Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

絵文字✨とTwitter Bot🤖と私👤とEmoji Editor📝 - Dec 15, 2016
このエントリは絵文字Advent Calendar 2016とのクロスポストです。(→Qiitaの方の投稿)
この記事では、自分が絵文字込みのテキストを楽に編集するために作ったEmoji Editorという簡単なツールを紹介します。
PCでパレットから絵文字を入力したいんです……😭
唐突ですが皆さん、どうやって絵文字を入力されてますか?
Android版のGoogle日本語のように絵文字のパレットが付いていたり、macOSの日本語入力のように標準辞書に入っていて普通に「すし」と入れて変換すれば「🍣」になったりする環境もあるようなのですが、自分が主に使っているWindows 7+ATOK2016の環境とUbuntu 16.04LTS+ATOK X3の環境では良い方法がなさげです。自分は絵文字はパレットから選択したい派、というか顔文字に対応する読みをいちいち覚えてられない派なので、やるなら一覧の中からぽちぽちクリックして選びたいです。しかしATOKに付属の文字パレットというユーティリティの分類には「顔」みたいなグループ分けが無いため、Unicode絵文字を使おうと思うとUnicodeの表のあっちこっちを行き来しながら探さないといけません。(最新のATOK2017ではこの辺どうなんでしょう?)
また、これはカラー絵文字のフォントが無いという古い環境だからのようですが、文字パレット上だけでなくテキストエディタ上でも絵文字は白黒表示です。自分が絵文字を使いたいのは主にTwitterでの投稿なので、見るならTwitter上でどう見えるかが分からないと安心して使えません。
元々絵文字を使う習慣が無かった自分が絵文字に触れる機会が増えたのは、「シス管系女子」の広報用Twitterアカウント(みんとちゃんbot)がきっかけです。いつもの自分のノリでやると堅すぎると思ったので、みんとちゃんbotの発言についてはあえて絵文字を入れて柔らかい印象を持ってもらえるようにしたい、という下心ドリブンです。
当初はAndroidのGoogle日本語入力から絵文字を入れていましたが、運用のためのbotスクリプトを作成して、発言データにするためのテキストを大量に用意する段階になってPC上で作業に入ろうとしたときに、前述のような状況に気が付きました。
そこでとりあえずTwitter絵文字が使えるパレットを探してみた所、テスト用にちょっと投稿するだけならTwitterの絵文字をデスクトップPCから使おう! Ver2というサービスで絵文字の入力自体はできる事が分かりました。が、このページは既に作成済みのデータの編集には使えません。やはりここは、Twitter絵文字を含んだプレーンテキストをWYSIWYGで編集できるツールが欲しくなるところです。
探し方が悪かったのかもしれませんが、自分はその時「まさにこれだ!」と思える物を見つけられなかったため、無いなら作るか……という事で作りました。その名もEmoji Editor(名前が安直すぎる)。HTMLファイル1つだけで完結する、フレームワークも何も使ってないSPAとも呼べないような代物です。
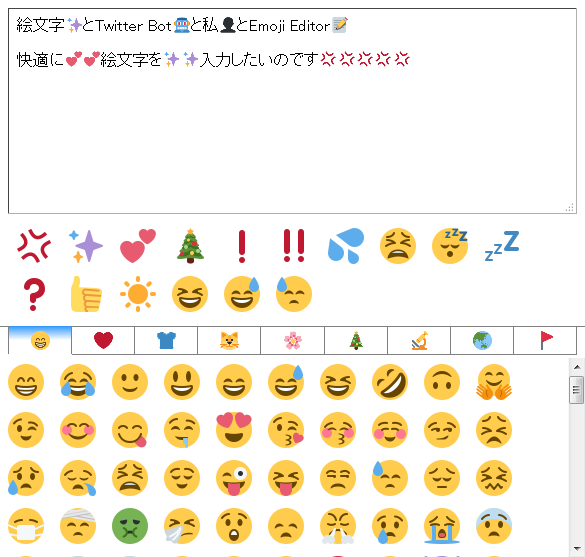
このエントリの公開を機に、GitHubにリポジトリを作りましたので、forkしたりプルリクしたりして頂ければ幸いです。
ツリー型タブとマルチプルタブハンドラのイベント周りのAPIをちょっと変えた - Jan 11, 2011
Tree Style TabとMultiple Tab Handlerを更新した。
今回のアップデートでも例によってMinefield対応のための修正をちょっとずつ入れてるんだけど、その中で1つ、なかなか気付いてなくてハマってた所があった。それはカスタムイベントを使ってた部分。
DOM2 Eventsではこんな風にして任意のDOMイベントを発行できる。
var event = document.createEvent('Events');
event.initEvent('MyCustomEvent', true, false);
event.status = 'current status';
event.tab = tab;
gBrowser.dispatchEvent(event);
受け取る側はこれをaddEventListener()で登録したリスナで拾うようにすれば、各々のモジュールの結合度合いを弱められる。なので僕は自分のアドオンでも積極的にこれを使ってる。
が、これがMinefieldでは使えなくなってた。
