Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

getBoundingClientRect()とgetBoxObjectFor()で取れる座標の違い - Mar 31, 2009
trunkでとうとうgetBoxObjectForがエラーを吐くようになってしまった - alice0775のファイル置き場 - Yahoo!ジオシティーズ
これを見て焦って今頃になってやっと調べた。
パッチによると、nsIDOMNSDocumentからgetBoxObjectFor()が消えて、nsIXULDocument専用のメソッドになった。ということなので、HTMLDocumentでgetBoxObjectFor()を使っているコードは全滅だ。何とかして代わりの方法を見つけないといけない。
document.getBoxObjectFor(element)で取れるのはnsIBoxObject、element.getBoundingClientRect()で取れるのはnsIDOMClientRectで、インターフェースが違う。
| 取りたい値 | nsIBoxObject | nsIDOMClientRect |
|---|---|---|
| ボックスの幅 | box.width | rect.right-rect.leftまたはrect.width |
| ボックスの高さ | box.height | rect.bottom-rect.topまたはrect.height |
| ボックスの左上の点のX座標(ドキュメントの原点基準) | box.x+左ボーダー幅 | rect.left+window.scrollX |
| ボックスの左上の点のY座標(ドキュメントの原点基準) | box.y+上ボーダー幅 | rect.top+window.scrollY |
| ボックスの右下の点のX座標(ドキュメントの原点基準) | box.x-左ボーダー幅+box.width | rect.right+window.scrollX |
| ボックスの右下の点のY座標(ドキュメントの原点基準) | box.y-上ボーダー幅+box.height | rect.bottom+window.scrollY |
| ボックスの左上の点のX座標(ビューポートの原点基準) | box.x+左ボーダー幅-window.scrollX | rect.left |
| ボックスの左上の点のY座標(ビューポートの原点基準) | box.y+上ボーダー幅-window.scrollY | rect.top |
| ボックスの右下の点のX座標(ビューポートの原点基準) | box.x-左ボーダー幅+box.width-window.scrollX | rect.top |
| ボックスの右下の点のY座標(ビューポートの原点基準) | box.y-上ボーダー幅+box.height-window.scrollY | rect.bottom |
nsIDOMClientRectのwidthとheightはどうもGecko 1.9.1以降でしか使えないっぽい。
例えば今使ってる環境のdocument.getElementById('reload-button')の場合はこんな感じ。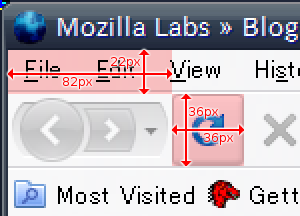 この時の値は以下の通り。
この時の値は以下の通り。
| nsIBoxObject | nsIDOMClientRect |
|---|---|
| box.width==36 | rect.width==36 |
| box.height==36 | rect.height==36 |
| box.x==83 | rect.left==82 |
| box.y==23 | rect.top==22 |
| rect.right==118 | |
| rect.bottom==58 |
xとleft、yとtopの間にずれがあるのは、nsIBoxObjectのxとyがいわゆるborder-box(border + padding + contentのボックス)ではなくpadding-box(padding + contentのボックス)基準であるからということらしい。nsIBoxObjectからborder辺の座標を取るには、getComputedStyle()でborderの幅を取って計算してやらないといけない。nsIBoxObjectもnsIDOMClientRectも、これら以外のプロパティはborder-box基準のようだ。
で、上の表には書いてないけど、nsIBoxObjectにはscreenXとscreenYというプロパティがあって、こちらで取れる画面上の座標もborder-box基準。そして、nsIDOMClientRectにはこれらプロパティが無いので、画面上の座標を取ることができない。
大まかに言って、nsIBoxObjectのxはnsIDOMClientRectのleft、nsIBoxObjectのyはnsIDOMClientRectのtopに読み替えて差し支えない。となると、残る問題は、screenXとscreenYに相当する値をどう取るかだ。
で、試行錯誤の結果、以下のようなコードができあがった。
function getBoxObjectFor(aNode)
{
// getBoxObjectFor() がある時はそれを使う。
if ('getBoxObjectFor' in aNode.ownerDocument)
return aNode.ownerDocument.getBoxObjectFor(aNode);
var box = {
x : 0,
y : 0,
width : 0,
height : 0,
screenX : 0,
screenY : 0
};
try {
var rect = aNode.getBoundingClientRect();
var frame = aNode.ownerDocument.defaultView;
box.x = rect.left + frame.scrollX;
box.y = rect.top + frame.scrollY;
box.width = rect.right-rect.left;
box.height = rect.bottom-rect.top;
// 親フレームの要素を辿っていく。
box.screenX = rect.left;
box.screenY = rect.top;
