Dec 08, 2016
プログラマーの君! 騙されるな! シェルスクリプトはそう書いちゃ駄目だ!! という話
このエントリはShell Script Advent Calendarとのクロスポストです。(→Qiitaの方の投稿)
前回は自作のBashスクリプト製Twitterクライアントをネタに実装を解説しましたが、今日は他の言語で多少のプログラミング経験はあるんだけど、どうにもシェルスクリプトは苦手だ……という人のための、シェルスクリプトによるプログラミングの勘所を解説してみようと思います。多分、プログラミング入門レベルの人や上級レベルの人よりは、中級レベルにいる人や、初級から中級以上に成長したいという感じの人にとって役に立つ話だと思います。
結論から先にいうと、「引数」と「配列」の事を忘れればシェルスクリプトはグッと書きやすくなります。というおはなしです。タイトルからして期せずして前の日の方の話の全否定になっちゃいました。ごめんなさい、他意は無かったんです……
シェルスクリプトって分かりにくい?
「あんなおもちゃみたいな物で……」
書かずに済むなら書きたくない物。わざわざ書くくらいなら、まともなスクリプト言語で使い捨てのコードを書くほうがマシ。システムの中にしぶとく残る前世紀の遺物。シェルスクリプトは、プログラミングを嗜む人達からはそう見られているような気がします。
というか、筆者自身がそうでした。「シェルスクリプトのみでアプリケーションを開発する」というユニケージ開発手法の話を初めて聞いた時は、「は? 頭おかしいんじゃないの?」「随分と趣味的なこだわりで開発してるなあ……」というのが正直な感想でした。
でもシス管系女子の連載の中でシェルスクリプト、具体的にはBashの理解を深め、さらに小規模のアプリケーションとしてTwitterクライアントやTwitter botを実際にシェルスクリプトで書いてみて、ようやく合点がいきました。自分が今までシェルスクリプトを毛嫌いしていたのは、シェルスクリプトがプログラミング言語として駄目だからなのではなく、言語特性に反した使い方をしようとしていたからなのでした。
他のパラダイムでのプログラミングを知りすぎていると、逆に分からなくなる
筆者が思うに、他の言語で以下の機能を使ったことがある人なら、恐らくシェルスクリプトの言語特性を活かしたスクリプトを容易に書けます。
- 関数
- イテレータ
- 非同期処理、特にPromiseやDeferredと言われる物
逆に、以下のような知識が念頭にあるとシェルスクリプトの言語特性を理解しにくくなると思います。
- 引数
- 配列
- オブジェクト指向
- クラス
シェルスクリプトが得意な事、不得意な事
コマンドの自動実行だけじゃない
シェルスクリプトの得意分野として真っ先に挙げられるのは、やはり、インストールスクリプトなどの「システムのコマンドを多用する手順の自動化」でしょう。特にインストールスクリプトはポータビリティが大事ですから、環境に依存しにくいシェルスクリプトは理に適っています。
ですが、コマンドを実行するだけならNode.jsでもRubyでもPythonでも大抵の言語でできます。ここで言いたいのはそういう事ではありません。
ステートレスか、ステートフルか
シェルスクリプトに適しているのは、ステートレスな処理です。ステートレスというのは内部状態を持たないということですが、具体的には、ImageMagickの画像変換処理や、curlによるRESTfulなWeb APIへのアクセスなど、「機能を1回実行したら、処理が行われて、結果が得られる。それで終わり。」という種類の仕事のことを言います。
またシェルスクリプトは、入力を受け取って加工して出力するという、フィルタ的な働きが求められる種類の仕事にも適しています。sedのような文字列加工はその代表でしょう。
逆に、シェルスクリプトはステートフルな処理にはあまり適していません。筆者が書いたTwitter botでも、ポーリング処理の部分で若干トリッキーな書き方をする必要がありました。「その言語の基本機能で素直な書き方で実現できる処理」はその言語に適していて、「様々な機能をフルに使ったトリッキーな書き方をしないとできない事」はその言語では本来想定されていない不得意な事だ、というのはどんな言語やフレームワークについても言える原則だと思います。
他の言語でのアレは、シェルスクリプトではこうやろう!