多分Compartment(JavaScriptのメモリ空間をスクリプトのオリジンだったかウィンドウだったかごとに分ける機能)が入ったからだと思うんだけど、Chrome URLのスクリプトで上記の例のように追加した任意のプロパティを、JavaScriptコードモジュール側のイベントリスナで参照できなくなってた。上記の例だと、捕捉したイベントのevent.tabがundefinedになってしまってて、こういうやり方で情報を引き渡してた部分がエラーになってしまってた。wrappedJSObjectもundefinedなので、生のオブジェクトを辿る事もできなかった。
MDCにある任意のカスタムイベントを実装する方法の詳しい説明によると、XPIDLでインターフェースを定義してC++で実装を書いてという事をやれば、今までと完全に同じAPIで任意のイベントを発行できるようなんだけど、それはちょっと重たすぎてやる気になれない。
なので次善の策として、汎用のデータを受け渡すためのイベント型があればそれを使おうと思って検索したら、Firefox 3以降ではDataContainerEventとかMessageEventとかの型のイベントが利用可能になってたという事を知った(今更)。
渡すデータがJSON文字列化できる物なら、WebSocketで定義されてるMessageEventがいいっぽい。
var event = document.createEvent('MessageEvent');
event.initMessageEvent('MyCustomEvent', true, false,
JSON.stringify({ status : 'current status',
tab : tab.getAttribute('id') }),
'', '', null);
gBrowser.dispatchEvent(event);
受け取った側はJSON.parse(event.data)でデータを復元できる。
DOM要素とかも渡したいなら、nsIVariant型でデータを受け渡せるDataContainerEventを使うしか無さげ。
var event = document.createEvent('DataContainerEvent');
event.initEvent('MyCustomEvent', true, false);
event.setData('status', 'current status');
event.setData('tab', tab);
gBrowser.dispatchEvent(event);
受け取った側はevent.getData('tab')のようにしてデータを取得できる。
ということで、プロパティアクセスにしてた所は全部DataContainerEventのやり方を使うように直した。ただ、後方互換性のためにプロパティアクセスでも情報はセットしてあって、同じCompartmentのスクリプトからなら多分今まで通りのやり方でも情報を受け取れると思う。
あと、DataContainerEventの存在を知る前に、MDCのドキュメントに書いてあった「イベント名がnsDOMで始まってない物は任意の情報は受け渡せないよ」という部分を読んでイベント名を「nsDOMTreeStyleTab...」という感じに変えていて、実際これでちゃんと動くようになった部分もあったんだけど、結局DataContainerEventにするようにしたからこれは結果的には余計だったかもしれない……
ツリー型タブとTab Mix Plusの衝突について調べていてGeckoのバグを見つけた - Aug 13, 2009
ツリー型タブが入ってるとスターアイコンからブックマークの内容を編集できない、という報告を見て、そんなバカなこっちじゃちゃんと動いてるのに!と思って薄々そうなんじゃないかなあと思いながらよく報告を見てみたら、Tab Mix Plusと組み合わせた状態であると書いてあり、やっぱり……と思いながら両方を入れてみたら確かに問題が再現した。まあここまではよくある話。
エラーが起こっている箇所はエラーコンソールのメッセージから容易に特定できたんだけど、でもどう見てもそこでエラーになるはずがないという箇所でエラーになっていた。具体的には1つ前のエントリに書いたcreateContextualFragment()の所。色々条件を変えて調べてみたら、どんな簡単なソースを渡した場合でもcreateContextualFragment()の返り値が常にnullになっているようだった(Firefox 3.0.13でのテスト結果)。で、さらに条件を変えながら色々試して分かったのは、そもそもツリー型タブと組み合わせなくても、Tab Mix Plusが入ってるだけでcreateContextualFragment()が全然使い物にならなくなる(Firefox 3.0.xや3.5では常にnullが返り、Trunkでは常に例外が発生する)ということだった。
