Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

自民党の教師通報フォームの一体何が「問題」なのかを考えてみて、これを問題と思わなかった人に言いたくなったこと - Jul 12, 2016
ちょっと前に「政治的中立を逸脱した教員」を通報する窓口を自民党が公開した件が一部の間で話題になってました。
僕自身は、そのフォームの存在にキナ臭いものを感じて、否定的な思いを抱いてる。これは事実。
でも批判の記事をボンヤリ読んでても「悪いから悪いのだ」的な事を言ってるように見えてしまうし、「密告したかった授業」ハッシュタグの様子を見てると市井では「何も問題無い、いいぞもっとやれ」的な盛り上がり方をしている雰囲気すら感じられる。 自分も、その盛り上がりの様子を見て「分かる」という感覚はあって、この種のフォームの存在を肯定するような感情を抱いた。これもまた事実。
この矛盾しているように見える2つの思いにどう折り合いを付ければいいのかを考えていて、自民党のフォームに元々あったであろう意図と、それを礼賛している人達がそのフォームに期待しているであろう物との間にズレがあるんじゃないのか? と思った。
で、「あの頃のあの嫌な先生が憎い」という感情が優先で先のフォームの問題点がスルーされているんだったら、それって良くないんじゃないの、と思った。
この件を問題だと感じた、と書いている時点で「左翼の左翼擁護乙」と思う人もいると思うんだけど、以下の文はそういう人にこそちゃんと考えてもらいたいと思って書いてます。
現実に「問題教員」の通報先は必要だけど……
自分の子供の時の事を思い返してみて、確かに問題教員と言えるような人はいたと思う。 そういう人を「通報」する先は必要だと思う。
でもそれは「自民党が」やるべき事というわけじゃないですよね。 いや、自民党がやってもいいんだけど、本来だったら教育委員会なり何なり、教育関係者の中での監査役みたいな存在がやるべき事だと思う。
いま現在然るべき通報先が無いのならそれは教育関係者の怠慢だし、通報先があっても問題が握り潰されるなどしてまともに機能していないなら、それもまた怠慢です。 教育関係者の間での自浄作用が期待できないから外部からの黒船に頼るしかないんだ、という現実があるんだったら、それは早急に解決されないといけない問題だと思う。
繰り返すけど、それを自民党がやったらいけない、とは思いません。 実際、必要があって生活保護の申請をしてるのに通らないという場面で共産党がコンサルのような事をしているという話はあって、これを「本来は行政がやるべきだけどできていない事を外部の人間が代わりにやっている、それがたまたま政党だっただけだ」と言うなら、同じような事を自民党がやって悪い道理はないです。
で、どういう人が「問題教員」なの?
今はもう削除されてるけど、最初は自民党のフォームには「『子供たちを戦場に送るな』と主張し中立性を逸脱した教育を行う先生」という文言、改訂後は「『安保関連法は廃止にすべき』と主張し中立性を逸脱した教育を行う先生」という文言があった。 あくまで例示という形だけど、「そういう人は通報されるべき」という意図の表明ではある。
「戦争法なんてけしからん。子供を戦場に送る悪法だ。そう思う子は手を挙げなさい。ん、なんでお前は手を挙げないんだ? あんな物を良しとするのか? じゃあお前は平和の敵だな。先生はお前には授業をしない。教室を出ていけ。」って言う教員がいたとして、そういう教員をこのフォームから通報したら、当初の説明文の例に似てるし、これはまあ確実に調査対象ですよね。
じゃあここで意地悪なことを考えるんだけど、「同性愛なんてけしからん。子供を作る気がない奴は、国を滅ぼす非国民だ。渋谷区のパートナー条例みたいな物は即刻やめるべきだ。そう思う子は手を挙げなさい。ん、なんでお前は手を挙げないんだ? あんな物を有り難がってるのか? じゃあお前は非国民だな。先生はお前には授業をしない。教室を出ていけ。」って言う教員がいたとして、そういう教員をこのフォームから通報してちゃんと取り扱ってもらえるんだろうか?
フォームの趣旨があくまで「政治的中立性」に関してだから、同性愛云々は政治的中立性とは関係無い事例だから調査対象じゃないと言われるかも知れない。
あるいは、自民党の憲法草案に表れているように自民党としては「伝統的な家族のあり方」を大事にしてるので、伝統的家族観を破壊する同性愛は認められない、だからその教員の言動も党の方針と矛盾してないので問題なし、と判断されて握り潰されるかもしれない。
あくまで悪意に取った想像ですよ。 こういうのもちゃんと調査してくれるかもしれませんよ。 真の保守たる政権与党なら、そういうふうにまっとうに仕事をして欲しいと思ってますよ。
僕は、どっちの教員も問題教員だと思うし、調査されるべきだと思うし、教育の現場にそういう人がいて欲しくないです。 でも、その理由は「政治的に偏ってるから」ではないです。
政治的に中立じゃなくても、そういう問題教員って取り締まれるんじゃないの?
先の例のような左翼先生だけが取り締まられて後の例のような伝統的家父長先生が取り締まられないんだったら、それって結局、ただの左翼狩りになってしまう。 それこそ政治的な偏りだと思う。
両者を等しく取り締まるには、政治と無縁の人だけを集めるか、あるいは、右からも左からも人を集めてきて、事例を握りつぶせないような状況を作るかしかないんじゃないの?と思う。
っていうようなことを言うと、みんな口を揃えて「中立なんてあり得ない」と言うんだけど、論点はそこじゃないでしょう。 中立じゃなきゃ取り締まれない、というタイプの問題じゃないじゃないですか、これ。
まあ、教室から出て行けみたいな極端なことを言う人は今時いないと思います(そう思いたい)。 でも細かい所でチクチク嫌がらせされたり嫌味を言われたりってのはありうると思う。 嫌いな子供だけ無視したり、他の子なら聞くような訴えでもその子が言った時だけは握り潰したり、そういう消極的な嫌がらせもあると思う。 僕はそういうのが「問題教員」って事だと思ってるんですよ。 (なので、以下で僕が「問題教員」と書いている箇所は、そういう横暴を働く人の事を指していると思って読んで下さい。)
そういうのを取り締まるのに、右翼か左翼かってほんとに関係あるんですか?
僕が言いたいこと、分かってもらえますでしょうか。 教員であるという立場を利用して、権力を笠に着て、横暴を働いて教え子を虐待するのが問題だと僕は思ってるんです。
体罰の問題と本質は同じですよね。 「教育のためなら『体罰も許されるのだ』」はNGだ、っていうコンセンサスが現状ですでに得られてるじゃないですか。 それと同じように、 「(平和|愛国)教育のためなら『横暴も虐待も許されるのだ』」はNGだ、っていうコンセンサスも得られるんじゃないですか?
もう1回書きますよ。 「教育のためなら『横暴も虐待も許されるのだ』」はNGだ、っていうコンセンサスは左右を問わず得られるんじゃないですか?
実際、左翼が行きすぎて共産党系組織からすら支持されなかったような人が、後に処分された事例もあるそうだし、不可能な事じゃないと思うんですよ。
仮に教育の現場に虐待の問題があって、現場が左翼に牛耳られていて、問題教員が左翼だから問題が表面化してないんだとしたら、なおさら、そういう人達の中の良識的な人達にも同意できる線で解決を図った方が実効性が高いんじゃないんですか? 虐待の問題を本当に早急に解決することを優先するなら、変な反論のできない、ぐうの音も出ない交渉の仕方をした方がいいんじゃないですか?
中立性の維持のためには左右両方が必要なんじゃないの?
「左翼の先生にそういう問題教員が多い」というなら、それは別にいいんですよ。 問題教員をばんばん取り締まった結果左翼先生ばっかりだった、っていうのはありうる話です。
仮にそういう状況なんだったら、「左翼先生を取り締まれば問題教員がいなくなる」っていうのも確かに真ではあります。 左翼先生が100人いて、そのうち50人がそういう横暴を働く問題教員で、左翼先生以外の先生に問題教員がいないんだったら、左翼先生を排除すれば確かに問題教員はいなくなる。 でも、問題教員じゃなかった50人はただの巻き添えです。
教育における政治的中立性を維持するにあたって、一人の人が完全に中立っていうのは非常に希だと、僕は思ってます。
教員には、大学で教職課程を取って、教員免許を取ってそのまま教師になって、学校という社会しか知らないまま大人になった人が多いと聞きます。 そんな世間知らずな先生が、右にも左にもかぶれないで中立を維持できるとは僕にはちょっと思えないです。 なので、右の人も左の人もいろんな思想の教員がいて、両方の話を聞いた子供が結果的に中立になる、というのが現実的な落とし所になるんじゃないかと僕は思ってます。
そう考えると、左翼先生だけがいなくなるのは宜しくないと僕は思う。 別の立場の人からの批判に晒されて考え方が洗練されていくという事が起こらなくなるのは、右翼にとっても宜しくない事だと思う。 批判に晒されてない洗練されてない考え方を盲目的に受け入れてるだけの人は、外に出てちょっと批判されたら、すぐ極端から極端に転向しちゃいますよ。「これが真実だったのだ!!」って目覚めて、良からぬ方向に走っちゃいますよ。
(だから、教員が左翼ばっかりだったらそれもマズイわけです。幼稚な左翼にかぶれてた子供が、ネットで「真実」に触れて一気にネトウヨ化、なんて今でもよくある話じゃないですか?)
問題をすり替えないで下さい
僕がここまでで書いた話を「議論のすり替えだ」って思いますか?
逆じゃないんですか? 問題教員に悩まされてきた人達のやり場のない怒りを、「それは左翼のせい」という政治的立場の話にすり替えて通報を募る方が、議論のすり替えなんじゃないんですか?