先に述べましたが、他の言語でのプログラミング経験がある人ほど、シェルスクリプトで凝ったことをやろうとして躓く気がします。筆者も、一番馴染みがある言語はJavaScript(WebアプリやNode.jsではなく、FirefoxやThunderbirdのアドオンなどが主)で、その次くらいにRubyを書いていますが、勘所が分かっていなかった時は「JSだったらこう書けるのに! キィーッ!!」とイライラする場面が多かったです。
そこで、自分が躓いていたポイントを例にとって他の言語と比較しながら「シェルスクリプトでは、それはこうやるのがベター」という事をいくつか解説してみます。キーワードは「パイプラインと標準入出力」です。
データは引数で渡さない
のっけから「は?」という感じだと思いますが、シェルスクリプトやシェル関数では引数を活用しようとするとドツボにはまります。
普通のプログラミングに慣れていると、データを渡すといえばまず引数を使う習慣が付いていると思います。しかしシェルスクリプトやシェル関数では、引数はあくまで「細かい動作を変えるための補助的な指定」としてのみ使うのがベストプラクティスだと筆者は思っています。
じゃあどうやってデータを渡せばいいんだ?という話ですが、そこで使うのが標準入力です。シェルスクリプトでは処理対象のデータはパイプラインやリダイレクトで標準入力から受け取って、処理結果は標準出力で出力するのがベストプラクティスです。
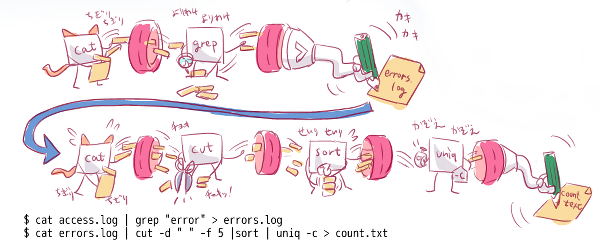
データは標準入力で受け取る
よく考えてみれば、シェルスクリプトはシェルのコマンド操作で使う書き方をそのまま使えるのが特長です。コマンド操作ではパイプラインを使うのに、シェルスクリプトやシェル関数になった途端にパイプラインを使わなくなるのはおかしな話ですよね。
Twitterクライアントの実装に含まれている「指定した文字列をURLエンコード(パーセントエンコーディング)するシェル関数」を例に説明しましょう。以下は、説明のために簡略化したバージョンです(ここでは説明のためにコードを簡略化しているので、複数行の入力を与えると1行の文字列に連結されてしまうようになっています)。
シェルスクリプトでの実装:
url_encode() {
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g'
}
実行例:
$ echo "こんにちは" | url_encode
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF
「処理対象のデータは標準入力で受け取る」という仕様にしたので、変換対象の文字列はechoで出力した物をパイプラインで渡しています。シェル関数の中で最初に実行されるコマンドのnkfには読み込み元のファイルが指定されていないため、標準入力から文字列を読み取ろうとして、結果的にこの関数自体の標準入力から文字列を受け取っています。
その後に続くコマンドも、前のコマンドの処理結果をパイプラインで受け取って処理しています。最後のsedの後にはもうパイプラインがないので、ここで結果が初めて関数自体の標準出力に渡ることになり、関数の標準出力が画面に表示されている、というわけです。関数の後にパイプラインを繋げれば次のコマンドに出力が渡りますし、リダイレクトすればファイルにも保存できます。
JavaScriptと比較する
仮にJavaScriptの文法で、「各コマンドと同名の関数で、第1引数で処理対象のデータを受け取る」という仕様でコードを書くと、以下のようになるでしょう。
引数と戻り値で愚直にデータを引き回した例:
function url_encode(input) {
return sed(
paste(
tr(
sed(
nkf(input, '-W8MQ'), // ここから評価される
's/=$//'
)
'=', '%'
),
'-s', '-d', '\0'
),
'-e', 's/%7E/~/g',
'-e', 's/%5F/_/g',
'-e', 's/%2D/-/g',
'-e', 's/%2E/./g'
);
}
関数の戻り値を次の関数に渡すという事を愚直にやると、最初にやって欲しい処理ほど内側に書く必要があって、こんな感じでどんどんネストが深くなってしまいます。
行う処理の順番通りに読めるように書くなら、変数を使って以下のように書くことになるでしょう。
行う処理の順番通りにコードを書いた例:
function url_encode(input) {
input = nkf(input, '-W8MQ');
input = sed(input, 's/=$//');
input = tr(input, '=', '%');
input = paste(input, '-s', '-d', '\0');
input = sed(input,
'-e', 's/%7E/~/g',
'-e', 's/%5F/_/g',
'-e', 's/%2D/-/g',
'-e', 's/%2E/./g');
return input;
}
各機能をメソッドチェーンで呼べるようになっていたら、以下のように書けるかもしれません。
何か便利なライブラリを使って、メソッドチェーンで処理を書くようにした例:
function url_encode(input) {
// createStringStream() の戻り値は、
// 各関数名のメソッドを持つオブジェクトとする。
// 渡されたデータは内部で保持されていて、
// メソッドを呼ぶ度にそれが加工されていく。
return createStringStream(input).
nkf('-W8MQ').
sed('s/=$//').
tr('=', '%').
paste('-s', '-d', '\0').