さすがにこれは何かおかしいと思って、エラーコンソールに表示されるエラーをよく見ると、XMLのパースエラーで「属性が二重に定義されている」とメッセージが出ている。それでピンと来てTab Mix Plusのソースを見てみたら、怪しい記述を見つけた。オーバーレイ用のXULドキュメントで、idがmain-windowであるwindow要素のオーバーレイ内容にXML名前空間宣言が含まれている、というものだ。もちろんこれはXML的に全く問題がないはずの記述なのだけれども、まさかと思いながらそこを書き換えてみたら、Tab Mix PlusがあってもcreateContextualFragment()が失敗しなくなった。それで、ここが原因だと確信が持てたということで、Bugzillaにバグとして報告してみた。
条件がややこしい上に、一体どこが一番悪いのか分からなかったんだけど、一番表面上のトリガーになってるように見えてるのがDOM Traversal-Rangeだったので、そこのバグとして報告してある。
この問題を回避しようと思ったら、Tab Mix PlusのオーバーレイでXML名前空間宣言を書くのは本当のルート要素だけという風に書き換えるのが一番手っ取り早いんだけど……できれば本体(Gecko)の方を直してほしい所ではある。
DOM周りの根っこの所に変更が入ったみたい - Jun 10, 2009
The Burning Edge見てたら、こんなバグがFIXEDになっていた。
- Bug 468708 – namespaceURI for HTML elements should be http://www.w3.org/1999/xhtml
- Bug 468692 – localName should return in lower case for HTML
text/htmlなHTMLドキュメントをXMLとして扱うにあたって、HTML5の仕様に合わせる形になるという事のようだ。namespaceURIがnullから"http://www.w3.org/1999/xhtml"へ、localNameがすべて大文字からすべて小文字へ、それぞれ変わる、と。
以前の挙動は以前の挙動で古い仕様には合致していたはずなので、時代の移り変わりをしみじみと感じる。
僕があまりDocumentFragmentを使っていない理由 - Jul 07, 2008
自分にはちょっと承伏できない理由でJintrick氏にDISられてるので、一応釈明しておきます。
――「一応」と書いておきながら、Jintrick氏に「バカじゃねーの」みたいに煽られたような気がして感情的になってクドクド書き過ぎてしまったので、最初に例だけ示しておきます。
<?xml version="1.0"?>
<html xml:lang="ja">
<head>
<title>テスト</title>
</head>
<body onload="init()">
<script type="application/x-javascript">
function init()
{
var ul = document.getElementById('indicator');
document.addEventListener('keypress', function(aEvent) {
var li = document.createElement('li');
li.appendChild(
document.createTextNode(
[
aEvent.type,
aEvent.keyCode,
String.fromCharCode(aEvent.charCode) +'('+aEvent.charCode+')',
aEvent.target,
aEvent.target.localName,
(new Date()).getTime()
].join(' : ')
)
);
ul.insertBefore(li, ul.firstChild);
}, false);
}
</script>
<textarea rows="5" cols="50">ここに文字を入力すると、イベントの詳細を表示します。</textarea>
<ul id="indicator" style="height: 15em; overflow: auto;">
</ul>
</body>
</html>これが正常に動作しなくなるというただそれだけの理由で、僕はJintrick氏の勧める方法(上位のDOMノードをゴソッとDOMツリーから切り離して、ツリーに対する処理を行い、最後に再挿入することで、パフォーマンスを向上する)を全面的には採用できません。
以下、長々とその説明。
getElementsByなんちゃら の代わりにXPathを使う - Sep 09, 2007
