Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

タブバーをドラッグしたらウィンドウが動くとかその辺のタイトルバーっぽい挙動を無効化する - Sep 15, 2010
ツリー型タブではタブバーをウィンドウの横に置く使い方を基本的には想定してるワケだけれども、普通にタブバーを縦型にするだけだと、Minefieldではタブバーをダブルクリックしたらウィンドウが最大化されるという謎の結果になってしまうことがある。
MinefieldではBug 555081で行われた変更により、ツールバーの空白の部分がウィンドウのタイトルバーと同じ扱いになるようになっている。ツールバーの空白部分をドラッグすればウィンドウが動くし、ダブルクリックすればウィンドウの最大化になる(Windowsの場合)し、ぴたすちおのようにタイトルバーを右クリックしたらウィンドウシェードするようなユーティリティを使っていれば、それも動く。
ただ、ウィンドウの横に移動されたタブバーのようにぱっと見ツールバーに見えない部分までもがこのような挙動になってしまうと、違和感があるし混乱の元ではある。また、ツリー型タブの場合はタブバーの空白の領域をドラッグするとタブバーの位置を変えられるという機能があるけれども、上記の通りの仕様なのでこのままではタブバーの位置を変えられないということにもなってしまう。こういう時、どうすればいいのか。
タイトルバーのように振る舞うツールバーの挙動は、chrome://global/content/bindings/toolbar.xml#toolbar-drag で定義されている。コードを見てみると、WindowDraggingUtils.jsmというモジュールを読み込んで自分自身をWindowDraggingElementという物に登録しており、こうして登録された要素がタイトルバーのように振る舞うようだ。じゃあこの初期化処理を無効化するか初期化処理で行われた結果を取り消してやればいいんじゃないか、と思ったけど、設計的にそれは無理だった。
仕方がないのでWindowDraggingUtils.jsmの方を見てみると、「タイトルバー上にあるボタン等をドラッグした時だけは上記のような動作にしないようにする」というのをどうやって実現しているのかが分かった。
- Windowsでは、マウスのボタンが押下された時にMozMouseHittestというイベントが発行されている。
- 任意で登録された関数(
mouseDownCheck)がfalseを返した時か、クリックされた要素からその祖先までの間にドラッグ操作を受け付けそうな要素がある時は、preventDefault()している。 preventDefault()された場合、マウスのボタンがそもそも押下されなかったという扱いになるみたい。
端的に言うと、MozMouseHittestイベントをpreventDefault()すれば、ツールバーのタイトルバー的な振る舞いを無効化することができるということのようだ。
gBrowser.tabContainer.addEventListener(
'MozMouseHittest',
function(aEvent) {
aEvent.preventDefault();
},
true
);ただ、タブバー内で発生するMozMouseHittestイベントを常にpreventDefault()してしまうと、タブをクリックしてもタブが切り替わらないということになってしまう。preventDefault()するのは祖先要素にタブまたはクリック可能な要素が無い場合だけに制限しないといけない。
Minefield 4.0b6preでXUL要素とiframeの重ね合わせが鼻血出るくらい簡単になってた - Sep 11, 2010
ツリー型タブには「ポインタがタブバーを離れている時はタブバーを隠してor縮めて、ポインタがタブバーに近づいたら(フルサイズで)表示する」という機能がある。

Firefox 4に向けて開発が進んでいるMinefield 4.0b6preでこの機能が動かなくなっていたので修正をしよう……と思ったら根本的に作りなおさなきゃいけなかった。でも以前のやり方に比べたらずっとスッキリと実装できるようになっていた。
これはそんなお話。
これまで
Firefox 3.6までは、上記の機能を実現するのにえらく苦労していた。
tabbrowser要素の仕様変更のまとめで過去に図解したけど、今までのFirefoxではタブバーとコンテンツ表示領域が1つのボックスの中に収まっていたので、ボックスの縦横の配置を変えるだけでタブバーを「縦置き」できていた。そうして「縦置き」したタブバーの幅を自動的に増やしたり減らしたりしてやりさえすれば、最も単純な「タブバーを自動で隠す」機能は実現できる。
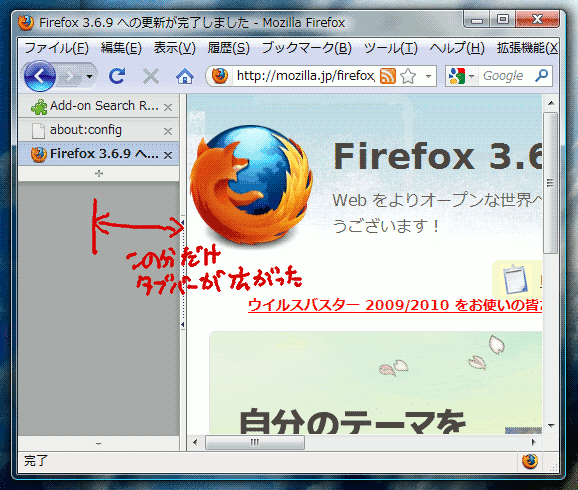
ただ、実際にはそれだと実際使っててストレスを感じる。タブバーの幅が変化する度にタブバーによって押し潰される形でコンテンツ領域の幅が縮んでしまい見た目に激しくガタつくのと、それに加えて再描画のためにFirefoxが一瞬でも無反応になってしまう事がある、というのが多分その理由だろう。
じゃあタブバーの幅が増えた分をコンテンツ領域の上にかぶせてやればガタつきがなくなってイイよね、ということで上のスクリーンショットのような事をやろうとして、当時の僕はFirefoxの仕様に頭を抱える羽目になってしまった。
ネガティブマージンでは駄目だった
要素同士を重ねる、というと一番手っ取り早いのはネガティブマージンを使う方法だろう。タブバーにネガティブマージンを指定してやれば万事解決する……そう考えていた時期が僕にもありました。
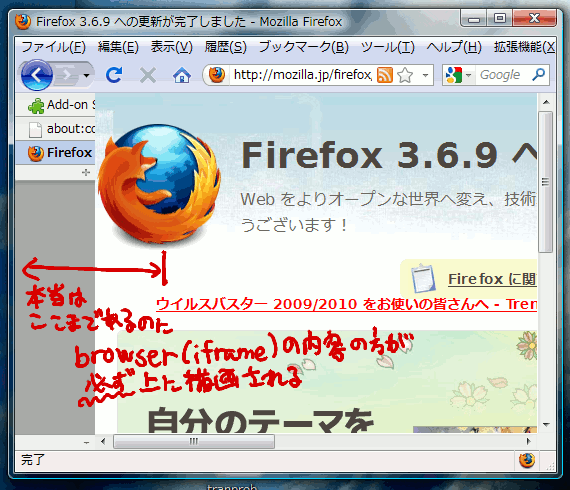 見るも無残。
見るも無残。
どうも現行バージョンのGeckoはインラインフレームだけ特別な描画の仕方をしているらしく、iframeやbrowserの内容はオーバーレイのウィンドウのように他の内容より前に表示されるみたいだ。browser要素がDOMツリーに尽かされた後でDOMツリーに追加されたtab要素なら、browser要素よりも手前に描画されることもあるようだけど、基本的にはこうなると思っておいた方がいい。
ネガティブマージンで駄目ならposition:absoluteやらposition:fixedやらはどうなんだ、という代替案は当然出てくるだろうけど、これもやっぱり駄目だった。browserをz-index:1に、タブの方をz-index:2にという風にやっても、どう頑張ってもタブがbrowserの下に隠れてしまった。
panelは?
