeb APIアクセスの、ほぼ0からの実装手順
- 文字列をBashと
さくらのレンタルサーバーの一番安いプランでWebサイトを公開するノウハウ - Dec 04, 2016
このエントリはさくらのアドベントカレンダー(その2)とのクロスポストです。(→Qiitaの方の投稿)
この記事では自分で自由に使えるLinuxなサーバーかPCがあるという事を前提として、さくらのレンタルサーバーのライトプランで静的コンテンツだけのWebサイトを公開・運用する際のノウハウをご紹介します。
なお、自分では調べていませんが、スクリプト内で使用しているlftp等のコマンドがHomebrew等でインストール可能なのであれば、macOS(OS X)でもこの方法をそのまま使えるかもしれません。
定期的にブラウザのタブを再読み込みしてスクリーンショットをSlackに投稿するシェルスクリプト - Dec 03, 2016
このエントリはLinux Advent Calendar 2016とのクロスポストです。(→Qiitaの方の投稿)
連載の方で書くには粒度の大きい話題だったので公開するのにいい場所はないかなあと思っていたらLinux Advent Calendarという名前を見かけて、まだ空きがあったので「これや!」と思って勇んでエントリーしたのですが、埋まってみると皆さん当たり前ですがカーネルの話中心で、そんな中で一人だけディストリビューションより上のレイヤの話でなんかほんとごめんなさい……シェルスクリプトアドベントカレンダーとかの存在を知ったときにはもう後の祭りでして……
そんな感じで空気まるで読めてない内容ですが、生暖かい目で見て頂けましたら幸いです。
GUIアプリを制御するシェルスクリプト
先日参加したイベントの懇親会で、「シス管系女子」の本をご覧になった方から「Google Analyticsのグラフを何分間隔とかでスクリーンショットとってSlackに流したいんだけど、本にはそういう話は書かれてなかった……」というご相談を頂きました。

本の中では主にSSHでLinuxのサーバーにリモート接続してコマンドで操作する時の話を取り扱っているため、GUIアプリの話はあまり、というか全然取り扱っていません。しかし、何かしら方法はありそうな気がします。
という話をつぶやいたところ、フォロワーの方にヒントを教えて頂けて、最終的にそれらしいことを実現できる筋道が立ちました。なのでこの場を借りて、得られた知見を共有したいと思います。
シェルスクリプトでだいたい1時間の間隔であれをやる - Jan 03, 2016
前のエントリに引き続いて、またシェルスクリプトの話。
「1時間間隔で決まった処理を行う」という目的だと、普通に考えたらまあcrontabを使う場面ですよね。
だから素直にそうしときゃいいんだけど、シェルスクリプト製のTwitter用botで自発的な自動投稿をやらせるにあたってどういうわけか「きっかり同じ時間間隔じゃなくて、確率でちょっとだけ揺らぎを持たせたい。その方が人間くさいよね。」と思ってしまって、それをやるのに一苦労しました……という話です。これは。
目指す状態
そもそも「きっかり同じ時間間隔じゃなくて、ちょっとだけ揺らぎをもって定期実行したい」というのは、一体どういう状態のことを指しているのか。 これをはっきりさせないことには話が始まりません。
僕が思ってる事をアスキーアートで図にすると以下のようになります。
00:00 基準時刻
|
00:15
|
00:30
|
00:45
|  ̄\
01:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
01:15
|
01:30
|
01:45
|  ̄\
02:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
02:15
|
02:30
|
人間の行動で言うと、こんな感じ。
- 時計を持って「1時間に1回これをやるように」と言われて、時計を見てその時刻に近かったらそれをやる。
- ちょっと早くても「まぁもうやっちゃってもいいか」ということでやる。
- ちょっと遅くても「まぁこのくらいの遅れは大丈夫でしょ」ということでやる。
- 「やらない」という選択肢は無い。「やべっ時計見落としてた!」と気がついたらその時点で慌ててそれをやる。
ちょっとばかり時間にルーズな人の取るような行動、という事ですね。
これをもうちょっと厳密に、コンピュータにも分かりやすいであろう表現に直すと、以下のように言えるでしょうか。
- 目標時刻の前後N分の範囲の時間帯を、処理を実行する可能性がある時間帯とする。
- それより早かったり遅かったりしたら実行しない。
- 目標時刻に近ければ近いほど実行の確率は高く、遠ければ遠いほど実行の確率は低い。
- 目標時刻ちょうどで最大確率、目標時刻のN分前およびN分後の時点で最低確率とし、その間は確率が線形に変化するものとする。
- ただし、その範囲の時間帯が過ぎようとしている時にまだ1回も処理が実行されていなければ、時間帯の終わりで必ず実行する。