いや、自民党のフォームを作った人達がそこまで悪意を込めてやってたとは限りませんよ。 純粋に、彼らは彼らの思いがあって左巻きの教育を苦々しく思っていて、現状を調査したかっただけかもしれません。
(とはいえ、政権与党で、それなりに各方面に影響力の強い自民党が、左翼教師の通報を募ってたら、それって実質的にはやっぱり左翼狩りになるんじゃないの? と僕は思いますけど。)
自分の知る限りは2回の改訂を経て、自民党の件のフォームからは左翼を狙い撃ちにする感のある表現がなくなりました。 右翼思想の教員や、宗教思想の教員を通報するためのフォーム、というふうにも見えるようになっていますし、実際に当初からそのような教員の通報を期待しているのかもしれません。 右でも左でも関係無しに政治的偏り自体を問題視してたなら、最初からそうしておくか、あるいは、こういう余計なゲスの勘ぐりをされないためにも、左翼を想起させる例だけじゃなく右翼を想起させる例もそれ以外の例も併記しておいても良かったんじゃないかと思います。
でも、それでもなお、本来問題にするべきは権力を笠に着て横暴を働き虐待をする教員の方で、何らかの思想に偏っている教員ではないと自分は思ってます。
この文章を「左翼の左翼擁護だ」と思うのはべつにいいですよ。 事実として僕は左巻きを自覚してるし、問題教員としてよく語られる事例はどれも左翼教員ばっかりに見える(日教組が、というフレーズもよく目にします)から、事実として左翼の左翼擁護になってると言われたら否定はできないです。
でも、左翼憎しで雑に考えないで欲しいんですよ。 理性的であって欲しいんです。
これが逆に、共産党が右翼狩りを呼びかけてる例だったら、「ああまたアホなことを……落ち目の奴がそんなことやっても的を増やすだけやろ……」くらいで済ませてしまって、ここまで掘り下げて考えてなかったかもしれない。 「理性的に」って書いたけど、自分自身が理性的に考える前に感情で切り捨ててたかもしれない。 残念だけどそれも否定できないです。 でも、「せやろ。そんな程度の良識しか無いお前が言うなや」で済ませられてしまうのは嫌です。
右からでも左からでも上からでも下からでもどこからでもいいから、より本質に近いところに切り込んでいけるならその方が望ましいと思います。
くどくど繰り返し言うんですが、問題教員は実際いるし、そういう人達に苦しめられた人達が怒ってるのも分かるんですよ。 でも、それで理屈を忘れて本来叩くべき先と違う物を叩くのは、変だと思います。
僕からは、以上です。
選挙の時に熱くなってる人や政治活動に熱くなってる人を見て思った、18歳で選挙権を得た人達や、それより若い人達に伝えたい事 - Jul 09, 2016
僕は今33歳でもうすぐ34歳になろうとしていますが、16年前は17歳か18歳。 2016年7月10日の参議院選挙は選挙権が与えられる最低年齢が引き下げられて以後初の国政選挙で、当時の自分と同じくらいの年代の人も投票できるようになっています。 考えに考え抜いて投票先を選ぶ人も、自分が支持する人の方に勝って欲しいと思う人もいると思います。
当時僕には選挙権はありませんでしたが、それでもテレビで報じられる投票率の低さにイライラしていました。 みんなが選んだと言える事ならまだ納得できなくはないけど、みんなが選んだと言えないほど投票率が低くてどうして納得ができようか、と。
参院選を前にして、16年前の当時書いた文章がなぜか参照されていた形跡があったので改めて読み返してみましたが、いやぁ若いですね恥ずかしいですね。顔から火が出るなんてもんじゃないですね。でもこれも自分を形作ってきた物のひとつという事で、消さずに残しておくことにしました。
ところで昨今、僕が支持している考え方やそれに近い考え方の陣営が下手を打って自ら株を下げているように感じられゲンナリさせられることが度々あります。
中には、事実と確定していないデマと思しきものもあります。 しかし16年前の当時の自分や、自分が体験した事例を思うと、「やらかしててもおかしくない」と思わずにはおれません。 世間からも「こいつらならやらかしててもおかしくない」と見なされている、そういう風潮を感じます。 16年前の自分が書いた文章を読み返して恥ずかしかったのは、それも理由の1つだと思いました。
なので、そういった事例と絡めて、その頃の自分にも聞かせるつもりで、今現在自分が思っている事を改めて書き残しておこうと思います。
(ところで、大前提として選挙には行きましょうね。 そこは当時も今も相変わらず思ってます。 選挙権を20歳で得て以降、自分は今の所、公的な選挙は記憶にある限りでは全部行ってます。)
熱くなって馬鹿な事をしないで下さい
当時の僕は「選挙の後にガタガタぬかしても変わらない。選挙で物事が決まるんだ。だから選挙に行かなきゃいけないんだ。」という感じの事を語ってましたが、浅かったです。実際には選挙と選挙の間、選挙がない時の方が大事です。勉強と同じですね。普段勉強していれば試験でいい点が取れて、勉強してなければ点は取れない。試験は「普段のあなたがどうであるか」が可視化される機会でしかなくて、試験で点を取る事は目的ではありません。それと同じで、趨勢は選挙の前にだいたい決まっていて、選挙もそれが可視化されるというひとつの区切りでしかありません。
だから、選挙の時に熱くならないで下さい。
というか、選挙の時じゃなくても熱くならないで下さい。
我々には資金や組織力が無いからゲリラ戦を挑むしか無いのだ、みたいな自己正当化をして無関係の他の人の邪魔をしたり迷惑をかけたりしないで下さい。
自分は正しい事を広めようとしてるんだから少々の事は許されるのだ、みたいな思い上がりからルールを軽視し犯すような真似はしないで下さい。
「協力してくれるなら味方だ」みたいな二元論でもって無限の同意や無償の全面協力を強いたりしないで下さい。 ましてや、勝手に人の名前を使ったり意思を騙ったりしないで下さい。
(上記の例には、誰がやったのかも定かでない、事実かどうかも定かでない、という物も含まれています。が、前述の通り自分は「こういう事が実際あってもおかしくない」と思っていますので、以下の話はそれを前提として書きます。)
「今は特別な時だから」とか「自分は正しい事をしてるから」とか、そういう都合のいい例外を自分で作ってルールやマナーを勝手に歪めて考えないで下さい。 そういう傲慢さや、見識の狭さや、頭の悪さは、見透かされます。 そういう人を、良識を持ったまっとうな人は支持しませんし、好感も抱きません。
厳密に言えばグレーゾーンなんだから、黒と確定してるわけじゃないんだから、やっちゃった者勝ちなんだから、やっちゃえばいいじゃん。 「あいつら」がやってるんだから「こっち」だって同じことをやりゃいいじゃん。 おあいこで相殺されるでしょ。 そう思うかもしれませんが、周囲の第三者はそういう甘い判断をしてくれません。 良識ある人達は好意的に見てくれるはずだ、なんて思い上がらないで下さい。 良識のある人は、わざわざグレーゾーンに踏み込みません。 グレーゾーンに踏み込んだ時点で、良識のある人から見れば、あなたはもはや「良識が無い・一顧だにするに値しない、良識に反する敵」なのです。 そこを勘違いしないで下さい。
一発逆転を狙わないで下さい
なぜそんなに熱くなるのか。 当時の自分を思い返すに、「普段の鬱憤を晴らしたい」とか「今までの不利を一気にひっくり返したい」とか「今まで認められていなかったぶん、認められて評価されたい」とか、そういう思いがあったと思います。
選挙の前に趨勢は決まっている、世論という物はだいたい形成されている、という事は、なんとなく皆さん感じていると思います。 そういう物を自分一人の努力で容易に変えられはしないという事も、薄々分かっていると思います。 自分が思った事とか考えた事を披露しても聞いてもらえない、賛同も得られない、言えば言うほど嫌われ避けられる、それどころかそもそも言いだす事すら憚られる、そんな感覚がなんとなくあるんじゃないでしょうか?
だから、選挙というタイミングで一発逆転したくて、もしかしたら一発逆転できるかもと期待して、熱くなるのではないでしょうか。 少なくとも僕は、そう考えていたと思います。
そんな風に虫のいい事を考えているから、嫌われるような事をやらかすんですよね。 今になって改めて、自分はそう思います。
虫のいい事を考えている間は、そういう考えを捨てられないという本質的な人間性が変わらないままでは、「ルールを守って」とか「マナーを守って」とかそういう事に気をつけようとしても、どうせできやしません。 先に挙げたような迷惑行為を表面的に慎もうとしても、違った形で迷惑行為をやらかします。 絶対にボロが出ます。 コーラを飲んでゲップを我慢しても、代わりにオナラが出るのです。
一発逆転できなくてもヤケにならないで下さい
一発逆転を目指さない、とはどういうことか。
- 地道に誠実にやる
- 嘘はつかない、捏造もしない、根拠のある事実に基づいて話す
- 悪あがきしない、自分の非は素直に認める
今の僕は、これが大事な点だと思ってます。
そういう風にやったからといって、人に好かれる保証は無いし、支持される保証もありません。 結局誰にも賛成してもらえないまま、というオチだって十分にあり得ます。 非を認めた途端に、「それみたことか」と得意げに叩き出す人も出てくるかもしれません。 でも、それでも誠実にいきましょう。 それが最低条件です。
僕のここまでの人生、わりとそんな感じです。 自分ではなるべく嘘をつかず真面目にやってきたつもりですが、「大多数の人の圧倒的な支持」は得られていません。
大多数の圧倒的な支持を得ていれば勝ち、そうでないなら負け、という考えであれば、僕の現状は「負け」ということになるでしょう。
でも実際には、僕の活動を意義ある物として評価してくれる人はいて、たまに誉められたりもしてます。 嘘・虚構で得たわけでなく、事実を積み上げた上で得られた評価なので、これは確かな物だと自負しています。 「勝つ」か「負ける」かの2値でだけ考えていると、こういうものを見落としてしまいます。
話を聞いてもらえないからってヤケにならないで下さい
「耳障りのいい嘘をつかなきゃ聞いてもらえないじゃないか」 「嘘でもなんでもいいから聞いてもらえなきゃはじまらないじゃないか」 そんな事はありません。それはあなたの考え違いです。 嘘も捏造も無しに正直に話していて、話を聞いてもらえている人はいくらでもいます。
ただし、「あなたが正直に話しさえすれば、誰でも話を聞いてくれる」訳でもありません。 正直に話しても聞いてくれない人はいます。
人に話を聞いてもらえないなら、その人が興味を持ってくれて聞きたくなってくれるような話し方を考えましょう。 間違っても、無理矢理肩を引っ掴んで聞かせるような事はしないで下さい。
話を聞いてもらえないのは、聞く気が無い相手が悪いのではなく、聞く気にさせられないあなたが無力なのでもなく、あなたと相手が違う人間だからです。 そこが分からない限り、永遠に話は聞いてもらえませんし、聞いてもらえても恐らく、「分かってもらえた」と満足できる事は無いでしょう。 相手があなたのコピー人間でもない限り、「あなたが満足できるようなレベル」で相手があなたの考え方を受け入れて同意してくれることはありません。 相手に期待しすぎないで下さい。
若くて熱くなっている人にはなかなか理解できないかもしれませんが、自分と違う人生を生きてきて、自分と違う考え方をしていて、自分とは相容れない考えを持っている、そういう人達を貶すでもなく取り込むでも無く、そのまま死ぬまでお互いに平行線を行き続けながら、同じ船に乗り続けるのが社会というものです。 「自分と違う考えの人がいなくなればいいのに」とあなたが思うのなら、相手の側から見ても「自分と考えが違うこいつはいなくなればいいのに」と思われています。 あなたは安全地帯にいるわけではありません。 それを念頭に置いて、「何事もお互い様だ」という事を忘れないで紳士的にやって下さい。
それが格好いい大人という物だと、今の自分は思っています。
2016年の現場からは、以上です。
「技術書典」参加しましたれぽ - Jun 26, 2016
技術書典に参加してきましたので、MozLondonの技術面以外の話をほったらかして先にこっちの話を書いておきます。

技術書オンリーイベントとは?