panelやmenupopupを使うと、OSのレベルで別のウィンドウを開いて任意の位置に重ねることができる。影や枠を表示しないようにすることもできるから、うまくやればこれが一番確実かもしれない。
ただ、自分で0から作る場合ならともかく、Firefoxのタブを後から改変するという場合には、これは激しくお勧めできない。Firefoxのタブ周りのDOMツリーを不用意にいじると、Firefoxの本来の構造を期待して開発されたアドオンが動かなくなってしまう可能性が高いからだ。
結局どうやったのか
アレも駄目これも駄目という感じだったので、Firefox 3.6以前では結局、他のアドオンに対して与える影響が一番少なそうなやり方として、いくつかのテクニックの組み合わせでそれっぽく見せるようにしてみた。
まずタブバーの幅を普通に増やす。
それだけだとコンテンツ領域が押し潰されてしまうので、そうならないようにネガティブマージンでappcontentあたりの幅を広げてレイアウトを維持する。

次にnsIContentViewerのmoveメソッドで描画内容をずらす。このメソッドは、フレームの内容の描画位置を任意の座標分平行移動する物だ。

仕上げとして、nsIContentViewerのmoveメソッドで描画位置を変えたせいでレンダリングされていない「タブバーと重なり合う部分」を、canvasのdrawWindowで描画する。
 スクロールしてる場合やフルズームが使われている場合に位置をうまく合わせるのが難しいけど、なんとか頑張った。
スクロールしてる場合やフルズームが使われている場合に位置をうまく合わせるのが難しいけど、なんとか頑張った。
Minefield 4.0の古いベータへの対応
ちょっと前までのMinefieldでも、基本的にはこれと同じ事をやってた。 tabbrowser要素の仕様変更のまとめで説明している通り、タブバーそのものはposition:fixedで固定して位置を合わせていて、かつてタブバーがあった所に挿入したダミーの要素と実際のタブバーとの表示サイズを同期させているという点が異なるけど、browser(iframe)とタブが重ならないように工夫を凝らしているという点では変わりはなかった。
これから
そんな感じで今までやってたんだけど、Minefield 4.0b6preをアップデートして試しに機能をONにしてみたら、上記の解決策の重要な要素の1つである「nsIContentViewerのmoveメソッドで描画内容をずらす」が効かなくなってた。
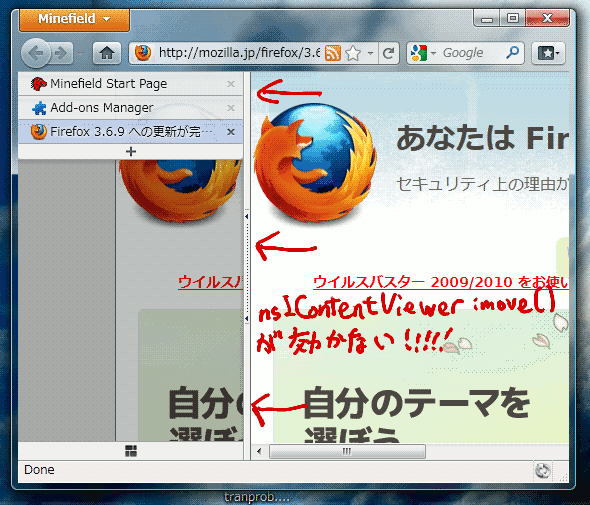
これではタブバーの幅が変わる度にコンテンツ領域がガタついてしまうという問題を回避できない。
もはやこれまでか。そう思った僕を救ったのは、別の(ツリー型タブ)の不具合によって起こっていた現象でした。
先述の通り、Minefield用には既にタブバーをposition:fixedでレイアウトするという変更を反映してた。それが原因で、TabsToolbarの中に配置されたツールバーボタンが、タブバーが自動的に隠された状態であっても表示されたままになってしまうという現象が同時に発生していた。
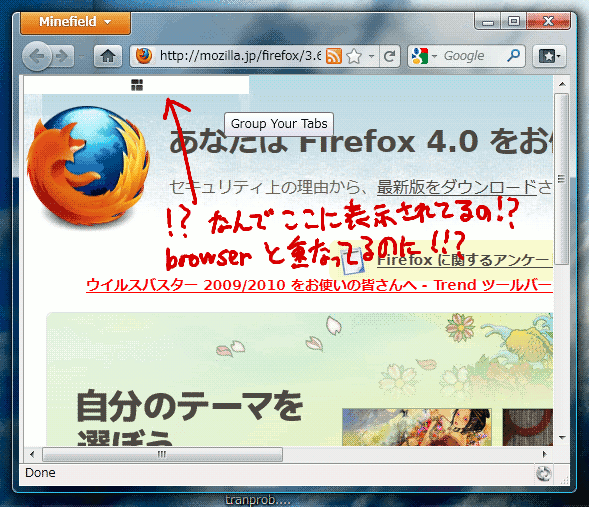
……ん? ちょっと待てよ! なんでその位置にそのボタンが見えてるわけ?! browserの下に隠れてない!?