sed('-e', 's/%7E/~/g',
'-e', 's/%5F/_/g',
'-e', 's/%2D/-/g',
'-e', 's/%2E/./g');
}
実際にこういう事をやるためには、ここで仮定したcreateStringStream()のような機能を提供するライブラリが必要になります。事実、「ファイルの内容に対してこのように処理を適用していく」という場面を想定しているGulp.jsでは、その名もpipeという名前のモジュールを使ってこれに近い書き方をするようになっています。
シェルスクリプトらしくない書き方
むしろシェルスクリプトでは、変数にいちいち結果を代入する方が面倒です。
シェルスクリプトで、最初と同じことを引数と変数を使ってやった例:
url_encode() { # 引数で文字列が渡されると仮定
local input="$*"
input="$(echo "$input" | nkf -W8MQ)"
input="$(echo "$input" | sed 's/=$//')"
input="$(echo "$input" | tr '=' '%')"
input="$(echo "$input" | paste -s -d '\0' -)"
input="$(echo "$input" | sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g')"
echo "$input"
}
実行例:
$ url_encode "こんにちは"
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF
変数への代入とコマンド置換で同じような記述が何度も出てきてうんざりですね。ここまでやるなら、最初に1回だけechoで文字列を出力して、後はパイプラインにした方がずっと簡単です。
最初のデータの受け取りだけ引数を使った例:
url_encode() { # 引数で文字列が渡されると仮定
local input="$*"
echo "$input" |
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g'
}
結局、外部から受け取った入力を順番に加工していって、その結果を出力するという類の処理を見た目に分かりやすく、且つ効率よく書こうとすると、シェルスクリプトではこういう書き方が一番素直で楽だという事になりますし、JSの例を見て分かる通り、他の言語でもパイプライン的な仕組みを導入したくなるというわけです。
(ここでは、「見た目に分かりやすい」とは「行う処理の順番と同じ順番で書かれている」という事を、「効率よく」とは「同じ変数を何度も何度も書かなくても、暗黙的にデータが引き継がれていく」という事を指しています。)
重宝するぞ! echoとcat
ところで、コマンドにはsedやgrepのように「標準入力も受け取るし、ファイルパスの指定も受け付ける」という物と、trのように「標準入力からしか入力を受け取らない物」とがあります。でも、どのコマンドがどっちの種類なのかをいちいち覚えるのは煩雑ですよね。こういうバラバラさがシェルスクリプトの嫌な所なんだ、と思う人もいるのではないでしょうか。
でも、実は話は単純なんです。発想を逆転して、基本的に各コマンドへの入力は標準入力から行うものと思っておけばいいんです。
そこで便利なのが、「引数で指定した文字列を標準出力に出力する」コマンドであるechoと、「指定したファイルの内容を標準出力に出力する」コマンドであるcatです。変数に格納された文字列を処理したければechoから、ファイルの内容を処理したければcatからコマンド列を書き始める、という風に覚えておけば、「あれ、このコマンドってファイル指定を受け付けたっけ……?」と悩む必要はありません。
(ちなみに、「catから始めるとメモリを余計に消費するのでは?」という議論もあるようですが、実際の所は小刻みに読み込むのでそれほど大量にメモリを使う訳ではないみたいです(このレベルのメモリ消費も問題になるような前提ならそもそもシェルスクリプトでやるのが不適切と言えるでしょう……)。ちなみに、ファイルの内容をコマンドの標準入力に渡すのはcatを使わなくてもコマンド名 <ファイル名あるいは<ファイル名 コマンド名という書き方でもできますが、筆者は余計な事は憶えたくないズボラなので、いつもcatとパイプラインで済ませています。)
また、catとヒアドキュメントを併用すれば「シェルスクリプト内に複数行のテキストをリテラルとして埋め込む」ような事もできます。
ヒアドキュメントの内容を標準出力に出力する関数の例:
common_params() {
cat << FIN
oauth_consumer_key $CONSUMER_KEY
oauth_nonce $(date +%s%N)
oauth_signature_method HMAC-SHA1
oauth_timestamp $(date +%s)
oauth_token $ACCESS_TOKEN
oauth_version 1.0
FIN
}
繰り返し処理は配列ではなくイテレータで
シェルスクリプトでもう一つ鬼門になるのが繰り返し処理です。
配列のこと、忘れて下さい
普通のプログラミングに慣れていると、「繰り返し処理」と「配列」はほぼワンセットで捉えるクセが付いているのではないでしょうか。
しかし、シェルスクリプト……というかBashでの配列の取り扱いは他の言語に比べてやたら面倒です。解説の記事を見ても各要素へのアクセスや長さの取得などで特殊な記法が連発されていて、途中で投げ出したくなることうけあいです。前日の記事のbash-oo-frameworkでも、その実装を見ると配列を簡単に扱えるようにするためにかなりの労力を割いている様子が伺えます。
はい、ここで白状しておきます。筆者はBashの配列を使えません! Linuxのコマンド操作とシェルスクリプトの基礎を解説する記事のはずのシス管系女子でも、もう連載6年目に突入しようかというのに配列は完全にスルーしています。拙作TwitterクライアントやTwitter botでも配列は一切使用していません。