var owner = aNode;
while (true)
{
frame = owner.ownerDocument.defaultView;
owner = getFrameOwnerFromFrame(frame);
if (!owner) {
// 最上位のフレームまで来てしまったら、仕方ないのでwindowのプロパティを使う。
// でもウィンドウの枠の外側の座標なので、激しくずれる。
box.screenX += frame.screenX;
box.screenY += frame.screenY;
break;
}
if (owner.ownerDocument instanceof Ci.nsIDOMXULDocument) {
// XULのドキュメント中の要素なら画面上の正確な位置を取れる。
let ownerBox = owner.ownerDocument.getBoxObjectFor(owner);
box.screenX += ownerBox.screenX;
box.screenY += ownerBox.screenY;
break;
}
let ownerRect = owner.getBoundingClientRect();
box.screenX += ownerRect.left;
box.screenY += ownerRect.top;
}
}
catch(e) {
}
return box;
}
function getFrameOwnerFromFrame(aFrame)
{
// window.parentでは、<browser type="content"/> の内容の
// フレームからは親を辿れない。
// nsIDocShellTreeItemを経由すれば可能。
var parentItem = aFrame
.QueryInterface(Ci.nsIInterfaceRequestor)
.getInterface(Ci.nsIWebNavigation)
.QueryInterface(Ci.nsIDocShell)
.QueryInterface(Ci.nsIDocShellTreeNode)
.QueryInterface(Ci.nsIDocShellTreeItem)
.parent;
var isChrome = parentItem.itemType == parentItem.typeChrome;
var parentDocument = parentItem
.QueryInterface(Ci.nsIWebNavigation)
.document;
// フレームに結びついてるiframe要素を直接取る方法が分からないので、
// 泥臭い方法を……
var nodes = parentDocument.evaluate(
'/descendant::*[contains(" frame FRAME iframe IFRAME browser tabbrowser ",'+
'concat(" ", local-name(), " "))]',
parentDocument,
null,
XPathResult.ORDERED_NODE_SNAPSHOT_TYPE,
null
);
for (let i = 0, maxi = nodes.snapshotLength; i < maxi; i++)
{
let owner = nodes.snapshotItem(i);
if (isChrome && owner.wrappedJSObject) owner = owner.wrappedJSObject;
if (owner.localName == 'tabbrowser') {
let tabs = owner.mTabContainer.childNodes;
for (let i = 0, maxi = tabs.length; i < maxi; i++)
{
let browser = tabs[i].linkedBrowser;
if (browser.contentWindow == aFrame)
return browser;
}
}
else if (owner.contentWindow == aFrame) {
return owner;
}
}
return null;
}これにさらにborder幅によるズレとかposition:fixed;の場合への対応とかも盛り込んだ物を、ライブラリにしてみた。見ての通りchrome特権をバリバリに使ってるので、このコードはアドオンの中でしか動かない。画面上の絶対位置が必要になる場面なんてのはアドオンの場合くらいだろうから、別に問題ないと思うけど。
screenXとscreenYに相当する値を取るためにけっこう面倒なことをしているので、オーバーヘッドがきっと半端ない。nsIDOMClientRectの持ってる情報だけで済む場合はそれだけ使った方がいいと思う。
ちなみに、安直な発想でXULDocument.getBoxObjectFor.call(HTMLDocument, HTMLElement)というのも考えてみたけど、これは実際には使えない。残念。
テキストリンクとpopInとjQuery - Mar 31, 2009
popInが入っているとテキストリンクが動かない、ことの理由はどうも以下の2点によるみたい。
- popInがdblclickイベントを
stopPropagation()しているため、テキストリンクにイベントが渡されなくなっている。 - popInがポップアップアイコンの挿入位置を決定するために(?)、選択位置のテキストノードを動的に分割しており、仮に
stopPropagation()されない状態にしてテキストリンク側でイベントを拾って処理を行おうとしても、イベント発生時とテキストリンクが処理を行う時とでDOMツリーの構造が微妙に変わっていて、正常に動かない。
何か有効な対策が無いか考えてる。
ところでpopInは内部的にjQueryを使ってるようなんだけど、その旨の表記を僕には見つけられなかった。jQueryはMITライセンスとGPLのデュアルライセンスで、MITを選択した場合でもThe above copyright notice and this permission notice shall be included in
all copies or substantial portions of the Software.