検証してみたところ、いつ行われた変更によるものなのかは分からないけど、Minefieldではいつの間にか、前述した「browserやiframeの内容は常に最前面に描画されてしまう。それらと重なる位置に置かれたXUL要素はbrowserやiframeの下に隠れてしまう。」という問題が起こらなくなっているようだ。
そこまで分かれば話は早い。もう前述のような凝ったことをしなくても、普通にposition:fixedで配置してbackground:rgba(0, 0, 0, 0.25)にすればもうそれだけで、「半透明のタブバーの下にコンテンツ領域が透けて見える」状態になるということだ。
 こうしてひとまず現状のMinefieldには対応することができた。
こうしてひとまず現状のMinefieldには対応することができた。
まとめ
- Minefieldでは、position:fixed等で任意のXUL要素をコンテンツ領域の上に重ねて配置できるようになった。ポジショニングを気軽に使えるようになった。
- 今まで必要だった、制限の回避のための工夫は、もういらない(多分)。
いい時代になったものですね。
可変フレームなアニメーションを管理するためのライブラリをmozRequestAnimationFrame/MozBeforePaintに対応させた - Sep 01, 2010
JavaScriptでアニメーション(モーショントゥイーンなど)をやろうと思うと、setTimeout()とかsetInterval()とかのタイマーを使うことになる。でもタイマーを複数個同時に走らせるのはリソース的に無駄だしオーバーヘッドが大きいせいでアニメーション効果ががたついてしまうようになったりするので、複数のアニメーションを同時に進行させるなら、1つのタイマーで複数のアニメーションを同時に処理した方がいい。
というわけで、そのためのライブラリをだいぶ前に作った。これは実際にツリー型タブ等で使ってる。以下のようにすると、タイマーの開始とか停止とかをヨロシクやってくれる。
var animationManager = window['piro.sakura.ne.jp'].animationManager;
// JavaScriptコードモジュールとして読み込むなら
// Components.utils.import('resource://myaddon-module/animationManager.js');
// で animationManager がエクスポートされる
var tab = gBrowser.selectedTab;
var task = function(aTime, aBeginningValue, aTotalChange, aDuration) {
// aTime:アニメーション開始時点からの経過時間(ミリ秒)
tab.style.marginLeft = (aBeginningValue + (aTime / aDuration * aTotalChange))+'px';
return aTime > aDuration; // trueを返すとその時点でアニメーション終了
};
animationManager.addTask(
task, // アニメーションの処理そのものとなる関数
parseInt(getComputedStyle(tab, null).marginLeft), // aBeginningValue:初期値
50, // aTotalChange:変化量
250 // aDuration:アニメーションにかける時間(ミリ秒)
);この例だとmargin-leftが今の値から50増加するアニメーションだけど、変化量の指定をマイナスにすればそれだけで、今の値からmargin-leftが50減るアニメーションになる。(ちなみに、アニメーションの処理となる関数が受け取る引数の形式がなんでこうなってるのかについては、「高速な環境ではたくさん描画していいけど、低速な環境だと再描画を減らしてほしい。とにかく、1回のアニメーションは決まった時間の中できちんと終わらせたい。」という可変フレームなアニメーションをやりやすくするためです。)
既に動いてるアニメーションを中止する時は、登録した関数をremoveTask()に渡す。
animationManager.removeTask(task);
// すべてのアニメーションを中止するなら
// animationManager.removeAllTasks();中止ではなくてアニメーションを一時停止→再開させたい場合は、こう。
animationManager.stop(); //停止
// ...何かの処理...
animationManager.start(); // 再開という感じのライブラリなんだけど、これを最近mozilla-centralに入った新しいアニメーションのためのAPIに対応させてみた。APIとしての変更は、addTask()の最後の引数にDOMWindowを受け取るようになったという点のみ。
animationManager.addTask(
task,
parseInt(getComputedStyle(tab, null).marginLeft),
50,
250,
window // アニメーションを行うウィンドウ
);リンク先で紹介されているmozRequestAnimationFrame/MozBeforePaintが利用できる環境ではそれを使用して、そうじゃない時は今まで通りsetInterval()で処理する。ライブラリを使う側のコードは、Firefoxのバージョンの違いを意識する必要は全く無い。ただ、APIを生で使う時に比べるとオーバーヘッドがあるから、新APIのメリットぶちこわしかもしんない。
リンク先のエントリを見た感じでは、理屈としては一般的な可変フレームレートのアニメーションの考え方に基づいているみたいなんだけど、DOMのイベントをトリガーにしないといけなかったり次のフレームを描画するためにいちいちメソッドを呼ばないといけなかったりというのは煩わしいと思ったので、せっかくだからライブラリ側で面倒を見るようにしてみた。
nsIWindowWatcher::openWindow()で複数の引数をウィンドウに渡すには? - Sep 01, 2010
nsIWindowWatcherのopenWindow()って何ですか
アドオンで新しいChromeウィンドウ(特権付きのウィンドウ、XPCOMとか自由に使えるやつ。ブラウザウィンドウ等、Firefoxのアプリケーションとしてのウィンドウはだいたいそう。)を開く方法はいくつかある。
window.openDialog()を使う- nsIWindowWatcherの
openWindow()を使う
普通にXULドキュメントの中で読み込まれてるスクリプトからやるのなら、1の方法でいい。
でも、JavaScriptコードモジュールやXPCOMコンポーネントのスクリプトのように、グローバルオブジェクトがDOMWindowじゃない場面ではこの方法が使えない。特にFirefoxが起動した直後でまだブラウザウィンドウすら開かれていないという場面では、nsIWindowMediatorのgetMostRecentWindow()でDOMWindowを取得してそのメソッドを呼ぶ、というようなこともできない。なのでこういう時は2の方法を使わないといけない。
やりたかったこと
window.openDialog()の引数は window.open()と同じだ。
- 開くウィンドウのChrome URL(文字列)
- ウィンドウ名(大抵は
'_blank'決めうち) - ウィンドウの挙動の指定(
'chrome,all,dialog=no'とか'chrome,all,modal'とかそういうの)
window.openDialog()の場合はこの後に続いてさらに引数を指定することができて、第4引数以降に渡した物がそのまま、開かれたウィンドウの中でwindow.argumentsとして参照できるようになっている。例えば
var w = window.openDialog(url, '_blank', 'chrome,all',
arg0, arg1, arg2);こう指定して開かれたウィンドウでは
window.arguments[0] // => arg0の値
window.arguments[1] // => arg1の値
window.arguments[2] // => arg2の値となる。Firefoxのブラウザウィンドウは、コマンドライン引数で渡されたURI等をこうやって受け取っている。
これと同じことをnsIWindowWatcherのopenWindow()でやろうとして、うまくいかなかった。
openWindow()の引数は
- 親ウィンドウ(DOMWindow)
- 開くウィンドウのChrome URL(文字列)
- ウィンドウ名(大抵は
'_blank'決めうち) - ウィンドウの挙動の指定
- ウィンドウに渡す引数
となっていて、最初の引数が加わったことを除けば2~4はwindow.openDialog()の第1~第3引数と同じ。問題は、開かれるウィンドウに引数を渡す方法が違うということ。window.openDialog()と同じ感覚で引数を渡しても、期待通りに受け渡されない。
var WW = Cc['@mozilla.org/embedcomp/window-watcher;1']
.getService(Ci.nsIWindowWatcher);
// これはダメ