(連載で配列の説明をスルーしているのには理由があります。シス管系女子の連載では、紹介する技術は必ず何かの目的、何かの問題の解決のための手段として紹介するという事を心がけています。いたずらにツールや文法だけをたくさん紹介しても、それらの適切な使い道が分からないと混乱が増すだけだからです。そう考えて話を選んできた結果、「どうしても配列を使わなければ解決できない」という種類の問題を思いつけずにいるため、今の今まで配列を紹介しないままで来たという次第です。同じ理由でxargsも今のところスルーしています。)
じゃあどうやって複数の要素を持つデータを処理するのかという話なんですが、筆者はwhileループとread -rの組み合わせを多用しています。前述の「データは標準入力で受け取って標準出力で出力する」という話とワンセットで覚えておけば、大抵のことはこれでどうにかなってしまいます。シェルスクリプトでは、繰り返し処理はwhileループ(とread -r)でやるのがベストプラクティスと言っていいでしょう。
RubyやJavaScriptのイテレータ
whileとread -rの組み合わせの振る舞いは、他の言語で言う所のイテレータによく似ています。
繰り返し処理したい対象のデータについて、全体の個数のことは一旦忘れて「最初の要素を取得して処理する」という操作を繰り返して対象のデータすべてを処理する、という設計を「イテレータパターン」と言います。Rubyではeachメソッドがあるオブジェクトに対して以下のような書き方でループを回して個々のデータを処理できますが、これがイテレータです。
Rubyでのイテレータを使った繰り返し処理:
uris = [
"http://www.example.com/",
"http://www.example.net/",
"http://www.example.jp/",
]
for uri in uris do
p uri
end
ES2015などのモダンな仕様のJavaScriptでも似たような書き方ができます。
JavaScriptでのイテレータを使った繰り返し処理:
uris = [
"http://www.example.com/",
"http://www.example.net/",
"http://www.example.jp/"
];
for (let uri of uris) {
console.log(uri);
}
ところで、JavaScriptのループといえば以下のような書き方もあります。上記の記法が導入される前からJavaScriptを使ってる人なら、こっちの方が馴染みがあるのではないでしょうか。
JavaScriptでのイテレータを使わない繰り返し処理:
for (let i = 0; i < uris.length; i++) {
console.log(uris[i]);
}
この書き方と上の2つの例との最大の違いは、データの個数が出てくるかこないか、もっと言うと処理を始める前にデータの全体像が見えている必要があるか無いかです。3つめの書き方はデータの個数を条件に使った「ループを何回実行するか」という観点のコードになっているので、当然ですが事前に配列の個数が決まっていないといけません。
それに対して前2者のイテレータパターンでは、「データをすべて処理するまでループを実行する」という観点なので、データの個数は見ていないし、データの総数が不明のままでも問題なく各要素を処理できます。例えばフィボナッチ数列は無限に続く数列なので、有限長の配列としては表現できず、3番目の例の書き方でも取り扱えません。しかし、イテレータを使えば通常の処理の中で無理なく取り扱えます。
シェルスクリプトでもイテレータ
先程例として示した「指定した文字列をURLエンコードするシェル関数」は省略版ですが、実際に使用している物は以下のようになっています。
複数行の入力を受け取って、各行をURLエンコードして出力するシェル関数の実装:
url_encode() {
while read -r line
do
echo "$line" |
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g'
done
}
関数の標準入力にパイプライン経由で渡されてきたデータをwhile read -r lineで1行ずつ取り出して、echo "$line"でエンコード処理を行い標準出力に出力しています。これによって、このシェル関数は入力行すべてをきちんとエンコードできるようになっています。
複数行の入力に対する実行例:
$ cat data.txt
おはよう
こんにちは
こんばんは
おやすみ
$ cat data.txt | url_encode
%E3%81%8A%E3%81%AF%E3%82%88%E3%81%86
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF
%E3%81%93%E3%82%93%E3%81%B0%E3%82%93%E3%81%AF
%E3%81%8A%E3%82%84%E3%81%99%E3%81%BF
この例のように、シェルスクリプトやシェル関数では「1行=1単位」という構造のデータであれば何でもwhile read -rでループを回して処理できます。
(このとき、readに-rオプションを指定していることに注意して下さい。-rは標準入力の中のバックスラッシュをエスケープ文字ではなくバックスラッシュという文字としてそのまま受け取るオプションです。これを指定しておかないと、行の中に\nというテキストがあるとそれが入力の区切りの改行として解釈されてしまい、1行=1単位という構造が崩れてしまいます。なお、readは改行の前後で連続する半角スペースやタブなどの空白文字があるとそれらを取り除く仕様ですので、行頭のインデントを含んでいるデータ(何かのソースコードなど)をインデントを保持したまま取り扱う場合は、厳密に改行文字だけで区切るようにIFS= read -rと指定する必要があります。詳しくは別の記事もご参照下さい。)