個人や小規模の団体などによる自費出版物=同人誌の即売会には「オールジャンルイベント」と「オンリーイベント」の2種類があります。「コミックマーケット」はオールジャンルイベントの代表例で、マンガ小説評論写真集その他色々な種類・内容の作品が取り扱われています。一方のオンリーイベントでは、取り扱われる作品が「艦これオンリー」や「弱虫ペダルオンリー」のように特定のタイトルのファンアートだけだったり、「耳キャラオンリー」のように特定のキーワードに関係する作品だけだったりという風に、イベント全体が特定のジャンル性を帯びています。
オールジャンルイベントには電子工作の話だったりプログラミングの話だったりという技術的な話題を扱う作品も出展されていることがあり、これらは大まかに「技術系ジャンル」という括りになっています。このジャンルの(おそらく初の)(自分が知らなかっただけで前例はあったようです)オンリーイベントが、今回の「技術書典」というわけです。
そういう文脈なので、イベントの体裁は自分が見たところまさしく「同人誌即売会」という感じでした。他のオンリーイベントとの違いというと、そこに「企業ブロック」という扱いで、OSCの会場で見かけるような翔泳社やオライリーといった技術書に強い出版社の販売ブースが普通のサークルと机を並べて存在していたという点でしょうか。
シス管系女子のスペース
今回は、自分は「シス管系女子」の名前で企業として参加しました。企業参加とはいっても日経BP主導ではなく、僕個人が技術書典の情報を見つけて「参加したい!」と言ってゴネて、頒布物作りや当日の作業は自分でやるということでスポンサードして頂いた感じです。基本的に商業出版物は企業参加で申し込むようにというレギュレーションもありましたし。
シス菅系女子!!!#技術書典 #通運会館 #2F pic.twitter.com/pl7prmf4Ev
— 戸倉彩@C90日曜日(西4f38a) (@ayatokura) 2016年6月25日
(写真を撮り忘れたので戸倉さんのツイートを引用)
頒布物は新作描き下ろし(ただし下描きクオリティ)の8ページのコピー本と、既刊のムック2冊でした。 コピー本の内容はpixivにまるっと上げてあります。 そのうちシス管系女子の特設サイトにも載せるつもり。
<script src="http://source.pixiv.net/source/embed.js" data-id="57590783_33fd1695fde5334093fd08b34d503ac6" data-size="medium" data-border="on" charset="utf-8"></script><noscript>
シス管系女子BEGINS 第0.1話 by Piro on pixiv
</noscript>最初は普通にスペースに置いておいて、本を買って下さった方に渡したり、見てくれた人に「無料です」と言ってそのまま持って行ってもらったりというつもりでいたため、100部持ち込んで(コミケの技術島だったら「多すぎやろ」レベルの数)余ったらOSC等の会場でチラシのスペースに置いてもらうとかすればいいかなーと思っていたのですが、ヘルプで入ってもらった売り子さんの提案で「どうせ無料ならどんどん配った方がいいのでは?」という事になって、配り始めたらあっという間に足りなくなってしまいました。幸い、会場から徒歩で行ける距離にキンコーズがあったため、なくなりそうになったら行ってセルフコピーで200部増刷するという事を2回繰り返して、閉会30分前くらいの時点で合計500部を配りきりました。 (イベント側でも当日増刷システムなどの試みをしていたようですが、自分は制作フォーマットが違った&毎度の通り作業がギリギリになってしまって申し込めなかったので、自力解決したという次第……)
ムックの方は各30部ずつ持ち込んで、それぞれ残り5~6冊くらいになるまでは出ました。という所から売り上げはすぐに計算できるのですが、まぁ企業として動くには明らかに赤字なので、今回は日経BPサイドにはプロモーションと割り切って頂いた感じです。
見ていた感じだと、手に取っていただいた方には「初めて知った」という人が多かった印象で、費用対効果はさておき「今まで到達できていなかった人に認知してもらう」という事はそれなりに実現できたのではないか?と思っています。 内容の質にはわりと自信がありますので、今後もこんな感じで、今まで届けられていなかった方に届けられる方法を考えていきたいです。
あと、今回スケブ依頼は無かったのですが、会場では何人かの方にサインのご依頼を頂いたので書かせて頂きました。焦りもあって線が結構ヨレヨレになってしまいました……すみません。
会場の様子
着いてみると結構会場が狭くて、開会直後から行列がすごいことになっていたようですが、早々に入場方式を整理券方式に切り替えたらしく、会場内の人口密度が一定以上にならないようコントロールされていました。そのため、外の「何時間待ち」といった情報とは裏腹に、中は割合ゆったりとした雰囲気が保たれていたのが印象的でした。 技術系の同人誌は試し読みをするにもじっくり読む必要のある物が多いと思われるので、これは本当に良い判断だったと思います。運営のファインプレーですね。
自分も比較的ゆっくり会場を回って他のスペースの頒布物を見て回ることができ、会場の空気にあてられて結構買い込んでました。
 技術系の同人誌は分厚かったり部数が少なかったりで製造原価が高いために、頒布価格の相場が結構高いのが、普段自分がコミケ等で参加するマンガ系ジャンルとは違うものなんだなあ……と今更実感。
技術系の同人誌は分厚かったり部数が少なかったりで製造原価が高いために、頒布価格の相場が結構高いのが、普段自分がコミケ等で参加するマンガ系ジャンルとは違うものなんだなあ……と今更実感。
前例の無いイベントということで一体どれくらいの人が来るのか全く予想ができず、もしかしたら会場内のサークル参加者同士でお互いに見て回って終わりくらいの規模になるのかもと思っていたのですが、主催者発表によると一般入場者が最終集計で1300人に達していたとのことで、想像を遙かに上回る盛況ぶりに参加者として驚くばかりです。
商業出版物の流通経路に載せるほどの売り上げは見込めないけれども、この事について書きたいんだ!とか、こういう技術本を作りたいんだ!というような作り手側の思いから作られた作品達。 そういった物が集まり、読み手は作り手から直接その思いを聞けて、作り手は読み手の反応をダイレクトに得られる、というのはオフラインイベント独特の魅力だと改めて感じました。 技術書典 当日の様子でも次回開催を望む声が多く見られますし、小説・評論ジャンルのオンリーイベント「文学フリマ」が回を重ねるのみならず地方開催も行っているように、技術書典も「技術ジャンルのオンリーイベント」として確かな地位を確立していってくれるといいなあ、と思います。
続き:技術書典2のレポート
Mozilla All Hands in London 2016 イベントレポート:技術編 - Jun 20, 2016
現地時刻で2016年6月13日から17日にかけて行われたMozilla All Hands in London、通称MozLondonに参加してきました。

最近はこの種のイベントに参加する機会が減ってしまい、「えっ、Mozilla関係で何かやってる人だったの?」みたいになってそうな気がするので、ちょっと記録を残しておこうと思います。
Mozillaの活動に関わっている人はMozillaの雇用スタッフもそうでない人も世界中に散らばっていてコミュニケーションコストが高いので、半年ごとにAll Handsと称して社員と外部の開発者を一箇所に集めて色々話し合っています。 ただ、社員は全社員が招集されるのに対して、自分のような外部の人は活動のアクティブさの度合いなどに応じてボランティア枠で招待される形です。 自分は連絡を頂いた時点ではBugzilla上でそんなにアクティブではなかったのですが、今回はアドオン作者へのヒアリングということでアドオンチームの方から推薦を頂いたようです。 「ボランティア」とはいっても招待なので、交通費・食費・宿泊費は全部Mozilla持ちでした。
Migration story of the Popup ALT Attribute from XUL/XPCOM to WebExtensions - Apr 19, 2016
Recently I wrote a blog entry for developers of addons for Firefox, who are planning to migrate his/her XUL-based addon to WebExtensions. This is the full version which includes some side topics not related to WebExtensions. I hope this helps you to migrate your ancient addon to WebExtensions.