WW.openWindow(null, url, '_blank', 'chrome,all',
arg1, arg2, arg3);
// これもダメ
WW.openWindow(null, url, '_blank', 'chrome,all',
[arg1, arg2, arg3]);
// これは場合によってはOK
WW.openWindow(null, url, '_blank', 'chrome,all',
arg1);Function.prototype.call()では引数を普通に並べてFunction.prototype.apply()では配列で渡す、という様式を真似てJavaScriptの配列を渡してみても、WindowWatcherは「なんですかコレ」って感じでこっちの意図を読み取ってはくれない。開かれたウィンドウの方でwindow.argumentsを見てみても、長さ1の配列になってて、その要素はなんだかよく分からないnsISupportsのオブジェクトになってる。
引数を1つだけ渡す場合だとうまくいくことがあるというのは、このメソッドの第5引数の型がnsISupportsだからだ。nsISupportsをを実装してるオブジェクトならWindowWatcherはちゃんと受け取ってくれて、開かれた側のウィンドウでもwindow.arguments[0].QueryInterface()して使うことができる。
でもやりたいことはあくまで、複数の引数をウィンドウに渡して、開かれたウィンドウの側でwindow.argumentsで配列の要素としてそれぞれを受け取ることなのですよ。というか、開かれる側のウィンドウがそういう実装になっているため、どうしてもその様式で引数を渡さないといかんのです。
nsISupportsArrayとnsISupportsなんちゃらで……
XPCOMの世界で配列を扱わないといけない場面でたまーにnsISupportsArrayというのが出てくる。これは名前の通り配列のような性質を持つインターフェースで、openWindow()の第5引数はこのインターフェースを実装してるオブジェクトも受け付けるという風にIDL定義には書いてある。
似たような感じでプリミティブ値に対応するようなXPCOMのインターフェースがいくつかあって、nsISupportsStringとかnsISupportsPRBoolとかnsISupportsPRUInt64とかそういうのがいっぱいある。これらのインスタンスをnsISupportsArrayに格納してopenWindow()に渡してやれば、どうやら、開かれた方のウィンドウでは対応するJavaScriptのプリミティブ値としてそれらを受け取れるらしい。
が、こんな事真面目にやってらんないですよね。値の型に合わせてインターフェースを使い分けてインスタンスを作って……とか、めんどくさすぎる。
幸い、XPCOMにはnsIVariantという便利な物があって、これのsetFromVariant()にJavaScriptの値を適当に渡してやると、あとはnsIVariant君がよろしくやってくれるのです。これを使わない手はない。
var JSArray = ['string', true, 29];
var array = Cc['@mozilla.org/supports-array;1']
.createInstance(Ci.nsISupportsArray);
JSArray.forEach(function(aItem) {
var variant = Cc['@mozilla.org/variant;1']
.createInstance(Ci.nsIVariant)
.QueryInterface(Ci.nsIWritableVariant);
variant.setFromVariant(aItem);
array.AppendElement(variant);
});
WW.openWindow(null, url, '_blank', 'chrome,all', array);これでめでたく、複数の引数をWindowWatcherからも渡せるようになりました、と。
でもハッシュは渡せなかった
これで一件落着と思ってたんだけど、この方法が使えない場合があることが分かった。nsIVariantはプリミティブ値でもXPCOMのオブジェクトでも何でも受け渡せる万能なヤツなんだけど、nsISupportsArrayと組み合わせてWindowWatcherに渡す時は、XPCOMのインターフェースを持ってないJavaScriptのネイティブのオブジェクトはこの方法では渡せなかった。
var variant = Cc['@mozilla.org/variant;1']
.createInstance(Ci.nsIVariant)
.QueryInterface(Ci.nsIWritableVariant);
variant.setFromVariant({ prop : value });こうやって値を設定した物をnsISupportsArrayに渡しても、開かれたウィンドウの方ではよく分からんnsISupportsのオブジェクトになってしまって、元のオブジェクトが持ってた情報を取り出せなかった。
回避方法として思いつくのは
JSON.stringify()して渡して、受け取り側でJSON.parse()する- nsIPropertyBagにする
くらい。JSONにできない物は2の方法でやるしかないと思う。
var bag = Cc['@mozilla.org/hash-property-bag;1']
.createInstance(Ci.nsIWritablePropertyBag);
for (var i in hash)
{
if (hash.hasOwnProperty(i))
bag.setProperty(i, hash[i]);
}で渡して、受け取った側で
var hash = {};
var enum = window.arguments[0]
.QueryInterface(Ci.nsIPropertyBag)
.enumerator;
while (enum.hasMoreElements())
{
let item = enum.getNext()
.QueryInterface(Ci.nsIProperty);
hash[item.name] = item.value;
}という風にしてハッシュに戻す。とか。
まとめ
ウィンドウ間の情報の引き渡しはマジ鬼門。
あと、上に書いた諸々の処理をライブラリとしてまとめておいたので、同じような事をしようとしてる人は使うといいよ。
JsDoc ToolkitでJavaScriptコードモジュールのDoc Commentを出力する - Aug 20, 2010
Doc Commentの必要性
最近、JsDoc Toolkitの導入を考えてる。
- ライブラリとして抜き出したコードを公開しておきたいけど、ライブラリ自体の使い方を書いたページを準備するのが面倒だし、多分誰も見てくれなさそう。
- ソースコードの中にコメントとして使い方を埋め込んでおくと、見るべきファイルが1つで済むから良さそうだけど、どんな書式で書くと分かってもらいやすいかが問題だ。
ツリー型タブのAPI紹介等ではXPIDLっぽい書き方にしてみてるけど、オレオレ表記なので分かってもらえない可能性があるという心配はずっとしている。
ところで、Firefox自体のソースを見ていると以下のような書き方をしているのをよく見かける。
(略)
/**
* Given a starting docshell and a URI to look up, find the docshell the URI
* is loaded in.
* @param aDocument
* A document to find instead of using just a URI - this is more specific.
* @param aDocShell
* The doc shell to start at
* @param aSoughtURI
* The URI that we're looking for
* @returns The doc shell that the sought URI is loaded in. Can be in
* subframes.
*/
function findChildShell(aDocument, aDocShell, aSoughtURI) {
(略)これはJavaで標準的に使われているJavadocという「ソースコードの中に埋め込まれたコメントを自動的に収集してHTML形式でドキュメントを生成する」仕組みに基づいたもので、同じ形式でコメントを埋め込めるよう、Javadocの仕様に準拠した実装が言語ごとに存在しているようだ。JavaScriptならJsDoc Toolkit、C言語ならGTK-Docが一般的らしい。あとJavaScriptに関してはGoogle Closure ToolsのClosure Compilerも対応しているらしい
事実上の標準としてみんなが見慣れた形式なのであるならば、これに合わせて書くのがいいだろう。と思ったので、とりあえずライブラリとして切り出して公開しているコードにJavadoc形式で使い方の解説を埋め込んでみることにした。
JsDoc Toolkitの使い方
- Javaをインストールする。
- JsDoc Toolkitをダウンロードして展開しておく。
- JsDoc-Toolkitを使うで配布されているバッチファイル「jsdoc.bat」を、JsDoc Toolkitのjsrun.jarとかと同じ位置に置く。