(著作権表示とMITライセンスの許諾表示をソフトウェアの全コピーかもしくは重要な箇所で示す必要がある)ということなので、下手したらMITライセンスの違反ということになるような気が…… (一応フィードバックフォームから送ってはみた)
Mozilla Add-onsのアドオン開発者向けUIがパワーアップしてた - Mar 28, 2009
テキストリンクをThunderbirdにもインストールできるようにしたのにAMOのサイト上ではFirefox専用のままになってしまう件についてボヤいたところ、くでんさんに「Bugzillaで言えばいいじゃない」的な指摘を受けたので、確かにその通りだと思って、念のため新しくバグ報告する前に「target」あたりのキーワードで検索してみたら、Adding new compatible application fails when it's the first oneというバグが出てきて、でもFIXEDになってて「おっかしーなー」と思いながら最初に添付されてたスクリーンショットを見てみたら「Add New Application」と書かれたボタンがあって「なんじゃこりゃあああああこんなん見たこと無いぞおおおお?!」と思って、バグ報告しようとした時に「対象アプリケーション」の英語版表記を知りたくて英語ロケールに切り替えた状態になってたままで開発者用ページのトップに移動したら「新しいUIを試してみよう」みたいな今まで見たことない告知が一番上に表示されてて、そこから辿っていったら今テスト中らしい新UIにアクセスできて(新UIはまだ日本語じゃ利用できないようで、日本語に切り替えてアクセスしようとしたら見れなかった)、それを使うと手動で対象アプリケーションを追加できた。
あと、今までは一度アップロードしたバージョンは、ファイルを削除することはできてもその「バージョン」自体を無かったことにはできなかったんだけど、新UIの方ではそういうファイルが無い状態になったバージョンを「削除」する機能も加わってた。やっときたか……ていうかなんで今までできなかったんだ?
Thunderbird上でテキストリンクを使えるようにしたよ - Mar 27, 2009
テキストリンク バージョン3.1以降で、Thunderbirdでも利用できるようにした。
プレーンテキスト形式のメールでは、Thunderbird自体のURI自動認識の処理を置き換える形で動作する。
 Thunderbird本体のURIの認識部分は結構いいかげんなので、地の文とURIが連続してるとたまに酷い事になる。テキストリンク導入後は、Thunderbird自身による抽出結果を一旦全部白紙に戻して、もう一度URIの認識を自力で行うようになる。
Thunderbird本体のURIの認識部分は結構いいかげんなので、地の文とURIが連続してるとたまに酷い事になる。テキストリンク導入後は、Thunderbird自身による抽出結果を一旦全部白紙に戻して、もう一度URIの認識を自力で行うようになる。
同じような事をするアドオンが他にもありそう(っていうかFirefoxではLinkificationがそうだ)だけど、自分では見つけられなかったので……
ところで、AMOの方にもアップロードしたんだけど、過去にFirefox専用として登録したアドオンは後からThunderbirdにも対応した後も、Firefox専用アドオンとして扱われてしまって、Thunderbird Add-onsの方からは辿る事ができないようだ。これってどうにかならんのだろうか。
Mac OS Xのデフォルトテーマに合わせた新スタイルをツリー型タブに加えたよ - Mar 26, 2009
Tree Style Tabで選択可能な組み込みのスタイル指定の一つとして、Mac OS X上のデフォルトテーマ風の物を、cho45さんのStylish用スタイル定義を参考にして作ってみた。
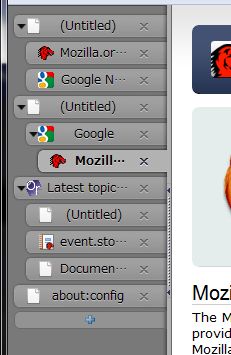 スクリーンショットはVista上での物だけど、OS X上でも確認はしてるのでご安心を。
スクリーンショットはVista上での物だけど、OS X上でも確認はしてるのでご安心を。
Firefox 3以前の環境ではcho45さんのスタイル定義ほぼそのまんまを適用するようになってて、その場合はタブの高さが26ピクセル固定になってしまうのでタブの中に何か追加する系のアドオン(具体的にはInformational Tab)との相性が非常に悪い。
で、それをなんとかする方法として、Firefox 3.5以降ではborder-imageが使えるということを思い出したので、その実験というか練習も兼ねて使ってみる事にした。
普通に考えると、tab要素自体に-moz-border-imageを指定すればそれでおしまいという事になるんだけど……ツリー型タブの場合はドロップ位置のマーカーを表示するためにborderを多用してるので、-moz-border-imageをtabに指定すると都合が悪い(普通のborderと同時に指定した場合、-moz-border-imageの方が優先されるようだ)。かといって、内側や外側にもう一つタブ全体を囲うXUL要素を増やそうとすると、他のスタイル指定と激しく競合して見た目がグチャグチャになるし……
で、色々試行錯誤して、Firefox 3以前でタブの右・左・中央のそれぞれに異なる背景画像を表示するために使っていたボックスを流用して解決する方法を思いついた。