拡張機能勉強会の時に焚き付けられた、Text Shadowのコード(textshadow.js)を教材にして拡張機能開発のノウハウを解説していくシリーズ。
W3CのDOMでは、要素ノード(およびそのリスト)を得る方法として以下の方法がある。
getElementById(aName)- IDをキーにして単一の要素ノードを得る。
getElementsByTagName(aTagName)- タグ名、要素名をキーにして要素ノードのリストを得る。
childNodes- 子ノードのリスト。
本当はネームスペースを指定して検索する物もあるんだけど、ここでは割愛。
これら以外に、W3C DOMではないがこういうのもある。
getElementsByClassName(aClassName)- クラス名をキーにして要素ノードのリストを得る。WHATWGのWeb Applications 1.0で定義されており、Firefox 3で利用可能。
getElementsByAttribute(aName, aValue)- 属性名と属性値をキーにして要素ノードのリストを得る。属性値として「*」を渡すとその属性を指定された要素全てを得る。FirefoxでXULドキュメントにおいて利用可能。
ただ、探したい要素ノードの条件が複雑な時は、これらを使って取得したノードリストをループ回して条件判断しないといけないし、そもそもこれらでは要素ノード以外は取得できない。そこで最近のJS界隈でよく使われているのが、XPathだ。
XPathとは、/html/descendant::li[@class="navigation"]という風な「式」でXMLノードを特定する技術だ。XPathの書き方を新たに憶える必要はあるが、これを使えば、複雑な条件に合致するノードのリストを一発で取得することができる。コードが簡潔になるのはいいことだし、FirefoxでもSafari 3でもOperaでも、普通にDOMとJavaScriptでごりごりやるのに比べて20倍以上高速に動作するという話もある。
XUL Tipsのページに書いてるけど、FirefoxではDOM3 XPathで提案されているXPath関係の機能が利用できる。詳しい解説はHawk's W3 Laboratoryの「DOMとXPathの連携」(サイトが消えてるので、インターネットアーカイブからどうぞ)を見て欲しい。リンク先では「Gecko用」と書かれてるけど、現在ではOperaとSafari 3でも利用できるようになっている。
第6回拡張機能勉強会 - Sep 03, 2007
目が覚めたら14時でした。
勉強会本体の感想。
Firemacs作者の山本さんの話を聞いてると、以前の自分を思い出した。XPCOMにどんな機能があるのか知らなかった頃に、知ってる範囲の知識でどうにかして解決しようとあれこれ工夫を試みていた。そういう「工夫」を思い付くかどうか、というのが、もしかしたらある種の「分れ道」なのかもしれないなと思った。
marさんによるXUL preLoaderの話。
- XULオーバーレイでボタンを追加したいのに、その要素にidが指定されていない、という場合、JavaScriptとDOMを使ってXUL要素を生成して埋め込むという方法をとらざるを得ない。
- オーバーレイで読み込むXUL文書を間に一つ増やして、その「間に挟まれた」XUL文書においてid属性をスクリプトで設定してオーバーレイを適用できるようにしてから、改めて、本来オーバーレイで読み込ませたかったXUL文書を
document.loadOverlay()で動的に読み込む。……というのが、preLoaderの発想。
preLoaderのような発想が僕に無かったのは、loadOverlayというメソッドを知らなかった・存在を忘れてたからというのも大きいんだけど、それ以前に、他の拡張機能で同じ方法を使われて異なるIDを指定されてしまったらこのテクニックは破綻してしまう、ということに気づいていたからだ。僕は以前から、拡張機能を作るときは他の拡張機能となるべく衝突しないようにということに気を付けるようにしている(TBEの時はそれで散々叩かれたし)ので、preLoaderのテクニックはあまり推奨しづらい。
ところで、今ふと思ったんだけど。E4X使ったらJavaScriptの中に普通にXUL文書片を書けるから、preLoaderあんまりいらなくね?(ぉ
誕生日を祝ってもらえて、フォクすけは幸せ者ですね。僕もこれくらい愛されてみたいです。どうでもいいですが、ケーキの周りのフィルムについたクリームを舐め取っている様子をばっちり撮られてしまっていました。
Mozilla 24のための各プログラムの番宣ビデオ?の撮影があって、Shibuya.jsのビデオに僕まで出ることになってしまった、というかほとんど僕が喋ってた。幽霊部員なのに。あとで映像見てみても、ほんとキモイなーと思った。また叩かれるんだろうなあ。いやだなあ。