- JavaScriptのファイルの中にDoc Commentを書く。書き方はJsDoc Toolkitによる開発効率向上を目指して - @IT等を見ると例がある。
- jsdoc.batの起動オプションにJavaScriptのファイルを渡して起動する。
- jsdoc.batと同じ位置にjsdocという名前のフォルダができて、その中に生成されたHTMLファイルがあるので、index.htmlをブラウザで開いて眺めてニヨニヨする。
JavaScriptコードモジュールとJsDoc Toolkit
- JavaScriptコードモジュールではファイルの拡張子として「.jsm」を使うことが多いみたいなんだけど、.jsmなファイルにDoc Commentを埋め込んでJsDoc Toolkitに渡してみてもドキュメントを出力してくれなかった。
- UxU用のテストケースまで走査するため、フォルダごと渡してまとめてドキュメントを生成させてみると、ファイル一覧の中にテストケースのファイルまで出てきてしまう。
@exampleに例を書く時に、例の中に<とか>とかのHTML的にまずい文字が含まれていると、出力されるHTMLがぶっ壊れてしまう。
JsDoc Toolkit自体のソースを見てみた所(JsDoc Toolkitはそれ自体がJavaScriptで書かれている。Java上で動作するJavaScript実行環境のRhinoの上で動作している。)、ファイルの拡張子でフィルタリングを行っているらしいということが分かった。あと、テンプレートのファイルの方を編集すれば、例に埋め込んだコードのせいでHTMLがぶっ壊れてしまう問題は回避できるようだった。
そういうわけで当面の所はこんな変更を加えて使ってみることにした。以下はjsdoc_toolkit-2.3.2.zipに対する差分です。
diff -ur jsdoc-toolkit-orig/app/lib/JSDOC/JsDoc.js jsdoc-toolkit/app/lib/JSDOC/JsDoc.js
--- jsdoc-toolkit-orig/app/lib/JSDOC/JsDoc.js 2009-01-24 18:42:04.000000000 +0900
+++ jsdoc-toolkit/app/lib/JSDOC/JsDoc.js 2010-08-20 10:17:17.602464000 +0900
@@ -69,7 +69,8 @@
JSDOC.JsDoc._getSrcFiles = function() {
JSDOC.JsDoc.srcFiles = [];
- var ext = ["js"];
+ var ext = ["js", "jsm"];
+ var ignorePattern = /\.test\.js$/i;
if (JSDOC.opt.x) {
ext = JSDOC.opt.x.split(",").map(function($) {return $.toLowerCase()});
}
@@ -89,7 +90,7 @@
}
}
- return (ext.indexOf(thisExt) > -1); // we're only interested in files with certain extensions
+ return (ext.indexOf(thisExt) > -1) && !ignorePattern.test($); // we're only interested in files with certain extensions
}
)
);
diff -ur jsdoc-toolkit-orig/app/run.js jsdoc-toolkit/app/run.js
--- jsdoc-toolkit-orig/app/run.js 2009-01-08 06:32:58.000000000 +0900
+++ jsdoc-toolkit/app/run.js 2010-08-16 17:28:28.673092400 +0900
@@ -337,7 +337,7 @@
if (!path) return;
for (var lib = IO.ls(SYS.pwd+path), i = 0; i < lib.length; i++)
- if (/\.js$/i.test(lib[i])) load(lib[i]);
+ if (/\.jsm?$/i.test(lib[i])) load(lib[i]);
}
}
Only in jsdoc-toolkit: jsdoc.bat
diff -ur jsdoc-toolkit-orig/templates/jsdoc/class.tmpl jsdoc-toolkit/templates/jsdoc/class.tmpl
--- jsdoc-toolkit-orig/templates/jsdoc/class.tmpl 2009-09-03 06:37:31.000000000 +0900
+++ jsdoc-toolkit/templates/jsdoc/class.tmpl 2010-08-18 15:10:02.542253900 +0900
@@ -300,7 +300,10 @@
<if test="data.example.length">
<for each="example" in="data.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -399,7 +402,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -466,7 +472,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
@@ -565,7 +574,10 @@
<if test="member.example.length">
<for each="example" in="member.example">
- <pre class="code">{+example+}</pre>
+ <pre class="code">{+String(example)
+ .replace(/&/g, '&')
+ .replace(/</g, '<')
+ .replace(/>/g, '>')+}</pre>
</for>
</if>
モックが必要な場面、モックが有効な場面 - Aug 11, 2010
モック(Mock)とスタブ(Stub)の違いがよく分かってなかったんだけど、何が違うのか、そしてモックはどう使う物なのかということを、すとうさんに教えてもらって今更理解した。あとで会社のブログに書くつもりだけど、メモとして要点だけまとめておく。
- テストは基本的に、粒度の細かいブラックボックステストにした方がいい。
- 内部に持ってる隠しプロパティの値が正しいかどうか?という風な実装べったりのテストは、実装の変更に非常に弱い。
- なので、関数の返り値だけ見て検証できるような設計が、自動テストしやすい設計という意味で「良い設計」と言える。
- しかしブラックボックステストには限界がある。
- 色々な副作用を伴う機能だったり、非同期で処理するような機能だったり、1回の実行で複数の状態を遷移する機能だったり、という風に、単純に関数の実行→返り値を検証 とするだけではテストできない機能もある。
- ユニットテストのレベルでそういう機能があるのは設計が良くない証拠なので、こういう物は関数を細かい単位に解体して、単純に関数の実行→返り値を検証 というブラックボックステストを行えるような設計に直すべき。
- 処理待ちしてやりさえすればいいような場合、処理待ちのための機能を持ったテスティングフレームワークを使うと、単純な非同期処理なら簡単にブラックボックステスト化できる。
- 色々な副作用を伴う機能や、状態遷移があるような機能をブラックボックステストできるようにしようと思うと、「内部で状態の遷移のログを取っておいて、最後にそのログの内容が期待通りになっているかどうかを検証する」という風な形にならざるを得ない。
- ということをやろうと思うと、本番用のコードの中に「ログ取り用の処理」のような「実際に使う場面では無駄」なコードが増えていってしまう。
- テストしやすくするためにテスト対象の実装に手を入れるのはよくあることだし、そうやって手を入れた結果として関数が小さな単位に分割されていったり関数名と入出力の対応が分かりやすくなっていったりするのなら、それによって動作が安定するようになったりコードのメンテナンス性が高くなったりするから、いいことだ。でも「テストのためだけの実装」が増えていって、動作が不安定になったりコードのメンテナンス性が落ちたりするのでは本末転倒だ。
- 色々な副作用を伴う機能だったり、非同期で処理するような機能だったり、1回の実行で複数の状態を遷移する機能だったり、という風に、単純に関数の実行→返り値を検証 とするだけではテストできない機能もある。
- ブラックボックステストにし続けるためのコストが、本来の実装に悪影響を及ぼすようなレベルになってしまったら、そろそろホワイトボックステストに移行していい頃合いだ。
- 検証対象の機能の粒度が大きくなってくると、これはもう避けられない事と考えた方がいい。
自分は今まで、とりあえずユニットテストに注力していて、ある意味脅迫観念的な勢いで、ブラックボックス度合いを高くする事を心がけてた。今まではそれでだいたい問題なかった。でも最近になって、ブラックボックステストにしようとすると無理があるというケースにぶち当たるようになった。1つの機能の中でコロコロと遷移する内部状態を、どうにかして検証したいというようなケースが出てきた。