イテレータと非同期処理
イテレータには非同期処理との相性が良いという特長もあります。次のデータが無い状態で次を取り出そうとしたら一旦処理を止め、新しいデータが届くのを待つという風にすれば、少しずつ渡されてくるデータを随時処理するのも容易になるからです。
readコマンドには入力が途絶えた状態でreadを実行すると次の入力があるまで待つという性質があります。これをwhileループと併用すれば、断続的に流入してくるデータを待ち受ける非同期処理も簡単に実現できます。以下は、TwitterのUser streams APIで新しい通知を待ち受けて少しずつ処理する例です。
Twitterの新しい通知を待ち受けて処理する例:
watch_twitter_events() {
curl --get ... https://userstream.twitter.com/1.1/user.json |
while read -r event
do
# eventには1つ1つのツイートやイベントを表すJSON文字列が格納されている。
done
}
watch_twitter_events & # 末尾に「&」を付けて関数を実行すると、子プロセスで非同期に実行される。
このように使われる事を想定して、複数のデータを扱うコマンドラインツールの多くは、1行1単位の形で標準出力に結果を出力するように設計されています。Slackのクライアントであるslackcatも、チャンネルの内容を監視する時は受信したイベント・メッセージを1行1データで出力してくれるので、やはりwhile read -rで処理することができます。
Slackのチャンネルの新しい発言を待ち受けて処理する例:
watch_slack_channel() {
slackcat --channel team:general --stream --plain |
while read -r post
do
# postには1つ1つの発言が格納されている。
done
}
watch_slack_channel &
シェルスクリプトやシェル関数では、readをイテレータ的に使うことによって、データが静的な物だろうが動的に生成(返却)されるものだろうが全く等価に扱えるということをお分かり頂けるでしょう。
for ... inループは標準入力から受け取るデータには使わない
ところで、シェルスクリプトでループというとこんな書き方もあります。
シェルスクリプトでのforループ:
for host in fileserver mailserver authserver
do
scp /path/to/file uploader@$host:~/
done
これも確かにイテレータパターンなのですが、こちらはfor ...inの後にすべての項目をあらかじめ列挙しておかなくてはならない書き方です。こちらだと、前述したような「全体像が未知のままでも処理できる」というイテレータならではの利点を活かせません。
一応、「コマンド置換を使うとコマンドの実行結果を文字列として参照できる」という事と「引数無しでcatを実行すると標準入力からデータを受け取る」という事を組み合わせると、パイプラインで受け取ったデータをシェル変数の形でメモリ上に保持することはできます。なので、以下のような書き方も可能です。
シェルスクリプトでのforループで標準入力を処理する例:
for line in $(cat) do # 各行に対する処理 done
しかし、これは以下の理由からオススメできません。
- 標準入力から一旦データをすべて読み取り終えることができるのが前提となるため、前述したストリーミングAPIからの情報の受け取りのようにデータの流入がいつ終わるか分からない場面では使えません。
- 読み取り元のデータが巨大な場合、メモリを大量に消費する事になります。そういう場合は一時ファイルに書き出して
catし直した方が安全です。 forのループでは改行だけでなく半角スペースなども区切り文字になるため、流入するデータの内容によっては期待通りに分割されません。
3については、区切り文字を明示的に変える方法もありますが、トリッキーなので使わない方がいいと自分は思っています。何度も述べますが、トリッキーなやり方は基本的に避けた方が無難です。
コマンド置換を使ってパイプラインで受け取ったデータをシェル変数に格納する方法は、「全体像が分かっていて、メモリ上に保持しても問題にならないような小さな規模のデータ」を「複数回使い回したい」という場面に限って使うのがよいでしょう。またその時も、上記の3番目の理由から、forではなくwhile readを使うのがオススメです。
関数に渡された標準入力を一旦蓄えて、複数回使う例:
url_encode() {
input="$(cat)"
echo " -------------------" 1>&2
echo " Input:" 1>&2
echo "$input" | sed 's/^/ /' 1>&2
output="$(echo "$input" |
while read -r line
do
echo "$line" |
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g'
done)"
echo " -------------------" 1>&2
echo " Output:" 1>&2
echo "$output" | sed 's/^/ /' 1>&2
echo " -------------------" 1>&2
echo "$output"
}
実行例:
$ cat data.txt
おはよう
こんにちは
$ cat data.txt | url_encode
-------------------
Input:
おはよう
こんにちは
-------------------
Output:
%E3%81%8A%E3%81%AF%E3%82%88%E3%81%86