タブのツリーを最適な段数で段組表示する - Mar 06, 2016
ツリー型タブの最近の改善でやったことをまた地味に解説するよ。誰得な記事。
ツリー型タブには、「ブックマークからタブを複数開いた時に1つのツリーになってた方がいいけど、でもツリーにするには親になるタブが必要で、だからといって同列のブックマークの中で1つだけが親になるのってなんか違和感あるよね」という場面のための「グループ化専用のダミーのタブ」を開く機能がある。というか、about:treestyletab-groupというURIを読み込んだタブはそういう用途のタブとして扱うようになる。そのときタブの内容が空っぽだと味気ないので、そのタブ配下のタブのツリーをタブの内容として表示するようになっている。
それとはまた別の話で、ツリーになっているタブの上でしばらく待つとそのタブ1つだけじゃなくて配下タブの名前も一緒にツリー表示して、さらにもう少し待つとそれらがリンクに切り替わってクリックしたらそのタブに切り替えられる、という機能もある。
見た目で分かるかもだけど、これらのツリーを生成する部分は共通のpseudoTreeBuilder(疑似ツリー)というモジュールになってる。
この疑似ツリーは、ちょっと前までのバージョンでは、タブの数が多くなるとそのままツリーが下に伸びていって、ウィンドウやツールチップの高さに収まらなくなった分はスクロールして見るという仕様になってた。 元々、おまけの機能だからそれほど作り込む必要性も感じてなかったんだけど、未処理のissueがたくさん溜まってたのを断捨離してたらその中に「このツリーをマルチカラム表示して欲しい」という要望があった事に気がついた。
このエントリを書くにあたって改めて調べ直してたら、別のもっと古いissueでは否定的なことを自分で言ってたみたいなんだけど、実際自分で使ってて「長いタイトルが折り返されるという事もなく巨大なツールチップが画面を覆い尽くして、そのくせちびちびスクロールしないと全項目は確認できない」という状況に意外とイライラしていたため、この機会に「じゃあやってみっか」と手を着けてみた。
で、最終的にはどうにかそれらしくマルチカラム表示できるようなった。
基本的にはCSSのマルチカラム機能を使ってるんだけど、ツールチップの方で僕の意図したとおりの結果を得るためにはちょっと工夫が必要だった。
「ツールチップの方で」と限定したのは、後で分かったんだけど、タブの中に表示する方はそこまで苦労しなくても勝手にいい感じにGeckoがレンダリングしてくれるから。 なので先にそっちの方から書いていきます。
コンテナの幅や高さが最初から決まっている場合(コンテンツ領域の中)
先に要件を整理しよう。
- 項目をコンテンツ領域の中で2~3列くらいで段組表示したい。
- 個々の列はコンテンツ領域の高さを越えないようにしたい。 スクロールバーを出すのは横方向だけにしたい。
まずコンテナとして、コンテンツ領域いっぱいに広がるボックスを置いておく。
コンテナには、内容が溢れたらスクロールできるようにoverflow:autoも指定しておく。
#tree {
overflow: auto;
box-flex: 1;
-moz-box-flex: 1;
}
で、この中に置くツリーをマルチカラムにしたいわけなんだけど。
CSSのマルチカラム表示を有効にするだけなら、マルチカラムにしたい内容を含む上位の要素に列の数か幅を指定してやればいい。
2列なら、こう。この場合、列の幅はコンテナの半分になる(自動的に決定される)。
#tree > .treestyletab-pseudo-tree-root {
-moz-column-count: 2;
/* -moz-columns: 2 auto; と同等 */
}
列幅固定なら、こう。この場合、コンテナの中に1列しか収まらない時はマルチカラムにならないという、いわゆるレスポンシブデザイン的な挙動になる。
#tree > .treestyletab-pseudo-tree-root {
-moz-column-width: 20em;
/* -moz-columns: auto 20em; と同等 */
}
列数固定だとウィンドウの幅が広いときに余白ばかり広がってしまってあまり嬉しくないので、ツリー型タブではとりあえず主観で20emと指定してみた。
自分の使ってる環境では、これでだいたい2~3列になる。
マルチカラム表示したいツリーを構成しているXUL要素の中で、内容が複数列に泣き別れてもいい物(=「1つのタブ」に対応する「アイコンとラベル文字列のペア」以外のすべてのボックス)は明示的にdisplay:blockにしないといけない。
display:-moz-boxのままだと、要素の作るボックスは途中でぶった切られる事が無いので、マルチカラム表示にはならない。
/* required to apply CSS multi columns */
#tree > .treestyletab-pseudo-tree-root,
#tree > .treestyletab-pseudo-tree-root vbox {
display: block;
}
当初はこれに気付いてなくて、わざわざXHTMLとXULを混ぜて実装してた。
でも、後になってからdisplayの値を変えればXUL要素でも問題ない事が分かったので、今は全部XULに戻してある。
問題1:縦に長くなる
しかし、これだけだと項目の数が多い時に「縦に長いツリーがマルチカラムで表示される」「画面に収まらなかった部分は下にスクロールしないと見えない」ということになる。
こういうのは一覧性が悪くて死ねる。 だって、左の列を上から順に下まで見た後、次の項目を見るにはまた一番上までスクロールし直さなきゃいけないんですよ? あり得ないでしょ……
つまり、各列がコンテンツ領域の高さより高くなられると困る。 項目の数が多いときは、「縦に長ーいリストを2列で表示する」んじゃなくて、「コンテンツ領域の高さに収まる短いリストを3列、4列と列を増やして表示させる」方がいい。 ということ。
じゃあってんでさっきの要素に最大の高さを100%と指定してみても、これは効果がなかった。相変わらず、親のボックスの大きさを超えてスクロール可能なまま。
#tree > .treestyletab-pseudo-tree-root {
-moz-columns: auto 20em;
height: 100%;
}
なので、resizeイベントでコンテナの高さを調べて、その都度ピクセル値で適切な高さを指定するようにしてみたら、ようやく縦のスクロールバーが消えて横方向にスクロールできるようになった。
...
this.window.addEventListener('resize', this, false);
...
handleEvent : function GT_handleEvent(aEvent)
{
switch (aEvent.type)
{
...
case 'resize':
return this.onResize();
...
}
},
...
onResize : function GT_onResize()
{
...
var container = this.document.getElementById('tree');
var tree = container.firstChild;
PseudoTreeBuilder.columnizeTree(tree); // ここでcontainerの高さをtreeのheightにピクセル値で指定し直す。
},
CSSのマルチカラムでは「列の数」の指定は絶対ではなくて、コンテナの幅と高さから溢れた分の内容は自動的に列の数を増やして表示するようになってる。
コンテナがoverflow:autoになっていれば、溢れた分は横スクロールすれば見える。
問題2:下に余白ができる時がある
全体の高さを指定していても、項目の数が「全部1列で表示するには多いが、2列を埋めるには足りない」程度の時には、領域の下の方に妙に余白が出てしまう。
これは-moz-column-fill:balanceという初期値のせい。この指定の時には、各列の内容の高さがなるべく揃うようにレイアウトされるため、結果として下の方に余白が産まれることになる。
まぁそれはそんなに悪くはないんだけど、今までコンテンツ領域の高さいっぱいまで並んでた物が急にその半分とかくらいの高さになるのは気持ち悪い。 違和感が無いのは、やはり、領域の高さに収まらなくなった分からちょっとずつ次のカラムに流し込まれていくという感じだろう。
そのための指定が-moz-column-fill:autoで、これを指定しておくと、1列目は下まで項目が埋まって、入りきらなかった分だけが2列目に溢れるようになる。
実は、この-moz-column-fill:autoを使うのにも、ボックス全体の高さを明示的に制限しておく必要がある。
というのも、-moz-column-fill:autoの時は「高さが指定の高さに収まらなかったときに、その分を次のカラムに流す」という事になるので、高さが未指定だと「内容が溢れることもないからいつまで経ってもマルチカラムにはならず、縦にどんどんリストが伸びていく」という結果になってしまう。
……というわけなので、やっぱり全体の高さはスクリプトで動的にピクセル値で指定してやらないといけないのでした。
コンテナの幅や高さが決まっていない場合(ツールチップ)
こちらも要件を整理する。
- ツールチップの中で項目を2~3列くらいで段組表示したい。
- ツールチップは画面を覆い尽くすほどの大きさにはなって欲しくない。 最大の幅と高さは制限したい。
- 必要以上の余白は要らない。 小さく表示して問題無いなら、小さく表示したい。
ここで曲者なのが3つ目の要件。 コンテンツ領域の中であれば「与えられた領域の中を最大限使って、残りは余白扱いにすればいい」ということになるんだけど、ツールチップだとそうもいかない。 というか、必要最小限のサイズで出てくれないと困る。 「内容を表示するのに必要な最小の大きさをどうやって決めるのか?」 これがツールチップの場合の難しい所だ。
先に結論を言ってしまうと、「とりあえず許されてる最大の大きさで試しにレンダリングしてみて、その後、実際に必要な大きさで改めて表示し直す」というのが答えになる。
大きく表示してから小さく縮めるのって格好悪くない?