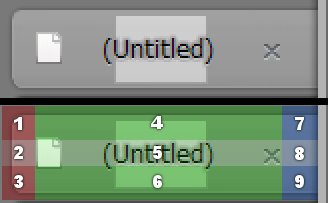 この拡大図で言うと、9個に分けられた各領域を普通だったら一つのボックスのborder-imageでカバーするところを、今回は1~3・4~6・7~9の3つのボックスに分けている。-webkit-border-imageや-moz-border-imageの例として紹介されているコードでは4つの辺の幅を同じにしてる例が多いけど、実は4つの辺はそれぞれバラバラに幅を指定できる。なので、
この拡大図で言うと、9個に分けられた各領域を普通だったら一つのボックスのborder-imageでカバーするところを、今回は1~3・4~6・7~9の3つのボックスに分けている。-webkit-border-imageや-moz-border-imageの例として紹介されているコードでは4つの辺の幅を同じにしてる例が多いけど、実は4つの辺はそれぞれバラバラに幅を指定できる。なので、
- 図の赤のボックスは
url("共通の画像") 10 10 10 10 / 10px 0 10px 10pxで右の辺の幅を0に。 - 緑のボックスは
url("共通の画像") 10 10 10 10 / 10px 0 10px 0で左右の辺の幅を0に。 - 青のボックスは
url("共通の画像") 10 10 10 10 / 10px 10px 10px 0で左の辺の幅を0に。
という風にしてやる事で、1枚の画像で3つのボックスそれぞれに異なる部分を切り出して適用するような効果を得られる。
また、このままだとタブの高さがborder-imageの幅の分だけ高くなってしまう(border-imageの上辺+タブのラベルの高さ+border-imageの下辺=タブの高さ)ので、タブのラベルやアイコンなどに対して上下にネガティブマージンを設定して、強制的にタブの高さを小さくするようにしてみた。上の図は切り出し位置を示すためにわざと高さを広げた状態だけど、ネガティブマージンを効かせれば、冒頭のスクリーンショットのようなスリムなタブになる。
Firefox 3.5 on Mac OS Xのタイトルバーまわりの新機能 - Mar 24, 2009
以前、Mac OS X上でタイトルバーとツールバーがくっついた様な見た目を実現するためにFirefox 3から導入されたactivetitlebarcolor属性とinactivetitlebarcolor属性について調べたけど、このあたりの仕組みがFirefox 3.5ではまた変わった。Firefox本体に同梱されるテーマでは上記の仕組みは使われなくなって、代わりに-moz-appearanceプロパティの-moz-mac-unified-toolbarという値が指定されている。
-moz-appearance: -moz-mac-unified-toolbarと指定されたtoolbar要素は、外観が自動的にUnified Toolbarになる。- と同時に、そのtoolbar要素が含まれているウィンドウのタイトルバーも自動的にUnified Toolbarスタイルになる。
- Unified Toolbarスタイルになったタイトルバーの色は、ウィンドウがアクティブな時は
-moz-mac-chrome-active、ウィンドウがアクティブでない時は-moz-mac-chrome-inactiveになる。 - 一旦Unified Toolbarスタイルが適用されたウィンドウは、後から当該toolbar要素に
-moz-appearance: none等を指定してUnified Toolbarでなくした後も、タイトルバーはUnified Toolbarスタイルのままになる。
最後の項の挙動はひょっとしたら今後変わるかもしれない。スタイル指定の意味合い的には、Unified Toolbarが存在しなくなったらタイトルバーの表示も元に戻すべきだろうし。とりあえず2009年3月24日時点のビルドではこうだった、ということで。
ちなみに、activetitlebarcolor属性とinactivetitlebarcolor属性は、今の所はFirefox 3.5でもまだ使えるみたい。
タブの縦置き、タブのグループ化 - Mar 19, 2009
ツリー型タブに似たアドオン2つを新たに知った。
VertTabbarは、タブバーをウィンドウの右または左に移動して縦列タブにするアドオン。Vertigoはずいぶん昔に更新が止まってるようなので、その代替と言えるだろうか。カスタマイズ機能も色々あるみたい。
タブグループマネージャーは、名前から見ても機能的にもTabGroupsの後継っぽい。でも多分中身は全然別物なんだろう。今見てないグループのタブ全部をメモリから追い出して省メモリにする機能とか、検索バーからの検索結果を自動的にグループにする(セカンドサーチとも連携できるらしい)とか、色々高機能だ。
Ubuntu 8.10でFirefox 2 - Mar 19, 2009
以前のUbuntuではfirefox-2というパッケージ名でFirefox 2をインストールできたけど、Ubuntu 8.10だとそういうパッケージは無いと言われてしまう。仕方がないからMozilla.orgからバイナリを落としてきて/opt以下に置いてみたけど何故か起動できない。
という所で止まってたんだけど、コンソールに出るエラーメッセージをよく見たら「libstdc++.so.5が見つからない」と書いてあって、パッケージマネージャを見たらlibstdc++6は標準で入ってるけどlibstdc++5はインストールされてなかった。5の方を入れてみたら、Firefox 2が無事起動した。
また同じ事で詰まらないようにメモしておこう。
unstableとかtrunkとかsidとか - Mar 18, 2009
アドオンのテキストリンクは他のアドオンに比べて異常に更新頻度が高いように思えますがなぜでしょうか?