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF
-------------------
%E3%81%8A%E3%81%AF%E3%82%88%E3%81%86
%E3%81%93%E3%82%93%E3%81%AB%E3%81%A1%E3%81%AF
ここではデバッグログ出力用に一旦catで標準入力をすべて読み出してinputという変数に保持し、それをechoで出力してデバッグメッセージと本来の処理の両方に使っています。
他のコマンドやシェル関数にもパイプラインでデータを渡す
データの受け取りには標準入力を使うのがベストプラクティスなら、データの出力にも標準出力を使うのがベストプラクティスです。ここで押さえておきたいのは、標準出力には何度でも、どこからでも、いつでもデータを出力できるという点です。
一般的なプログラミングでは関数は1回しか値を返せません。なので、関数内部で結果を収集して最後にまとめて返す設計にする必要があります。
改行区切りのテキストを受け取って、すべてをURLエンコードして返すJavaScriptの関数の実装:
function url_encode(text) {
var lines = text.split('\n');
var encodedLines = lines.map(function(line) {
line = nkf(line, '-W8MQ');
line = sed(line, 's/=$//');
line = tr(line, '=', '%');
line = paste(line, '-s', '-d', '\0');
line = sed(line,
'-e', 's/%7E/~/g',
'-e', 's/%5F/_/g',
'-e', 's/%2D/-/g',
'-e', 's/%2E/./g');
return line;
});
return encodedLines.join('\n'); // ←ここで初めて値が返される
}
この発想のままシェルスクリプトを書くと、こんな風になります。
JavaScriptと同じ発想のシェルスクリプトの場合:
url_encode() {
result=''
while read -r line
do
# 結果の文字列を収集
result="${result}\n$(echo "$line" |
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g')"
done
echo -e "$result" # ←ここで初めて結果が標準出力に出力される
# (echoで「\n」を改行として出力するには
# 「-e」オプションを付ける必要がある)
}
でも、ちょっと待ってください。先に述べたとおり、標準出力への書き込みは時と場所を選びません。わざわざ結果を収集して最後の1回でまとめて出力しなくても、処理できた結果からちょっとずつ出力してもいいはずです。
シェルスクリプトらしい書き方の場合:
url_encode() {
while read -r line # ←標準入力からデータが渡ってくる度にループが1回実行される
do
echo "$line" |
nkf -W8MQ |
sed 's/=$//' |
tr '=' '%' |
paste -s -d '\0' - |
sed -e 's/%7E/~/g' \
-e 's/%5F/_/g' \
-e 's/%2D/-/g' \
-e 's/%2E/./g' # ←ループが回る度に毎回ここで結果が標準出力に出力される
done
}
実際にこの2パターンに対して複数行の入力を与えて実行してみると、前者はちょっと待たされてから結果がまとめて出力されますが、後者は少しずつ結果が出力される様子を見て取れます。
この書き方なら、while readのイテレータ的な振る舞いを組み合わせてパイプラインで繋げると、処理全体の完了を待たなくてもデータを準備できた物から順次処理して次に引き渡すということができます。
非同期処理との組み合わせ:
list_tweet_bodies() {
curl --get ... https://userstream.twitter.com/1.1/user.json |
while read -r tweet # ←Web APIからデータが1件届く度にループが1回実行される
do
echo "$tweet" |
jq -r .text |
unicode_unescape # ←ループが回る度に毎回ここで結果が標準出力に出力される
done
}
list_tweet_bodies |
url_encode |
sed ... # Web APIからデータが1件届く度にパイプラインを通じてデータが流れてくる
これが、真の意味で「データの出力に標準出力を使う」という事です。
他の言語の一般的な関数の振る舞いに慣れていると「関数は、実行して1回値を返したらすぐ終了する」「そうして順番に関数が実行されていく」というイメージがあると思います。
しかし、シェルスクリプト内でのコマンドやシェル関数は、実はそれとは違った振る舞いをしています。
これは先にも1回出てきた絵ですが、コマンドやシェル関数をパイプラインで繋げて実行したときは、パイプラインをデータが流れてくる間は彼らはずっと生き続けているのです。そうしてパイプラインの最初のコマンド(この絵ではcat)が「もうこれ以上データは無し!終わり!」とギブアップして終了した時点でやっと、パイプラインの先にいるコマンドやシェル関数達も終了していくというわけです。
また、最後にまとめてechoで結果を出力する例に比べて、随時echoで結果を出力する例では、コマンド置換やecho -eのように珍しいオプションを使っている部分が無くなって簡潔になっているという事に気付いたでしょうか? これも「その言語の基本機能で素直な書き方で実現できる処理」はその言語に適している、という冒頭の話の実例です。
シェルスクリプトでの「ライブラリ」
他の人の作ったライブラリを使いたい?