とはいうものの、ツールチップを1回表示した後そこから小さく縮めるというのは見た目が宜しくない(一瞬だけとはいえ目に見える状態で大きなツールチップが出るというのはイラつきますよね)。
じゃあどうすれば?という事になるんだけど、逆転の発想というかなんというか、ツリー型タブでは「そもそも最初からベストのサイズで表示する事は諦める」という解決策をとっている。 どういう事かというと、いきなり違うサイズのツールチップを出すとギャップで見当識を失うので、まずは元の普通のツールチップと同じ大きさ・位置で1回表示して、そこからアニメーションでツールチップを必要な大きさまで拡大する、という事をしてる。
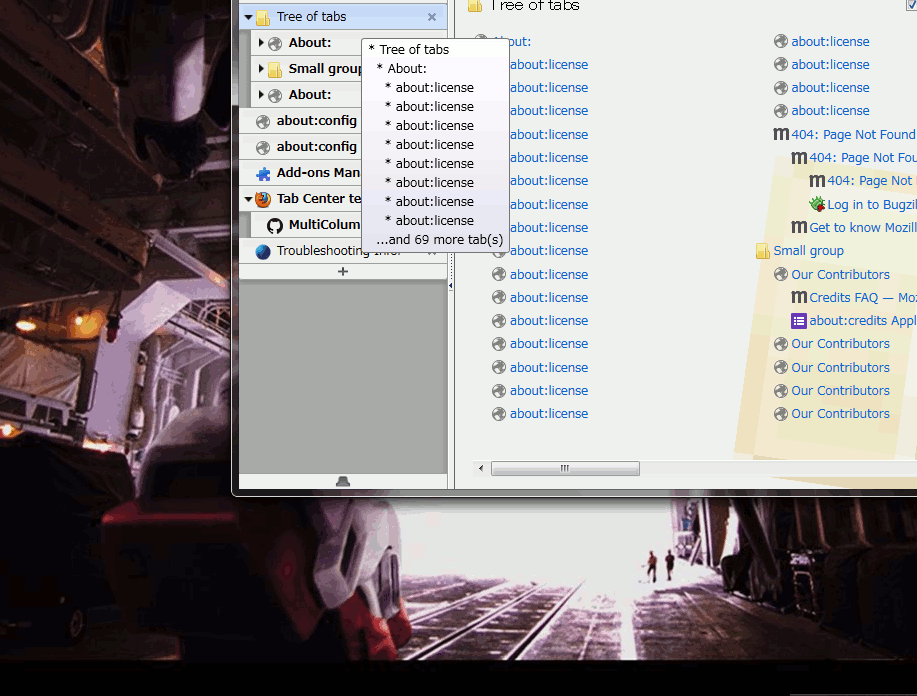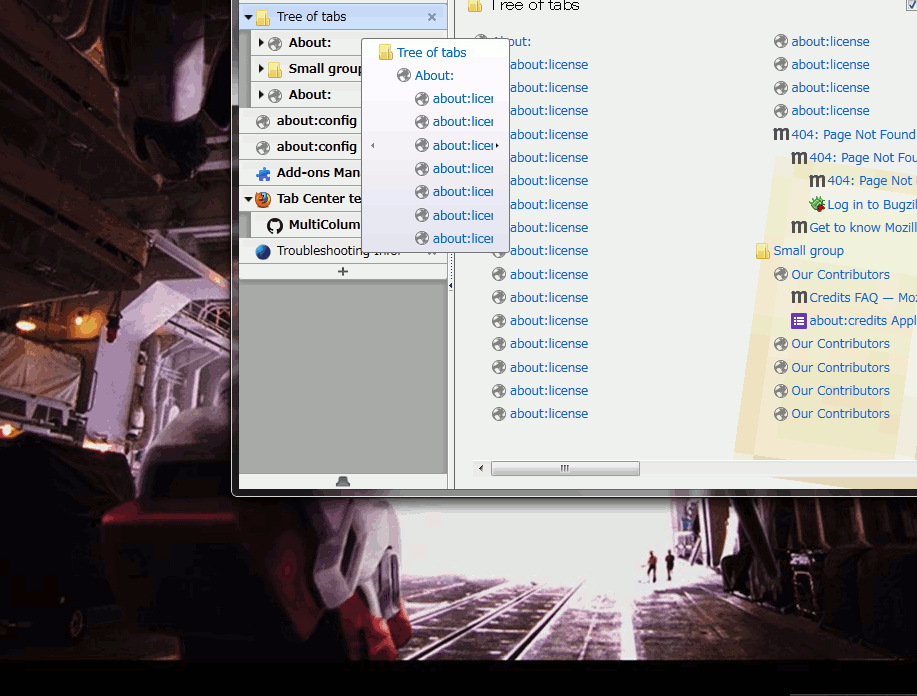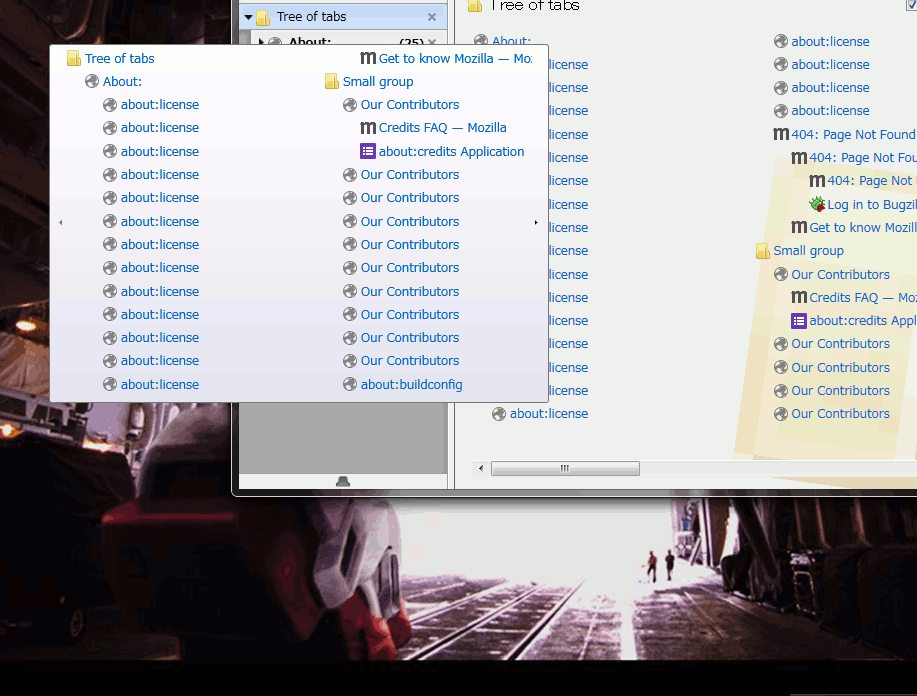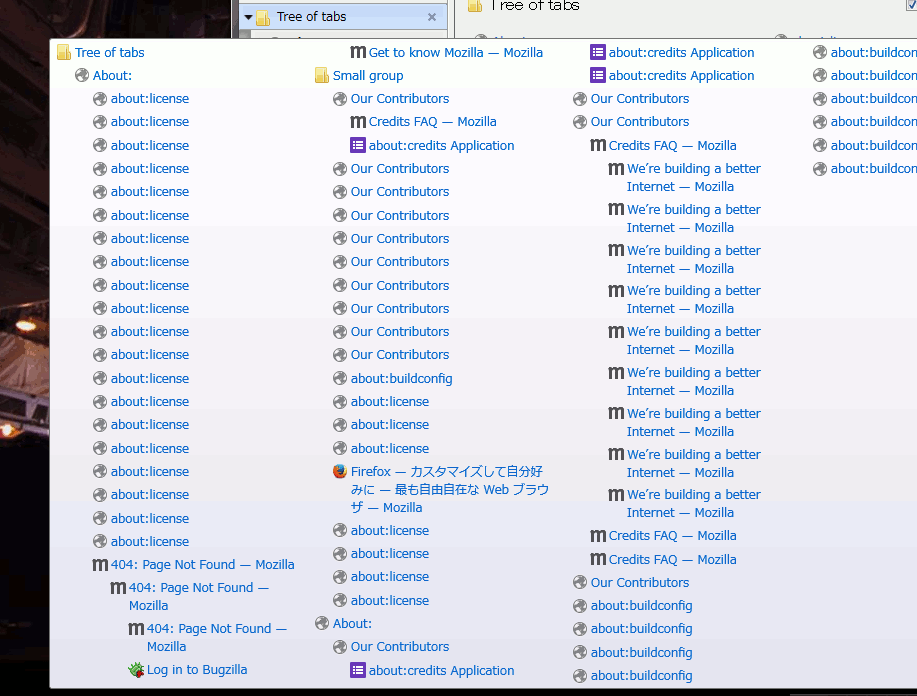
ツリー型タブの高機能なツールチップはだいたい元のツールチップよりは大きくなるので、この「1回小さめのサイズで表示した」状態で必要なサイズを確定させて、後からゆっくり拡大すればいい。
元より小さなツールチップで何故「最大の大きさで試しにレンダリングしてみる」ができるのかというと、XULのarrowscrollbox要素を使ってるから。 これは元々は、ツールチップが画面いっぱいに広がっていてもまだ内容が収まりきらない時のための対策として使っていた。 arrowscrollboxは中にどんなに大きな物を置いてもそれ自体やその親(ツールチップ)の大きさが広がらないので、安心して「めいっぱい大きく表示して、最小限必要なサイズをその結果から割り出す」ということができる。
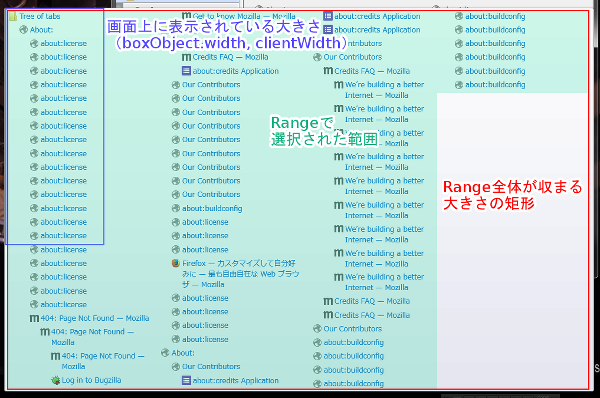
ツリーを収めるのに最適なサイズの求め方
「幅も高さもいい感じにする」というのは難しいので、ツリー型タブの場合はまず「画面の全体を覆い尽くさない程度」ということで画面の高さの70%(例えば画面が縦1024ピクセルなら、その7割の717ピクセル)を最大の高さとして、その中でマルチカラム表示の指定を反映させている。
arrowscrollbox > .treestyletab-pseudo-tree-root {
-moz-columns: auto 20em;
-moz-column-fill: auto;
height: 717px; /* ←実際にはその都度計算する */
max-height: 717px; /* ←実際にはその都度計算する */
}
こうすると、高さについては指定の高さまでに収まって、幅は必要な分だけ自動的に列が増えていくという形で、ツリー全体を収めるのに必要な領域を確定する事ができる。
高さは既に分かっているので、残るは幅なんだけど、これはツリー自体のboxObject.widthやclientWidthからは分からない。
というのも、この時点でのマルチカラム表示されたツリーは「列の幅は指定されているが列の数は指定されていないので、要素自身の幅を超えて列が表示されている(可能性がある)」という状態で、要素自体の幅を調べても意味がないのです。
overflow:autoになってる要素の幅を計測しても中身の幅は分からない、というのと同じね。
こういう時の「本来の内容の幅」は、RangeのgetBoundingClientRect()で調べられる。
これは、DOMのRangeが含んでいる範囲の全要素が収まる矩形の位置や大きさを計測してくれるという便利なAPI。
これを使ってツリーの要素の「内容を」選択してそのサイズを測れば、ツリー全体を収めるのに本当に必要な最小のサイズが分かる。
var range = tree.ownerDocument.createRange();
range.selectNodeContents(tree);
var rect = range.getBoundingClientRect();
range.detach();
あとは、ツールチップ全体を広げるだけ。 「ツリー全体を収めるのに必要な幅」と「画面の幅さの80%(例えば画面が横1280ピクセルなら、その8割の1024ピクセル)」のどちらか小さい方をツールチップの新しい幅にしてやる。 ツリーはツールチップの中のarrowscrollbox要素の中に置かれているので、ツールチップがツリーよりも小さければ、はみ出た部分はスクロールして見る事ができる。
まとめ
以上、マルチカラムなポップアップをいい感じに表示するためのノウハウの話でした。
実は、ここに書いた内容はmasterのHEADでの話で、解説を書くにあたって調べ直した結果の洗練された内容になってる。 今リリースしてるバージョンでは、そこまで洗練されてない状態の(でもだいたい同じような結果を得られている)コードになってるので、どこが無駄だったのかを洗い出して「こいつ技術力低いなあ!」と笑いものにしてくれていいです。
それにしても、昔なつかしNetscape Communicator 4では、フォルダの中にブックマークが大量にあるときはこんな風に段組表示してくれて一覧性が高くてものすごく便利だったんだけど、Geckoエンジンベースで作り直されたNetscape 6以降や、その流れの先にあるFirefoxには、その機能はついぞ引き継がれなかった。 業を煮やして複数のポップアップを並べることで擬似的に再現できないか?という実験をしてみたこともあったんだけど、不安定でダメだった。
今だったら、このやり方で行けるんじゃないか?という気がする。 というか、SUMOの質問に寄せられてる回答でStylish用のスタイルシートが公開されてて、2つの例のうち1つはCSSマルチカラムでやるようになってたので、間違いなくできる。