それですとうさんに相談したら、そういう時はモックを使えばいいと言われた。でも、話を聞く限りだとモックというのはテスト対象の実装の中の処理の流れを追う物のようなので、それじゃブラックボックステストにならないじゃないかと思った。それをそのまま言ったら、確かにテストはできるだけブラックボックステストになってた方がいいけど、機能テストやインテグレーションテストのような粒度の大きな単位のテストでは、処理の中で起こる様々な出来事や副作用を色々モニタリングして、すべての処理が期待通りに動いているかどうかを検証しないといけないから、必然的にホワイトボックステストにならざるを得ないと言われた。
それを聞いて、目の覚めるような思いをした。そうか、ブラックボックステストとホワイトボックステストの使い分けはそこが基準になるのか、と。今まで自分がホワイトボックステストを書かずに済んでいたのは、状態の遷移を伴うような機能を作る必要がなかったからだったんだ、テストをどうも書きにくいなあと思っていた機能は本当はホワイトボックステストにしたほうがいい物だったんだ、と。
そんなわけでUxUにモックの機能を実装した。
「JavaScript Mock」で検索するとJSMockとjqmockが上位に出てきたので、最初はそれらを参考にするように(メジャーな実装があるんだったらそれをそのまま取り入れるなりAPIを合わせるようにするのが望ましい)と言われたんだけど、ドットで繋げるメソッドチェインの記法がガンガン出てきて頭パンクした。
もう少し下の方までスクロールするとMockObject.jsというのが出てきて、こっちはファイル全体で3KBに満たない小さなライブラリなので、まずはここから始めることにした。何せコードが短いから、読むのもそんなに苦にはならない。モックの概念を言葉で説明されてもさっぱりだったけど、一通りの処理の流れを見たら、「モックというのは一体何をやらなきゃいけないのか」「どういう振る舞いが期待されているのか」ということがよく分かった。
MockObject.jsと同等の機能を一通り実装した後でもう一度JSMockの方を見たら、なるほどこれはこういう意味だったのかというのがやっと分かった。サンプルコードを見ても、モックという物の意味をそもそもよく知らない時点では、どこからどこまでがJSMockの部分なのかさっぱり分からなかったんだよね。ということで、MockObject.jsに加えてJSMock互換のAPIも付け加えてみた。jqunitの方は……もう別言語だからシラネ。
あと有名なのはJsMockito? これも頑張ったらできるかなあ、というかMITライセンスだしそのままぶち込んだ方が早いか……
タブの追加・削除のアニメーション - Aug 08, 2010
Firefoxで、タブを閉じる時にいきなりタブが消えるんじゃなくちょっとずつ消えるようなアニメーションが実装されたようだ。ツリー型タブにアニメーション効果を加えた時にも書いたけど、状態が不連続に変化するよりも連続的に変化した方が分かりやすいことは間違いないので、この改良は歓迎すべき事だと思う。
使い勝手的な面とか見た目的な面とかでは多分他の人が言及していると思うので、僕は実装とかAPIとかの面で感心した点に言及してみる。
このパッチが入るちょっと前に「新しいタブを開く時にアニメーション効果を適用する」という処理も入ったんだけど、この2つには違う所が1点ある。それは、既定の状態がアニメーション有りか無しかという点だ。
gBrowser.addTab(uri)で、アニメーション有りでタブが開かれる。gBrowser.addTab(uri, { skipAnimation : true })で、アニメーション無しでタブが開かれる。gBrowser.removeTab(tab)で、アニメーション無しでタブが閉じられる。gBrowser.removeTab(tab, { animate : true })で、アニメーション有りでタブが閉じられる。
今回のremoveTab()の既定の挙動とフラグ指定の仕様は大いに評価したい。何故かというと、これは互換性を最大限保つために必要なことだからだ。
タブを閉じる時にアニメーション効果を適用させるということは、タブに「閉じるという操作は行われたが、まだ実際にはDOMツリー状に存在している」という状態が加わったということだ。そのため、gBrowser.mTabContainer.childNodesで取得したタブの一覧の中に、本来であれば処理対象にしては行けないタブが含まれてしまうようになる。
これは大いに混乱を招く。アドオンの多くはタブを閉じる際のアニメーション効果のことなど知らないから、タブが閉じられたらすぐにDOMツリーからも消えることを期待している。そういう前提で書かれたコードが、片っ端から動かなくなってしまう恐れがある。
今回のパッチでは、この混乱を最小限にするための配慮が行われている。このような状態が発生する場面を「タブのクローズボックスがクリックされた時」と「Ctrl-Wなどのキーボードショートカットで現在のタブが閉じられようとした時」だけに限定することで、それ以外の場合は明示的に指示されない限りはアニメーションしないようにしてある。アドオンが要であるFirefoxとしては、APIの変更でアドオンが作りにくくなる・人気のアドオンが動作しなくなることのデメリットの方が、美しい設計のAPIにすることのメリットを上回ると考えられるから、この判断は合理的と言っていい。
今後の課題は、互換性を重視したことでAPIが分かりにくくなってしまった点をどうするか、ということではないかと個人的には思っている。特に、addTab()とremoveTab()という対になったAPIにおいて、似たような事をやるのにそれぞれやり方が違うというのは、あまり誉められる事ではないから。
ただ、今はとにかく、Mozillaが互換性を重視する決定をしてくれたことをありがたく思っている。
愚行権 - Aug 07, 2010
ロボット工学三原則っていうのがある。
- 第一条 ロボットは人間に危害を加えてはならない。また、その危険を看過することによって、人間に危害を及ぼしてはならない。
- 第二条 ロボットは人間にあたえられた命令に服従しなければならない。ただし、あたえられた命令が、第一条に反する場合は、この限りでない。
- 第三条 ロボットは、前掲第一条および第二条に反するおそれのないかぎり、自己をまもらなければならない。
リンク先にも書いてあるけど、これは平易に言い直せば「何より安全で、それでいて便利で、できれば丈夫で」ということだ。この優先順位は非常に重要で、便利さのために安全性を犠牲にしてはならないし、丈夫さのために便利さを犠牲にしても(本来求められている要件を満たさないような物になってしまっても)いけない。ロボットだけでなく道具一般を作る時にも言える事だ。
ただ、これを厳密に守っているとできない事というのは当然出てくる。例えば、人を殺すロボットというのは作れない事になる。これは、ロボット工学三原則がまとめられた背景の1つに「ロボットが人を殺すんじゃないかという恐怖を払拭するため」という目的があるから、その目的においては願ったり適ったりなんだけど。しかし、この三原則が出てくる小説の中でも「人間が敢えて危険を冒す必要がある作業をしようとして、ロボットが止めに入ってしまうので作業が進まない」というジレンマが出てくる。多分、スタントマンみたいな事や、新薬の臨床試験なんかは、できないことになる。
人命とか安全性とかとトレードオフでしか得られない物を、どうしても得たい。という人の行動を正当化するのが、愚行権という言葉だ。僕も愚行権をよく行使しているという自覚がある。本当だったらちゃんと栄養バランスを考えた食事を取らないといけないんだろうけど、やる気がないから晩ご飯はお菓子だけで済ませてしまおう、とか。
ただ、そういうトレードオフな選択をできるのは、あくまで自分の事だけなんだよね。自分と同じくらい(あるいはそれ以上)に判断力のある相手に「君もそうするかい?」と訊く事はできても、「お前もそうしろ」と押しつける事はできない。「君もそうするかい?」と訊いた後に、相手が「俺もそうしよう」と同じ行動を取る事を選ぶか、それとも自身の考えに基づいて拒否して「俺はちゃんと野菜食べたいから、コンビニ行ってサラダ買ってくるわ」と別の行動を取るか、その選択は相手に委ねる事になる。
お互いがそういう風に自己決定権を尊重し発動しあえるという前提があるからこそ、他人同士というのはうまくやっていけるものなのだと、僕は思う。他人から自己決定権を奪うような事は、原則としてしてはいけないと思っている。相手にも自分にも自己決定権があるからこそ、「みんな好きなようにやればいいと思うよ」と僕は言える。
問題は、本当にその決定が正当な物なのか?ということだ。
自己決定権の行使には、正確な判断材料が欠かせない。「めんどくさいなあ、お菓子で晩ご飯済ませちゃおうかな」という考えの決定には、「きちんとした食事を準備するのはめんどくさい」とか「お菓子だけ食べてると栄養バランスが偏る」とか「栄養バランスが大事」とか、いろんな情報が必要だ。諸々の情報を勘案して「それでも敢えてこの選択を取ろう」と判断したからこそ、その判断は自己決定権の行使として意味がある。「お菓子を食べると健康にいいんだよ、お菓子だけ食べてれば健康になれるんだよ」なんて間違った情報を吹き込まれてしまって、それに大きな影響を受けて下してしまった判断は、正当で意味のある判断と言えるのかどうか?