- 計算は分単位で行う。(cronjobでも1分未満の指定はできないので)
実行確率をパーセンテージで算出できれば、あとは前のエントリでやった「何パーセントの確率であれをやる」がそのまま使えます。
となると、問題は「どうやって実行の確率を計算するか」という話になります。
今の時刻が目標時刻から何分ずれているかを計算する
先の定義に基づいて「ある時点での実行確率」を計算しようと思った時に、時刻を時刻の形式のまま扱おうとするとややこしいというか自分にはお手上げなので、「その日の0時0分を起点として、そこから何分経過したか」を使って計算していこうと思います。
そのために、こんな関数を用意しました。
# "03:20"のような時刻を与えると、00:00からの経過分数を出力する
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
これに与える現在時刻は、コマンド置換とdateコマンドを使って$(date +%H:%M)とします。
例えば現在時刻が07:58なら、以下のような出力が得られます。
$ time_to_minutes $(date +%H:%M)
478
これを「処理を実行したい時間間隔(分)」で割った余りを得ると、現在時刻が目標時刻から何分ずれているかが分かります。 60分間隔ならこうです。
$ interval=60
$ lag=$(( 478 % $interval ))
$ echo $lag
58
58分ずれている……という結果ですが、これはどっちかというと「目標時刻からマイナス方向に2分ずれている」と扱いたいところです。 なので、実際のずれが実行間隔の半分よりも大きい場合は「マイナス方向にN分のずれ」と見なすようにします。
$ half_interval=$(( $interval / 2 ))
$ [ $lag -gt $half_interval ] && lag=$(( $interval - $lag ))
$ echo $lag
2
これで「目標時刻ピッタリから何分ずれているのか」が求まったので、次はいよいよ確率の計算です。
今の時刻での実行確率を計算する
目標時刻ピッタリで確率100%としてしまうとそこで必ず実行されてしまうので、目標時刻ちょうどでの最大の確率を90%、許容されるずれの最大時点での最低の確率を10%とすることにします。
全体の振れ幅は10%から90%までの「80」ですので、「目標時刻ちょうどで100%、目標時刻からのずれが許容範囲の最大になった時を0%」とした割合に80をかけた結果に10を足せば、確率は10%から90%までの範囲に収まることになります。 式にすると、こうです。
$ probability=$(( (($max_lag - $lag) / $max_lag) * 80 + 10 ))
$ echo $probability
10
……おや? どうも計算結果がおかしいですね。
実は算術展開の$((~))は整数のみの計算なので、計算の過程で小数が出てくると小数点以下切り捨ての計算になってしまうのです。
こうならないようにするには、小数が出てこないように注意して計算するか、小数があっても大丈夫な計算方法を使う必要があります。 例えば、先に100倍してパーセンテージを求めてから後で100で割るという方法を取るなら以下のようになります。
$ probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
$ echo $probability
58
小数として計算するのであれば、数値計算用のコマンドのbcを使います。
これは、標準入力で与えられた式の計算結果を出力するコマンドなのですが、scale=1;という指定で計算時の小数点以下の桁数を指定すると、小数部を考慮した計算結果を返してくれます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc)
$ echo $probability
58.0
ただし、if [ ... ]での条件分岐では今度は整数しか扱えないので、出力される計算結果の小数部は取り除いておく必要があります。
これはsedで行えます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc | sed -r -e 's/\.[0-9]+$//')
$ echo $probability
58
ということで、ここまでをまとめて「算出した実行確率を出力する関数」にしてみましょう。
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
# 最小の実行確率より小さい時=実行する可能性がある範囲の
# 時間帯の外の時は、確率0%とする
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
同じ時間帯では重複実行しない
単にこの確率に基づいて実行するかどうかを決めるだけだと、00:55から01:05までの範囲で「実行時刻が揺らぐ」のではなく「その範囲で、確率次第で何度も実行される」という結果になります。 そうしないためには、同じ時間帯の中での再実行を防ぐ必要があります。