ただ、例に挙がってるStylish用のスタイルシートはカラム数が固定されていて、1列でいい時にまで常に2列3列になってしまうという問題がある。 ネスケ4の頃のそれのような使い勝手を実現するには、ここで解説したような細かい調整をやらないといけないんだと思う。 僕自身はやる元気がないので、誰か代わりにやってくれないかなあ……と、実現する見込みの低そうな事をネットの片隅でこっそり呟いてみる次第です。
スクロールバーの見た目を保ったまま細くする - Feb 18, 2016
ツリー型タブではタブバーに表示するスクロールバーについて、普通のスクロールバーよりも細く表示するようにしてるんだけど、その実装方法に少し改善があったので誰得だけど解説しておく。
ちょっと前までのバージョンでは、単純にCSSのmax-widthで以下のように実現していた。
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"],
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"] * {
max-width: 10px;
min-width: 10px; /* この指定がないと逆に最小サイズが大きくなってしまう */
}
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"] {
font-size: 10px;
}
この方法の難点は、一部のプラットフォームで……というかWindowsでスクロールバーの端のボタンの表示がずれるということ。
 スクリーンショットを見ると、「▼」がちょっと右にずれてるのが分かる。
何故こうなるかというと、Windowsのスクロールバーの端のボタンのアイコンは最小サイズが大きめに定義されているようで、それよりも小さなサイズを指定してもWindows側の最小サイズが優先されてしまうせい。
スクリーンショットを見ると、「▼」がちょっと右にずれてるのが分かる。
何故こうなるかというと、Windowsのスクロールバーの端のボタンのアイコンは最小サイズが大きめに定義されているようで、それよりも小さなサイズを指定してもWindows側の最小サイズが優先されてしまうせい。
この問題は、実用上は問題がないので長らく放置してたんだけど、最近ツリー型タブのissue trackerで閉じられてないままの古いissueを断捨離してる時にもっとこうしたらいいよという提案があったことに今頃気がついて、その方針を最近のバージョンで採用してみた。
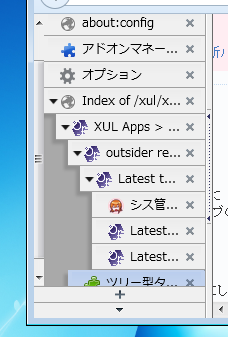
これはどうやってるのかというと、スクロールバーの幅を小さくする代わりに、「スクロールバーの左右にマイナスのマージンを設定して他の要素の下に潜り込ませる」ことで、擬似的に細く見せている。
何ピクセル潜り込ませるかは環境によって変わってくるので、document.getComputedStyle()なども使ってその都度計算するという面倒なことをしている。
これで、「▼」がずれるということがなくなった。
しかし、今度は副作用としてタブバーの背景色を変えている時に表示が変になるという問題が起こってしまった。
例えばClassic Theme Restorerをインストールして且つ「Mixed」スキンを選択した状態だと、水色の背景の一部がグレーになってしまってた。
 これは、先の「マイナスのマージンを設定して他の要素の下に潜り込ませる」という手法において、スクロールバーが潜り込む先となる(スクロールバーの上に載って一部を覆い隠す)ボックスの背景色の指定が必要となってしまって、決め打ちで指定した色がユーザのカスタマイズ後の色と違うせいで見えてしまっているということ。
タブバーの背景色を変える方法はuserChrome.cssやらテーマやらClassic Theme Restorerやら色々とあるので、すべての場合にマッチする万能の対策は事実上無い。
これは、先の「マイナスのマージンを設定して他の要素の下に潜り込ませる」という手法において、スクロールバーが潜り込む先となる(スクロールバーの上に載って一部を覆い隠す)ボックスの背景色の指定が必要となってしまって、決め打ちで指定した色がユーザのカスタマイズ後の色と違うせいで見えてしまっているということ。
タブバーの背景色を変える方法はuserChrome.cssやらテーマやらClassic Theme Restorerやら色々とあるので、すべての場合にマッチする万能の対策は事実上無い。
ということで頭抱えてしまって、なんとかスクロールバーの潜り込んだ部分(はみ出た部分)を綺麗に消す方法はないかと、思いついた方法を色々試してみた。
- スクロールバー全体にネガティブマージンを指定するのがアウトなら、ボタン部分だけネガティブマージンを指定するのはどうか?(元々、ボタン部分以外は
max-widthでちゃんと細くできてたんだし)と思って試してみたら、ボタン部分だけがスクロールバーからはみ出すという結果になってしまった。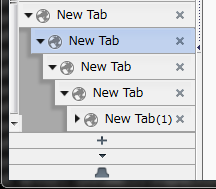
- 横方向にはみ出した部分を見えなくする、というと
overflow-x:hiddenだな!と思って、スクロールバー全体にこれを指定してはみ出したボタンだけをどうにかしようと思ったけど、実際やってみたらスクロールバー全体の動作がぶっ壊れてしまうので駄目だった。
万策尽きてDOMインスペクタの画面とにらめっこしてた所、clipという名前が見えた。そういえばCSSにはそういう機能もあるんだった。試したこと無かったから、じゃあそれで行けるんじゃないか?