また、判断のエンジン自体も正しくないといけない。「何十年と先に起こり得るリスクと、今のこの一瞬の快楽とを天秤にかけて、敢えて今の快楽を取ろう」と判断するからこそ、その判断には意味がある。「将来って何? そんな事より、みんな毎日お菓子食べてるから僕もお菓子食べたい!!!!!!! お菓子おいしい!!!!!!」みたいな短絡的思考しかできないのだとしたら、慎重に考える事もできるけど敢えて短絡的になってみたのではなく、慎重に考えるという事がそもそもできないのだとしたら、その判断は、正当で意味のある判断と言えるのかどうか?
安全でないことをやることを他人に促して決意させるなら、その決定は、正しい情報と確かな判断力に基づいて行われていなくてはならない。正しい情報も提供できない、判断力を持っている事も確かめられないなら、危ないことはできないように設計しておくべき。そういう設計ができないのなら、そもそもそういうシステム自体を提供しないべき。そういう考え方が重要なのではないかと僕は思う。
話は変わるけど、そういう事を考え出して、子供を持つのは自分には無理なんじゃないか? とか、子供を持つというのは恐ろしい、とか、そういう風な事をふと思った。
だって、右も左も分からない、自己決定権を行使できるとはまだまだ言えない子供の人生を、自分が預かる事になるんですよ。自分一人の事なら、愚行権を気楽に行使できる。でも相手のことだとそうは言えない。特にその相手が、自分のしている事の良し悪しすらもよく分かっていないのなら。「子供の自主的な判断に任せてますから」と言って何も手を出さなければ、子供はただただ素直に自分にとっての快楽を追求して、お菓子ばっかり食べたりどっかの女を孕ませたりどっかの男に孕まされたり犯罪を犯したり、とにかく何でも馬鹿なことをするだろう(僕は性悪説の立場なのでそう考えてる)。
かといって、「子供に判断力なんか無いんだから」と何もかもを親が代わりに決めてしまうわけにもいかない。その「子供」が「大人」になる機会自体を潰してしまう、自分一人では何も決められない「大きな子供」に育ってしまうかもしれないし、あるいは、「自分のしたいことを何もさせてもらえない」というストレスで心を病んで不幸な人生を送らせてしまうかもしれない。
なんかもうその点だけで、世の人の親というのは尊敬に値するんじゃないかとすら思える。全くの放任でもなく、全くのがんじがらめでもない。完全に相手に委ねるのでもなく、完全に自分が判断を代行するのでもない。中間を行ったり来たりしながら最適なバランスで接する、そんなことを世の人の親はみんなやってるのか!?と思うと、うわー自分にはそんなこと無理だ、としか思えない。(そして実際、そうできなくてグダグダになった挙げ句、親子で万引きだとか自分で何も考えられない頭空っぽな大人だとか、そういうのが出てくるんだと思う。)
Windows 7のVirtualStoreに泣かされた - Jul 29, 2010
「C:\Program Files\foo\bar\hoge.txt」という位置にあるファイルを読み込んで処理するアプリケーションを開発していて、テストって事でhoge.txtを書き換えてみたのに、アプリケーションの方でhoge.txtを読み込んでみると、書き換える前の内容が返ってくるんですよ。え、このhoge.txtじゃなくて別の位置のhoge.txtを読みに行っちゃってるの? と思って「C:\Program Files\foo\bar\hoge.txt」を消してみると、「ファイルが見つかりません」ってエラーになるんですよね。だから見に行ってるのは確かにこのファイルで間違いないはずなのに。
僕は普段秀丸エディタを使ってるんですが、秀丸エディタって、書き込み権限が無いファイルを開くと「読み込み専用」って表示されて閲覧だけの状態になるんですよね。でも今回のhoge.txtはそうなってないから、ちゃんと書き換えも保存もできてるんですよ。一回秀丸エディタのウィンドウを閉じて、もう一度「C:\Program Files\foo\bar\hoge.txt」を開くと、さっき保存した時の内容になってるんで、書き込みに失敗したというわけでもない。なのに、自作のアプリで「C:\Program Files\foo\bar\hoge.txt」を開くと、秀丸エディタで書き換える前の内容が返ってくる。他にも同じ現象が起こってる人がいるみたいだし。何なんですかこれは?