シェルスクリプトには便利なモジュール機構はありません。gemやnpmのようなライブラリ集も(多分メジャーな物は)ありません。
が、先の例で示したように「結果を標準出力で、1行1単位で出力するコマンド」であれば何でも処理対象のデータ提供元になります。また、「パイプライン経由で1行1単位でデータを受け取れるコマンド」であれば何でもデータを渡す先にできます。よって、シェルスクリプトではシステムにあるコマンドラインツールすべてをライブラリとして利用できると言えます。先程紹介したslackcatもgemのパッケージとして提供されているコマンドツールですが、何の違和感も無くシェルスクリプトの中で使えていましたよね。
(話はずれますが、slackcatが使用するSlackのストリーミングAPIは一般的なHTTPベースのAPIではなくWebSocketに基づいており、純粋にシェルスクリプトだけで実装しようとするとかなり大変です。slackcatは、そのようにシェルスクリプトとの親和性が低いAPIをラップして、標準入出力ベースで結果を受け取れるようにする変換器として働きます。その他のそのままだとシェルスクリプトにとても組み込めそうにない技術も、何らかの方法で標準入出力ベースのコマンドの形にすれば、他のコマンドと同じ形式となり、容易にシェルスクリプトに組み込めるようになります。これは、各言語において「バインディング」を実装するのと意味的には同じだと言えるでしょう。)
「シェルスクリプトを使うには、いろんなコマンドの使い方に精通していないといけない」と言う人もいますが、よく考えれば普通のプログラミングでも、ライブラリの使い方を把握するために色々なドキュメントを読むものです。それに比べると、--helpオプションを付けたりmanコマンドを実行したりすれば簡単な使い方を自分から説明してくれる分、コマンドの方がむしろ開発者に優しいと言えるかもしれません。
自分で作ったライブラリを使いたい?
特定のシェルスクリプト内でシェル関数として定義した物を別のスクリプトでも流用したい場合には、sourceコマンドで読み込むという方法もあります。筆者の書いたTwitter botでも機能ごとにスクリプトを分けていますが、共通のユーティリティ的な処理は1つのファイルにまとめておいて、各スクリプトからsourceで読み込んで利用しています。これはRubyでいえば、requireの後にincludeしてMix-inで定義されたメソッドを取り込むようなイメージです。
しかし、この時問題になるのは変数です。シェルスクリプトには変数のスコープが「スクリプト全体のグローバル変数」と「関数内のローカル変数」の二種類しかありませんから、sourceで読み込んだ「ライブラリ」の中にある関数名や変数名が読み込み元と被った場合に衝突してしまいます。
そういう時も前述の考え方が役立ちます。自作ライブラリとして用意したスクリプトも、sourceで読み込まずに普通のコマンドと同様に呼び出して実行すればよいのです。
実行される側のスクリプトと実行する側のスクリプトでは変数のスコープがはっきり分かれます。逆に言えば、変数のスコープを分けたい時はスクリプト自体を分ければ良いということです。実際に拙作Twitter botでも、Twitterクライアントのスクリプトは実行する形でのみ使用しています。
シェルスクリプトの活かし方
……と、ここまで「シェルスクリプトってこんなに使えるんだぜ!」という話をしてきましたが、だからといって何でもシェルスクリプトでやりましょうとは自分には言えません。
最初に述べたとおり、シェルスクリプトが適しているのはステートレスな処理です。「機能を1回実行したら、処理が行われて、結果が得られる。それで終わり。」という種類の仕事であればすんなり実装できます。が、内部で複雑な状態を持つ必要があるステートフルなスクリプトを書こうとすると、途端に「シェルスクリプトって厄介だ……」という印象が強まります。そういう「厄介さ」を隠蔽しようとすると、(何度も引き合いに出して申し訳ないのですが)bash-oo-frameworkのように「元の文法の上に全く別の文法を構築する」ようなアプローチを取らざるを得ません。そんな訳なので、GUIアプリを作ろうみたいな事は考えない方がいいです。
しかしその一方で、一見すると複雑なプログラムが必要そうな作業でも、見方を変えて問題を捉え直せばステートレスな作業で処理できることが分かり、シェルスクリプトですっきり解決できる場合があるのもまた事実です。
- 複雑な問題を小さな問題に解きほぐして、「パイプラインと標準入力と標準出力と、後はせいぜい
ifやcaseでの条件分岐程度の組み合わせだけで解決できる問題」あるいは「そういった単純な問題が集まってできた問題」として再定義する。- 実際に、筆者の書いたTwitterクライアントのスクリプトは、「Twitterクライアント」という物をTweetDeckやスマホのTwitterアプリのように「常時表示されていてユーザの操作を受け付ける」ステートフルな形態ではなく、「1つコマンドを実行したら、その結果だけを出して終了する」ステートレスな形態で実現する、という風に問題を再定義しています。
- 筆者が過去に執筆に関わった1年目から身につけたい! チーム開発 6つの心得という記事の中で、適切な粒度に実装を分ける考え方や、関数や変数の名前付けのしやすさを目安として適切な粒度を見極める考え方を解説していますので、そちらも是非併せて読んでみて下さい。