ということで実際試してみたんだけど、これもスクロールバーのボタンには効いてくれなかった。
でも、MDNのプロパティ解説を見るとdeprecatedと書いてあって、誘導先を見たらclip-pathを使えと書いてある。
clip-pathというとFirefoxのタブの見た目などを丸くするのに実際使われてるプロパティだったはずなので、こっちなら大丈夫だろうと思って再挑戦したら、ようやくうまくいった。
 Classic Theme Restorerとの併用時にも何ら問題がないことが見て取れる。
Classic Theme Restorerとの併用時にも何ら問題がないことが見て取れる。
実装は以下のようになってる。
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"] {
font-size: 10px;
max-width: 10px;
min-width: 10px;
clip-path: url(#treestyletab-box-clip-path);
}
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"] * {
font-size: 10px;
max-width: 100%;
min-width: 10px;
}
tabs.tabbrowser-tabs
.tabbrowser-arrowscrollbox
> scrollbox
> scrollbar[orient="vertical"] scrollbarbutton {
font-size: 10px;
margin-left: -3px;
margin-right: -2px;
}
参照してるSVGのクリッピングパスは以下の通り。
<svg:svg height="0">
<svg:clipPath id="treestyletab-box-clip-path"
clipPathUnits="objectBoundingBox">
<svg:path d="m0,0 V1 H1 V-1 H-1 z"/>
</svg:clipPath>
</svg:svg>
このクリッピングパスはどういう形かというと、仮想的なキャンバス全体を覆い尽くす矩形になってる。mから始まる相対指定で(0,0)から(1,1)までを覆う矩形を作っている(左上から始めて、下、右、上、左と反時計回りに進んでパスを閉じてる。最初は逆方向の時計回りに回ってしまってうまくいかなかった)ので、クリッピングパスの適用対象になるボックスがどんなサイズであってもそれと同じ大きさになる。
スクロールバーに対してこのクリッピングパスを反映すると、この矩形からはみ出る部分、つまりネガティブマージンではみ出してるボタンが切り取られて表示されるようになる、というわけ。
今回の実装自体のノウハウをそのまま流用できる場面はそうそうなさそうだけど、なんかの機会にまた使うかもしれないので、解説してみた。
要点をまとめると、「要素のスクロールの可否といった動作に影響を与えないで、見た目の表示サイズだけを小さくしたい時は、clip-pathを使うとよい」といったところでしょうか。
以上、ちっこい三角ひとつのためだけに四苦八苦させられた話なのでした。
Firefoxのマルチプロセス機能を強制的に有効化する方法まとめ - Feb 17, 2016
アドオンのe10s対応のための作業をしようと思うと当然e10s有効状態でFirefoxを動かしとかないと意味ないんだけど、まだ完成度が低いということでかe10sは事あるごとに勝手に無効化される。すぐ死ぬ。マンボウかスペランカーかってくらいに、気がついたら勝手に無効化されてる。
なので、主に法人ユーザ向けの集中管理機構を使って、アドオンのデバッグ用の環境ではe10sを有効化するための設定を強制するように設定した。 autoconfig.cfgの内容は以下のようにした。
// 1行目は必ずコメントとする。
// 基本的な有効化の設定(設定ダイアログにあるチェックボックスに対応)
lockPref("browser.tabs.remote.autostart", true);
// アクセシビリティ機能によるe10s無効化を抑止
// https://bugzilla.mozilla.org/show_bug.cgi?id=1198459
lockPref("browser.tabs.remote.force-enable", true);
// アドオンがあることによるe10s無効化を抑止
// https://bugzilla.mozilla.org/show_bug.cgi?id=1232274
lockPref("extensions.e10sBlocksEnabling", false);
lockPref("extensions.e10sBlockedByAddons", false);
これで心置きなくe10s状態でのデバッグができます。
シェルスクリプトでだいたい1時間の間隔であれをやる - Jan 03, 2016
前のエントリに引き続いて、またシェルスクリプトの話。
「1時間間隔で決まった処理を行う」という目的だと、普通に考えたらまあcrontabを使う場面ですよね。
だから素直にそうしときゃいいんだけど、シェルスクリプト製のTwitter用botで自発的な自動投稿をやらせるにあたってどういうわけか「きっかり同じ時間間隔じゃなくて、確率でちょっとだけ揺らぎを持たせたい。その方が人間くさいよね。」と思ってしまって、それをやるのに一苦労しました……という話です。これは。
目指す状態
そもそも「きっかり同じ時間間隔じゃなくて、ちょっとだけ揺らぎをもって定期実行したい」というのは、一体どういう状態のことを指しているのか。 これをはっきりさせないことには話が始まりません。
僕が思ってる事をアスキーアートで図にすると以下のようになります。
00:00 基準時刻
|
00:15
|
00:30
|
00:45
|  ̄\
01:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
01:15
|
01:30
|
01:45
|  ̄\
02:00 目標時刻 >だいたいこの範囲で必ず1回実行する
| _/
02:15
|
02:30
|
人間の行動で言うと、こんな感じ。
- 時計を持って「1時間に1回これをやるように」と言われて、時計を見てその時刻に近かったらそれをやる。
- ちょっと早くても「まぁもうやっちゃってもいいか」ということでやる。
- ちょっと遅くても「まぁこのくらいの遅れは大丈夫でしょ」ということでやる。
- 「やらない」という選択肢は無い。「やべっ時計見落としてた!」と気がついたらその時点で慌ててそれをやる。
ちょっとばかり時間にルーズな人の取るような行動、という事ですね。
これをもうちょっと厳密に、コンピュータにも分かりやすいであろう表現に直すと、以下のように言えるでしょうか。
- 目標時刻の前後N分の範囲の時間帯を、処理を実行する可能性がある時間帯とする。
- それより早かったり遅かったりしたら実行しない。
- 目標時刻に近ければ近いほど実行の確率は高く、遠ければ遠いほど実行の確率は低い。
- 目標時刻ちょうどで最大確率、目標時刻のN分前およびN分後の時点で最低確率とし、その間は確率が線形に変化するものとする。
- ただし、その範囲の時間帯が過ぎようとしている時にまだ1回も処理が実行されていなければ、時間帯の終わりで必ず実行する。
- 計算は分単位で行う。(cronjobでも1分未満の指定はできないので)
実行確率をパーセンテージで算出できれば、あとは前のエントリでやった「何パーセントの確率であれをやる」がそのまま使えます。
となると、問題は「どうやって実行の確率を計算するか」という話になります。
今の時刻が目標時刻から何分ずれているかを計算する
先の定義に基づいて「ある時点での実行確率」を計算しようと思った時に、時刻を時刻の形式のまま扱おうとするとややこしいというか自分にはお手上げなので、「その日の0時0分を起点として、そこから何分経過したか」を使って計算していこうと思います。
そのために、こんな関数を用意しました。
# "03:20"のような時刻を与えると、00:00からの経過分数を出力する
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
これに与える現在時刻は、コマンド置換とdateコマンドを使って$(date +%H:%M)とします。
例えば現在時刻が07:58なら、以下のような出力が得られます。
$ time_to_minutes $(date +%H:%M)
478
これを「処理を実行したい時間間隔(分)」で割った余りを得ると、現在時刻が目標時刻から何分ずれているかが分かります。 60分間隔ならこうです。
$ interval=60
$ lag=$(( 478 % $interval ))
$ echo $lag
58
58分ずれている……という結果ですが、これはどっちかというと「目標時刻からマイナス方向に2分ずれている」と扱いたいところです。 なので、実際のずれが実行間隔の半分よりも大きい場合は「マイナス方向にN分のずれ」と見なすようにします。
$ half_interval=$(( $interval / 2 ))
$ [ $lag -gt $half_interval ] && lag=$(( $interval - $lag ))
$ echo $lag
2
これで「目標時刻ピッタリから何分ずれているのか」が求まったので、次はいよいよ確率の計算です。
今の時刻での実行確率を計算する
目標時刻ピッタリで確率100%としてしまうとそこで必ず実行されてしまうので、目標時刻ちょうどでの最大の確率を90%、許容されるずれの最大時点での最低の確率を10%とすることにします。
全体の振れ幅は10%から90%までの「80」ですので、「目標時刻ちょうどで100%、目標時刻からのずれが許容範囲の最大になった時を0%」とした割合に80をかけた結果に10を足せば、確率は10%から90%までの範囲に収まることになります。 式にすると、こうです。
$ probability=$(( (($max_lag - $lag) / $max_lag) * 80 + 10 ))
$ echo $probability
10
……おや? どうも計算結果がおかしいですね。
実は算術展開の$((~))は整数のみの計算なので、計算の過程で小数が出てくると小数点以下切り捨ての計算になってしまうのです。
こうならないようにするには、小数が出てこないように注意して計算するか、小数があっても大丈夫な計算方法を使う必要があります。 例えば、先に100倍してパーセンテージを求めてから後で100で割るという方法を取るなら以下のようになります。
$ probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
$ echo $probability
58
小数として計算するのであれば、数値計算用のコマンドのbcを使います。
これは、標準入力で与えられた式の計算結果を出力するコマンドなのですが、scale=1;という指定で計算時の小数点以下の桁数を指定すると、小数部を考慮した計算結果を返してくれます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc)
$ echo $probability
58.0
ただし、if [ ... ]での条件分岐では今度は整数しか扱えないので、出力される計算結果の小数部は取り除いておく必要があります。
これはsedで行えます。
$ probability=$(echo "scale=1; (($max_lag - $lag) / $max_lag) * 80 + 10" | bc | sed -r -e 's/\.[0-9]+$//')
$ echo $probability
58
ということで、ここまでをまとめて「算出した実行確率を出力する関数」にしてみましょう。
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
# 最小の実行確率より小さい時=実行する可能性がある範囲の
# 時間帯の外の時は、確率0%とする
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
同じ時間帯では重複実行しない
単にこの確率に基づいて実行するかどうかを決めるだけだと、00:55から01:05までの範囲で「実行時刻が揺らぐ」のではなく「その範囲で、確率次第で何度も実行される」という結果になります。 そうしないためには、同じ時間帯の中での再実行を防ぐ必要があります。
そのためには、最後に処理を実行した時刻を保持しておいて、現在時刻が最終実行時刻から一定の範囲内にある時は問答無用で処理をスキップする、ということになります。 とりあえず、最終実行時刻(として、00:00からの経過時間)を保存するようにしてみます。
current_minutes=$(time_to_minutes $(date +%H:%M))
probability=$(calculate_probability $current_minutes)
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
ここで保存した値を次の実行の可否の判断時に使うのですが、「最後の実行からN分間は絶対に実行しない」という条件を加えても良ければ、以下のようにできます。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
現在時刻から最後の実行時刻を引いた結果の「最終実行時刻からの経過時間」を求めて、それが指定の範囲内であれば何もしないで終了するということです。
比較の演算子が-lt(<)ではなく-le(≦)である点に注意して下さい。
-ltで比較してしまうと、00:55に実行してから10分後の01:05ちょうどの時点で「10分未満の範囲で実行されていないので、再実行してよい」と判断されてしまいます。
ただ、これだけだと日付をまたいだ時に判定が期待通りに行われません。
最後の実行時刻が例えば前日23時ちょうどだったとすると、last_doneは23*60=1380ですが、現在時刻が00:04だったとすると4-1380=-1376になってしまって、負の数は「何分間は再実行しない」という指定=正の数よりも必ず小さいので、永遠に再実行されないことになってしまいます。
なので、現在時刻から最終実行時刻を引いた結果が負の場合は、「最終実行時から0時までの経過時間」と「0時から現在までに経過した時間」の和を「最終実行時刻からの経過時間」として使う必要があります。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
...
その時間帯で投稿が無い時は時間帯の最後のタイミングで必ず実行する
ここまで来たらあともう一息。 最後は「その時間帯で必ず1回は実行する」という要件です。
とはいえ、これはそんなに難しく考えなくても大丈夫。 前項の段階で「指定の範囲内の時間での再実行はしない」という判定が既に行われているので、その判定の後であれば、「実行するべき時間帯の最後の瞬間で、その時間帯の中ですでに実行済みである」という場面はあり得ない事になります。 なので、単純に「今この瞬間は、実行しても良い時間帯の範囲の最後の瞬間かどうか?」を判断して、そうであれば確率100%で実行するということにすればいいです。
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
# 目標時刻からのずれを計算
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
# ずれが、許容されるずれの最大値と等しければ、今がまさに
# その時間帯の最後の瞬間である。
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
...