……結論から言うと、犯人はWindows Vista以降で導入されたVirtualStoreという仕組みでした。
Windows Vista以降ではファイルに対して書き込みができない時に、「書き込めませんでした」というエラーを出す代わりに「C:\Users\ユーザ名\AppData\Local\VirtualStore」っていうフォルダの中にファイルを書き出すアプリケーションがあるみたいなんですね。今回は秀丸エディタがそうだったんですけど。実際、「C:\Users\ユーザ名\AppData\Local\VirtualStor\Program Files\foo\bar\hoge.txt」を見たら、さっき書き換えたはずの内容でhoge.txtが存在していました。
で、この状態で秀丸エディタで「C:\Program Files\foo\bar\hoge.txt」を開こうとすると、Windowsが「C:\Users\ユーザ名\AppData\Local\VirtualStor\Program Files\foo\bar\hoge.txt」の内容を返すみたいなんですよ。これはWindowsのファイル入出力の仕組みが透過的にやっていることらしくて、秀丸から見た時のファイルの位置はあくまで「C:\Program Files\foo\bar\hoge.txt」のままであるというのがポイント。で、この時メモ帳などの別のアプリケーションから「C:\Program Files\foo\bar\hoge.txt」を開くと、今度はVirtualStoreの方ではなく「C:\Program Files\foo\bar\hoge.txt」の実体の方が返される。その結果、「秀丸エディタとメモ帳でそれぞれ同じファイルを開いてるはずなのに、実際に見えてる内容が違う」という現象が起こる。
しかも最悪なことに、どうやら一回この状態に嵌ってしまうともうお手上げのようで、それ以後は秀丸ではVirtualStoreの方のファイルにしかアクセスできないんですよね。参った。もうVirtualStoreを全部消してしまいたい位なんですけど、VirtualStoreを見てみると他にもいろんなファイルが存在してるので、同じようにVirtualStoreの方の内容が返ってきてるお陰で正しく動作しているという状態のアプリケーションが他にもあるんだったら、不用意にVirtualStoreを消してしまうと大変なことになりかねないので消すわけにもいかない。
「コントロールパネル」→「管理ツール」→「ローカル セキュリティ ポリシー」で「セキュリティの設定」→「ローカル ポリシー」→「セキュリティ オプション」→「ユーザー アカウント制御:各ユーザの場所へのファイルまたはレジストリの書き込みエラーを仮想化する」を「無効」にするとVirtualStoreを無効にできるようなので、クリーンな環境でWindows VistaやWindows 7を使い始める時は、無効にしとくといいような気がします。本来できないはずの事をユーザに気取らせずにやろうとするから無理が生じるのであって、システムファイルをいじれるのは管理者権限がある人だけというルールを徹底していれば、無駄な混乱はしなくて済むのです。LinuxとかBSDとか、そういうものですし。
追記。付いたコメントの中に、僕の目には「Program Files以下にあるファイルをわざわざユーザが書き換えなきゃいけないという仕様が今の時代にはそもそもあり得ないでしょ。技術レベルの低い無能な似非プログラマがWindowsの仕様に逆ギレとか、まったく自業自得のくせに滑稽極まりないし。プププのプー」と言っているように見える物がいくつかあったけれども、Firefoxでいえばapplication.iniにあたるような、そう頻繁に書き換える訳じゃないけど可変のパラメータを外部ファイルで定義できるようにしておくためのファイルをいじってテストしてた時に遭遇した話なので、結構イラッとしました。
2019年4月25日追記。Windows 10になった今もVirtualStoreは仕組みとして存在し続けているのですが、さすがにこの時代になるとVirtualStoreのトラップに引っかかるアプリの方が時代後れでしょと言っていいような感じで、秀丸エディタも64bit版を使えばこの問題にハマらずに済むようになりました。よかったよかった。
JavaScriptのスタックトレース - Jul 26, 2010
先日のブラウザー勉強会で吾郷さんにお会いした際に、JavaScriptには言語の仕様として「例外がどこから投げられたのか」を知る為の仕組みが無いので独自のフレームワークを作る時に困ったという話を伺った。オレ標準JavaScript勉強会で何話せばいいか困ってた所だったので、それをネタに発表させてもらう事にした。
改めてECMAScriptの仕様書を確認してみたけど、確かに3rd Editionと5th Editionでは、例外オブジェクトの機能としてはError.prototype.nameとError.prototype.messageしか定義されていなかった(あとはconstructorとかtoString()とかその程度)。Wikipedia(英語の方)のECMAScriptの記事によるとECMAScript 3rd EditionはJavaScript 1.5とJScript 5.5の共通部分を抜き出す形で策定されたようで、実装してない方のIEに合わせてこうなったのか?とも思ったけど、調べてみたらJavaScript 1.5の頃はMozillaもError.prototype.stackはサポートしてなかった。それ以降にMozillaが独自に拡張した箇所ということのようだ。でも今回調べた限りではOperaもChromeもError.prototype.stackをサポートしていた(Operaの場合はこれに加えて、少しフォーマットが違うスタックトレースをError.prototype.stacktraceでも取得できる、ということをedvakfさんに教えていただいた)。メジャーなJavaScript実行環境でこれに対応してないのはIE(IE9PP3を含む)くらいのようだ……と思ったらSafari(Windows版)もサポートしていなかった。
吾郷さんのそれやUxUのようにデバッグを支援するためのフレームワークでは、スタックトレースは欠かせない要素だ。将来のECMAScriptの仕様に取り込まれてくれればいいのになあ、と思う。
勉強会ではせがわようすけさんに突っ込まれたけど、セキュリティのためにはなるべくこういう情報は出さない方がいいものらしい。しかし自分はスタックトレースの何がまずいのかがよく分かっていない。会場では「例えばスタックトレースでスクリプトのURLの中にセッションIDが含まれていたらセッションハイジャックされてしまう危険性がある」という例を教えていただいたけれども、それでもまだピンと来ていなかった。
さらにツッコミを受けたことで「なるほど、クロスドメインの制約を突破されてしまう」という事が問題なのだと分かった。ただ、実際にそれが問題になるケースってほんとにあるのかな? という疑問はまだ残っている。
分かりやすい話として、通常のXMLHttpRequestやiframeでは、別ドメインのドキュメントを読み込む事ができない・読み込んだとしてもその内容にスクリプトからアクセスすることはできない。
var iframe = document.createElement('iframe');
iframe.setAttribute('src', 'http://www.google.co.jp');
document.body.appendChild(iframe);
window.setTimeout(function() {
try{
alert(iframe.contentDocument.body);
}
catch(e){
alert(e);
}
}, 3000);
例えばこういうのは、Error: Permission denied for <http://piro.sakura.ne.jp> to get property HTMLDocument.body from <http://www.google.co.jp>.と言われてエラーになる。しかしスタックトレースにエラー行の詳細な情報が含まれていると、
try {
document.write('<script type="text/javascript" src="http://www.google.co.jp/" async="false" defer="false"></script>');
}
catch(e) {
var contentsFragment = e.stack;
}
とか
try {
var script = document.createElement('script');
script.setAttribute('type', 'text/javascript');
script.setAttribute('src', 'http://www.google.co.jp/');
script.setAttribute('async', 'false');
script.setAttribute('defer', 'false');
document.body.appendChild(script);
}
catch(e) {
var contentsFragment = e.stack;
}
とか
// window.onerrorはECMAScriptの仕様にはない独自拡張
window.onerror = function(aMessage, aSource, aLineNumber) {
// ここでaMessage, aSourceから情報を取れる可能性がある
}
var script = document.createElement('script');
script.setAttribute('type', 'text/javascript');
script.setAttribute('src', 'http://www.google.co.jp/');
script.setAttribute('async', 'false');
script.setAttribute('defer', 'false');
document.body.appendChild(script);
という風にして、別ドメインのドキュメントの内容を部分的にとはいえ読み取れてしまう可能性がある、というわけだ。特に3番目のwindow.onerrorを使う例はMFSA 2010-47: エラーメッセージのスクリプトファイル名からのクロスサイトデータ漏えいで実際に脆弱性になっていたことが確認されていて、既に修正されている。
なお、実際に現行バージョンのFirefox・Opera・Chromeで試してみたところ、1番目・2番目のtry-catchを使った例ではそもそも例外を例外として(そもそも、エラーが発生したのかどうかすら)捕捉できなかったので、今の所問題にはならない。ただ、今は問題にならなくても、今後登場するJavaScriptの実装ではこういう場合でも情報を取れるようになっている可能性はあるので、将来的に脆弱性の原因になるかもしれないという警告は確かにアリだとは思う。という所までは何とか理解できた。
ブラウザのレベルでは、クロスドメインやクロスオリジンになる時だけは例外を出さないとか詳細な情報を出さないとか、そういう対応の仕方はあるだろうけれども、「ECMAScript」の仕様でそこに言及するのは変だろうなあ。というややこしい事情を勘案すると、もう丸ごと全部仕様からドロップしてしまえという判断になるんかなあ。