selector.js改 - Jul 31, 2007
にゃるら、さんのselector.jsをベースに色々やってたらそれっぽい物ができたので、氏に敬意を表しselector.js相当の部分をMITライセンスで公開しときます。冒頭のコメントを見ての通りですが、元のselector.jsで対応されていなかったCSS3のセレクタをだいぶサポートしてます。正しく動かない事があるかもしれないのでその時はフィードバックください。
改造版の一番の特徴は、document.convertSelectorToXPath()ですね。CSSのセレクタを文字列で渡すと、対応するXPath式を生成できる場合はそれを返します。ダイナミック疑似クラス等、XPath式では表現できない内容の時は空文字を返します。
var nodes = document.getElementsBySelector('li:nth-child(even)');
for (var i in nodes)
{
nodes[i].style.backgroundColor = 'gray';
}
var expression = document.convertSelectorToXPath('p:not(li > *)');
// → /descendant::*[local-name() = "p" or local-name() = "P"][not(self::*/parent::*[local-name() = "li" or local-name() = "LI"])]
- メソッド内の変数の
silhouettePseudElementsAndClassesがtrueの時は、:first-line疑似要素や:first-letter疑似要素など、無茶すればどうにか再現可能な物については、勝手に要素を生成したりclassを設定したりしてそれを使ったXPath式を返します。 - 上記の例を見ても分かるとおり、まあ、無駄が多いです。XPathの勉強用か、内部処理用と割り切って使う事をお勧めします。
- 内部で
document.evaluate()を多用してるので、DOM3 XPathを実装したブラウザでしか動かんです。というか多分Gecko専用? 他のブラウザでも動いたら教えてください。 - Geckoの仕様上、スタイルシートに記述してあっても、内部のテーブルに存在しないセレクタは無視されるようです。
:nth-child()とかは、カンマ区切りのセレクタのリストにそれがあるだけで、その宣言ブロックが丸ごと無視される模様です。(豆知識)
DOM2 Rangeと選択範囲とマーカー - Jul 22, 2006
ラインマーカーの実装について質問を受けて回答したのだけれども、同様の疑問を持っている人がもしかしたらいるかも知れないなあとか、最近全然技術文書を書いてないなあとか、ドキュメントを増やすのもデベロッパの務めだよなあとか、なんやかや考えて文書にまとめてみた。
で、このドキュメントを書く途中で気がついたことやなんかを盛り込んで、ラインマーカーそのものを更新したりもして。
ああ、この時間の無いときに何でこんなことを僕はやってるんだろう……DOMを触ったことがある人にとってはあまりに常識的な話で、DOMを触ったことがない人にとってはちんぷんかんぷんな話、という非常に微妙な内容のドキュメントになってしまい、こんな物が一体誰の役に立つのだろうか、と我ながら激しく疑問に思う。
まあ、あれだ……一日遅れの24歳の誕生日プレゼントだと思ってください。って、自分が人にあげるのかよ。
blosxom+Markdownに慣れてしまうと、HTMLを書くのが面倒でたまりません。
DOM2 Rangeと選択範囲とマーカー - Jan 01, 1970
ラインマーカーの実装について質問を受けて回答したのだけれども、同様の疑問を持っている人がもしかしたらいるかも知れないなあとか、最近全然技術文書を書いてないなあとか、ドキュメントを増やすのもデベロッパの務めだよなあとか、なんやかや考えて文書にまとめてみた。
で、このドキュメントを書く途中で気がついたことやなんかを盛り込んで、ラインマーカーそのものを更新したりもして。
ああ、この時間の無いときに何でこんなことを僕はやってるんだろう……DOMを触ったことがある人にとってはあまりに常識的な話で、DOMを触ったことがない人にとってはちんぷんかんぷんな話、という非常に微妙な内容のドキュメントになってしまい、こんな物が一体誰の役に立つのだろうか、と我ながら激しく疑問に思う。
まあ、あれだ……一日遅れの24歳の誕生日プレゼントだと思ってください。って、自分が人にあげるのかよ。
blosxom+Markdownに慣れてしまうと、HTMLを書くのが面倒でたまりません。