まとめ
ここまでのコード片を全てまとめた物が、以下になります。
time_to_minutes() {
local now="$1"
local hours=$(echo "$now" | sed -r 's/^0?([0-9]+):.*$/\1/')
local minutes=$(echo "$now" | sed -r 's/^[^:]*:0?([0-9]+)$/\1/')
echo $(( $hours * 60 + $minutes ))
}
interval=60
half_interval=$(( $interval / 2 ))
max_lag=5
calculate_probability() {
local target_minutes=$1
local lag=$(($target_minutes % $interval))
[ $lag -gt $half_interval ] && lag=$(($interval - $lag))
local probability=$(( (($max_lag - $lag) * 100 / $max_lag) * 80 / 100 + 10 ))
if [ $probability -lt 10 ]
then
echo 0
else
echo $probability
fi
}
current_minutes=$(time_to_minutes $(date +%H:%M))
forbidden_minutes=10
last_done=$(cat /path/to/last_done)
if [ "$last_done" != '' ]
then
delta=$(($current_minutes - $last_done))
if [ $delta -lt 0 ]
then
one_day_in_minutes=$(( 24 * 60 ))
delta=$(( $one_day_in_minutes - $last_done + $current_minutes ))
fi
[ $delta -le $forbidden_minutes ] && exit 0
fi
lag=$(($current_minutes % $interval))
if [ $lag -eq $max_lag ]
then
probability=100
else
probability=$(calculate_probability $current_minutes)
fi
if [ $(($RANDOM % 100)) -lt $probability ]
then
# ここで定時処理を実行
echo $current > /path/to/last_done
fi
人間くさい振る舞いをする何かを作る時の参考にしてみて下さい。
追記:もっと単純なやり方
Qiitaのクロスポストの方に頂いたコメントで、以下のようにcronjobを設定すれば良いのでは?とのご指摘がありました。
55 * * * * sleep $(( $RANDOM \% 10 ))m; (実行したい処理)
実行の可能性がある時間帯の最初の瞬間にsleepを呼び、何秒間待つかは0~10分の間でランダムに決定する。その後、やりたい処理を実行する。という方法です。
「指定の時間間隔ちょうどの実行確率を最も高くしたい」「その時間帯の最初の瞬間から最後の瞬間までの間に運用を開始した時も、すぐに動作させたい」といったいくつかの要件を除外すれば、この方法が最もシンプルですね。 というか最初この指摘を見た時には「完全に置き換え可能じゃん!」とすら思ってしまいました。 (よくよく見返して、要件のいくつかがカバーされていない事にようやく気づくレベル)
無駄に複雑な要件を全て満たそうとすると手間がかかるけれども、要件の8割9割ほどを満たせれば良いという割り切りができれば手間を大きく減らせる場合がある、「そもそも本当にその要件は必要なの?」というレベルからの再考次第で実現手法を大きく簡素化できるという、いい例だと思いました。 そのあたりの絞り込みが足りないままこの記事を世に出してしまって、お恥ずかしい限りです……。
シェルスクリプトでランダムにあれをやる - Dec 30, 2015
「何分の一で」とかの情報は出てくるんだけど、知りたかったことそのものズバリの「何パーセントの確率でアレをやる」という例がなかなか見つからなかったので、まとめてみました。
シェルスクリプトで乱数
まず根底にある「ランダムに」っていう所だけど、これはBashかそうでないかでやり方が変わる。
Bashでは$RANDOMを参照すると0から32767の範囲でランダムな結果が得られる。
$ echo $RANDOM
15999
Bash以外では、/dev/urandomとodコマンドを組み合わせて似たような事ができるようだ。
$ od -vAn --width=4 -tu4 -N4 </dev/urandom
1939740834
0~N-1の範囲で乱数を得る
以下、説明を簡単にするために$RANDOMの方でコードを書くけど、違うシェルでは適宜読み替えて下さいという事で。
あと、ここからは数値計算が出てくるので、中に書いた式を計算した結果を得る$((計算式))の書き方(算術展開)を使っていく。
気を取り直して、0~N-1の範囲でランダムに1つを選ぶ方法。
これは割り算の余りを使う。
乱数をNで割った余りを求めれば、0~N-1のいずれかの数字が得られる。
例えば$(($RANDOM % 10))とすれば、0~9のいずれかの数字が得られる(つまり、10パターンに分岐できる)。
$ echo $(($RANDOM % 10))
0
$ echo $(($RANDOM % 10))
5
$ echo $(($RANDOM % 10))
3
1/Nの確率で何かやる
先の結果がどれか1つの選択肢に等しくなった時だけ処理を実行すれば、「約1/Nの確率で実行」ということになる。
[ $(($RANDOM % 3)) -eq 0 ]なら、約1/3の確率で真になり&&以下が実行される。
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
Hit!
$ [ $(($RANDOM % 3)) -eq 0 ] && echo 'Run!'
ここまではすぐ例文が出てくるんだけど、ここから先が出てこなかったので自分で考える必要があった。
N%の確率で何かやる
実際に「ランダムに何かをやりたい」時というのは、多分、だいたいは「パーセンテージとか割合で頻度を指定したい」って場面だと思う。 「60%の確率で分岐したい」みたいな。
これは、「1/Nの確率で」の例を発展させるとできる。
1/100までの精度だったら、まず0~99のいずれか1つをランダムに得る。
次に、これを-lt演算子(less thanだから、左辺が右辺より小さい<の意味)で「何パーセントでやりたい」という数字と比較する。
結果が真の時だけ処理を実行すれば、つまり「何パーセントの確率で実行」ということになる。
絵を描くのが面倒なのでアスキーアートでやると、
0--------------------99
こういう数直線があって
0-----+-------------99
↑30
この位置に線を引いて、0から99までのどれか1つをランダムに選んだ結果が線より左にある時だけ実行するということです。
↓この時だけ実行 ↓こっちだったら実行しない
○ ○ × × ×
0-----+-------------99
↑30
これを踏まえて、30%の確率でRun!という文字列を出すコマンド列なら、以下のようになる。
$ if [ $(($RANDOM % 100)) -lt 30 ]; then echo 'Run!'; fi
30の所を変えれば任意のパーセンテージにできる。
関数にするならこんな感じか。
run_with_probability() {
local probability=$1
if [ $(($RANDOM % 100)) -lt $probability ]
then
echo 'Run!'
fi
}
ほんとに狙ったとおりの結果を得られているか、同じ物を1000回くらい繰り返し実行して確かめてみる。
与えた数の連番を出力するseqコマンドとforループを組み合わせて、先の関数を1000回実行し、Run!が出力される頻度を見てみる。
(forループの出力結果をパイプラインでwc -lに渡して行数を数えれば、実際に出力された回数が分かる。)
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
303
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
292
$ for i in $(seq 1000); do run_with_probability 30; done | wc -l
316
1000回中の300回前後なので、まあだいたい30%になっている。 ばらつきがあるけど、試行回数を増やせば指定のパーセンテージに収束していくはず。
実際は「一定の確率で文字列を出力する」というのを汎用的にやりたかったので、こういう風にした。
probability() {
[ $(($RANDOM % 100)) -lt $1 ] && cat
}
# 95%の確率で出力→だいたいは出力される
output_message | probability 95
# 10%の確率で出力→滅多に出ない
output_message | probability 10
入力された複数行の中からランダムに1行抜き出す
ちょっと毛色が違うけど、これもついでに。
入力に対してその中からランダムに1つをピックアップするという場面では、これはQiitaにクロスポストした方の記事のコメントで指摘を頂いて知ったんだけど、そのものずばりのshufというコマンドがある。これは標準入力で受け取った内容を行ごとにシャッフルして出力するコマンドで、-nで取り出す行数を指定できるので、以下のようにすれば「ランダムに1行取り出す」という結果になる。
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | shuf -n 1
shufコマンドの存在を知らなかった時にそれを使わずに解いてみた時には、先の「0~N-1のいずれかを得る」の応用で以下のようにしてた。
choose_random_one() {
// 標準入力を一旦変数に保持
local input="$(cat)"
// 入力の行数を得る
local n_lines="$(echo "$input" | wc -l)"
// 「1~最終行の行番号」の範囲でどれか1つを得る
local index=$(( ($RANDOM % $n_lines) + 1 ))
// 得た行番号を使って、sedで「指定された番号の行だけを取り出す」操作を行う
echo "$input" | sed -n "${index}p"
}
# 他のコマンドから渡された結果の中からランダムに1行を出力してみる
read_messages | choose_random_one
入力を「行数を数える時」と「実際に抽出する時」の2回使わないといけないので、一旦全部catで読み取って変数に保持してるというのがポイントでしょうか。
まとめ
ということで、「シェルスクリプトでランダムにアレをやる」色々でした。
なんでこんな事やってるかというと、シス管系女子の宣伝を自動化したくて、宣伝用アカウントの運用をボットにやらせたかったのですが、「コマンド&シェルスクリプト」の連載なんだからボットもシェルスクリプトの方がネタになるよね&自分で作れば「お、作者はちゃんと技術分かってる人なんだな」と技術的な信頼に繋がるかな?と思って、TwitterクライアントとボットをBashでゴリゴリ書いているからなのでした。 ……って、単に宣伝を投稿するだけならTwitterクライアントができた時点でcronjobでやってしまえばよかったはずなのに、「何パーセントの確率で会話を継続する」とかそんな領域に足を踏み入れてるのは明らかにおかしいですね。ほんとに「どうしてこうなった」だ。
BtoBの仕事だったり実用のアドオンだったりでしかコード書いてないと、一定の確率で何かやるという事が必要になる場面が全く無くて(確実に何かやる、という事ばっかりだから……)、ぱっとやり方を思いつけなくて参りました。 という情けないお話。