いちんちに5回も6回も更新してた頃があったって信じられるかい?
テキストリンクがFirefox 3で速くなった - Mar 17, 2009
テキストリンク 3.0.2009031701で、Firefox 3上では部分的に処理が高速になった。具体的には、Rangeを文字列にする処理がそう。Venkmanでプロファイルを取ってみたらここが滅茶苦茶頻繁に呼ばれてて、ここが遅いと全部が遅くなるという感じで他の部分に影響してたんだけど、nsIDocumentEncoderで代用できる事にやっと気がついた。
nsIDocumentEncoderについては、以前に選択範囲からHTMLのソースを取得する方法を調べてて行き着いたnsISelectionPrivateの実装を見て、存在は知ってた。これを使うことができれば、HTMLを選択してコピー&テキストエディタにペーストした時のように、BR要素の位置で改行されたりP要素の位置で空行が入ったりSCRIPT要素の内容を除外したりといった、よくある処理が行われた後の整形済みテキストを取得できるんじゃないか、と思って色々試してみたんだけど、その時は、JavaScriptからコンポーネントの機能にアクセスできないようだったので結局諦めてた。でも今日になってふと試してみたら、いつの間にかJavaScriptからもCi.nsIDocumentEncoderが見えるようになってて、これ幸いと使ってみたところかなり期待通りの結果が得られたので、そのまま採用した。
使い方はこんな感じ。
// インスタンスを取得
var encoder = Cc['@mozilla.org/layout/documentEncoder;1?type=text/plain']
.createInstance(Ci.nsIDocumentEncoder);
// 変換対象のドキュメント、変換先の形式、変換ロジックのフラグを渡して初期化
encoder.init(content.document,
'text/plain',
encoder.OutputBodyOnly | encoder.OutputLFLineBreak);
// DOMRangeをセットして……
encoder.setRange(range);
// 文字列に変換する
var result = encoder.encodeToString();前述した通り、HTML的に非表示になる事が期待されてる要素が除外されたり、画面上の改行位置で文字列の方にも改行文字が入ってくれたりと、単純にDOMRangeのtoString()で文字列化するだけだと問題になる点がこれで一挙に解決される。
JavaScriptから使えるのはGecko 1.9以降のみのようなので、Firefoxの場合は3以降に限定ということになる。Firefoxは2のサポートが切れてるからまあいいんだけど、ThunderbirdはまだGecko 1.8系のままなので、恩恵にあずかれないのが残念だ。
nsIDocumentEncoderを使うようにした副次的なメリットとして、<td>URI1</td><td>URI2</td>のようにセルの間にホワイトスペース文字が無いテーブルでも、nsIDocumentEncoderで文字列化する時はセルの間にタブ文字が入ってくれるため、それぞれ別々のURI文字列として検出できるようになった(最初の段階の「Rangeを文字列化してURIっぽい文字列を正規表現で探す」処理において、それぞれのセルに書かれたURI文字列がちゃんと別々の物としてヒットするようになった)。
追記。3.0.2009031801でさらに高速化した。高速化っていうか、なんていうか……今まで「URIっぽい文字列をマッチング→マッチングしたURIっぽい文字列をページ内検索→ちゃんとしたURIかどうか絞り込み」とやってて、ページ内検索が大量に発生すれば発生する程スピードが遅くなってたんだけど、これを「URIっぽい文字列をマッチング→ちゃんとしたURIかどうか絞り込み→ページ内検索」となるように(ある程度)処理の順番を入れ換えたところ、ページによってはアホかってぐらい速くなった。なんでここに気付かなかったんだろう。マヌケすぎる。