そのためには、最後に処理を実行した時刻を保持しておいて、現在時刻が最終実行時刻から一定の範囲内にある時は問答無用で処理をスキップする、ということになります。 とりあえず、最終実行時刻(として、00:00からの経過時間)を保存するようにしてみます。
current_minutes=$(time_to_minutes $(date +%H:%M))
probability=$(calculate_probability $current_minutes)
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
ここで保存した値を次の実行の可否の判断時に使うのですが、「最後の実行からN分間は絶対に実行しない」という条件を加えても良ければ、以下のようにできます。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
現在時刻から最後の実行時刻を引いた結果の「最終実行時刻からの経過時間」を求めて、それが指定の範囲内であれば何もしないで終了するということです。
比較の演算子が-lt(<)ではなく-le(≦)である点に注意して下さい。
-ltで比較してしまうと、00:55に実行してから10分後の01:05ちょうどの時点で「10分未満の範囲で実行されていないので、再実行してよい」と判断されてしまいます。
ただ、これだけだと日付をまたいだ時に判定が期待通りに行われません。
最後の実行時刻が例えば前日23時ちょうどだったとすると、last_doneは23*60=1380ですが、現在時刻が00:04だったとすると4-1380=-1376になってしまって、負の数は「何分間は再実行しない」という指定=正の数よりも必ず小さいので、永遠に再実行されないことになってしまいます。
なので、現在時刻から最終実行時刻を引いた結果が負の場合は、「最終実行時から0時までの経過時間」と「0時から現在までに経過した時間」の和を「最終実行時刻からの経過時間」として使う必要があります。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
その時間帯で投稿が無い時は時間帯の最後のタイミングで必ず実行する
ここまで来たらあともう一息。 最後は「その時間帯で必ず1回は実行する」という要件です。
とはいえ、これはそんなに難しく考えなくても大丈夫。 前項の段階で「指定の範囲内の時間での再実行はしない」という判定が既に行われているので、その判定の後であれば、「実行するべき時間帯の最後の瞬間で、その時間帯の中ですでに実行済みである」という場面はあり得ない事になります。 なので、単純に「今この瞬間は、実行しても良い時間帯の範囲の最後の瞬間かどうか?」を判断して、そうであれば確率100%で実行するということにすればいいです。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
# 目標時刻からのずれを計算
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
# ずれが、許容されるずれの最大値と等しければ、今がまさに
# その時間帯の最後の瞬間である。
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
...
まとめ
ここまでのコード片を全てまとめた物が、以下になります。
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
人間くさい振る舞いをする何かを作る時の参考にしてみて下さい。
追記:もっと単純なやり方
Qiitaのクロスポストの方に頂いたコメントで、以下のようにcronjobを設定すれば良いのでは?とのご指摘がありました。
55 * * * * sleep $(( $RANDOM \% 10 ))m; (実行したい処理)
実行の可能性がある時間帯の最初の瞬間にsleepを呼び、何秒間待つかは0~10分の間でランダムに決定する。その後、やりたい処理を実行する。という方法です。
「指定の時間間隔ちょうどの実行確率を最も高くしたい」「その時間帯の最初の瞬間から最後の瞬間までの間に運用を開始した時も、すぐに動作させたい」といったいくつかの要件を除外すれば、この方法が最もシンプルですね。 というか最初この指摘を見た時には「完全に置き換え可能じゃん!」とすら思ってしまいました。 (よくよく見返して、要件のいくつかがカバーされていない事にようやく気づくレベル)
無駄に複雑な要件を全て満たそうとすると手間がかかるけれども、要件の8割9割ほどを満たせれば良いという割り切りができれば手間を大きく減らせる場合がある、「そもそも本当にその要件は必要なの?」というレベルからの再考次第で実現手法を大きく簡素化できるという、いい例だと思いました。 そのあたりの絞り込みが足りないままこの記事を世に出してしまって、お恥ずかしい限りです……。