- そのように再定義できない種類の問題は、無理してシェルスクリプトでは扱わない。
これがシェルスクリプトを効果的に使うためのコツだと筆者は考えています。これらを踏まえた上で、
- 最終的にやりたい事の重要な部分が、コマンドラインツールとして提供されている場合。例えばTwitterのAPIを呼びたいのであればtwurl、SlackのAPIを呼びたいのであればslackcatなど。
- 言語のバージョン依存や環境依存を減らして、ポータビリティを高くしたい場合。
といった前提条件がある場合には、シェルスクリプトが現実的に問題解決のための最適な選択肢になり得るでしょう。
まとめ
ところで、「流入してくるデータを加工して返却する」「ステートレスな」処理が得意で、「内部で複雑な状態を持つ必要のある」「ステートフルな」処理が苦手だというのは、関数型言語にも見られる特徴です。実際、関数型言語が得意な人にこの説を披露してみた所、「関数型言語というのはストリーム型のデータを処理するという所がキモ(なので、解釈としてそう外してはいない)」という感じの感想を頂きました。
そう考えると、シェルスクリプトで凝った事をしようとする人があまり多くないのも頷けます。「関数型言語は難しい」と言われる事が多いですが、他の言語とパラダイムが違う言語だと思えば、これまでのプログラミングのパラダイムに囚われたままでは理解が進まないのも当然です。
ここはくどいくらいに強調しておきたいのですが、どのパラダイムや言語が絶対的に優れているという事はありません。解決したい問題の種類や性質、あるいは状況(外部要因)によって、最適なアプローチの仕方は変わってきます。実際に、ここまでで他の言語とシェルスクリプトのコードを比較する例をいくつか書いてきましたが、シェルスクリプトでは非効率的な書き方が、JavaScriptでは一番素直な書き方だという例があった事を思い出して下さい。「その前提条件の下ではJSの方が素直に問題を解決できる」という場面ではJSを使った方が良いのです。
別のパラダイムを知ると、普段のプログラミングでできる事の幅も広がります。使える武器が増える訳ですから、遭遇した問題の種類に応じてより適切な武器を選んで立ち向かえるようになります。「関数型言語を勉強する」と言うと仰々しく感じられて腰も重くなりがちですが、シェルスクリプトなら普段から使っているコマンド操作の延長線上で気軽に始められるでしょう。プログラマーとしての成長に役立てるためにも、シェルスクリプトに苦手意識のある方はこれを機に挑戦してみてはいかがでしょうか?
宣伝:「シス管系女子」について
なんか妙にアクセスが伸びてるので、本文中でもちょいちょい触れているシス管系女子の事もせっかくだから改めて紹介させて頂きます。
この記事の反応で「while read lineのどれをどういう順番で書けばいいのか覚えられない」という物を複数見かけました。例えば「シェルスクリプト 繰り返し 空白を含む文字列」などのキーワードでぐぐって出てきた書き方をそのまま丸暗記したりコピペしたりして使っているだけだと、意味が頭に入っていないため記憶に定着しないという事なのではないでしょうか? Linuxのコマンド操作やシェルスクリプトではそういう悩みを抱えている方が多いような印象があります。というか筆者もかつてはその1人でした。
「シス管系女子」は2011年から日経Linux誌上で連載させて頂いているケーススタディ形式の解説マンガ記事で、SSH越しのコマンド操作をするという場面を想定してコマンドのはたらきやパイプラインの仕組みなどを全編漫画で解説しているのが特徴です。この記事のようなガチプログラミングな内容はあまり含まれていませんが、whileループの理屈やreadコマンドの作用の仕方などについてもそれぞれの意味を踏まえながら丁寧に解説していますので、「あ、ここはコマンド名だな」「ここは引数だな」と自分で理解しながら自由にコマンド列を組み立てられるようになるのではないかと思います。
また、直接読んで下さった方にご好評を頂けているだけでなく、その方がさらに新人や後輩のための1冊としてご紹介して下さっている事が結構あるみたいで、大変ありがたい限りです。
本稿執筆時点では、連載に加筆修正した単行本が以下の2冊リリース済みです。

まんがでわかるLinux シス管系女子:1年目と2年目の内容で、SSH越しの操作の基本とシェルスクリプトの基本(最初の4話は達人出版会のサンプルページで丸々読めます)
まんがでわかるLinux シス管系女子2:3年目と4年目の内容で、シェルスクリプトのもうちょっと凝った使い方の話が多め
それ以外にも、Twitterのみんとちゃんbotアカウントでイラストや本編に入りきらなかった小ネタを流したり、Webサイトの方にも連載や本では扱わなかったもっと基礎的な話の特別編を置いていたりします。あと、「シス管系女子」をテーマにしたAdvent Calendarも公開中です。
ということで、最後は宣伝で〆てしまいましたが、Shell Script Advent Calendarの8日目でした。次の方の記事もお楽しみに!
追記。ここで語っている事を使って文字列処理するときに恐らくやりたくなるであろう事のフォローアップ記事として、join()やsplit()に相当する事をシェルスクリプトでやる場合の話を書きました。そちらも併せてご覧頂ければ幸いです。
wikieditish message: Ready to edit this entry.