Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

「何もしてないのに急にnpm installできなくなった」への立ち向かい方 - May 06, 2021
(この記事はQiitaとのクロスポストです。)
初心者丸出し感がものすごいのですが、標題の通りのことが起こってしまいました。とあるJavaScript製の自作ソフトウェアの文法チェックにeslintやjsonlint-cliを使いたくて、package.jsonを置いておいて、npm installでそれらをインストールできるようにしていたのですが、それが突然以下のようなエラーで止まるようになってしまいました。
$ npm install
npm ERR! invalid options argument
npm ERR! A complete log of this run can be found in:
npm ERR! /root/.npm/_logs/2021-05-xxTxx_xx_xx_xxxZ-debug.log
他の自作ソフトウェアでも、npm installしようとすると同じエラーで止まってしまいました。メッセージには、詳細を見たければログを読むように書かれており、そのログファイル(/root/.npm/_logs/2021-05-xxTxx_xx_xx_xxxZ-debug.log)を見ると、具体的なエラー箇所は以下のような感じでした。
27 verbose stack TypeError: invalid options argument
27 verbose stack at optsArg (/usr/local/lib/node_modules/npm/node_modules/mkdirp/lib/opts-arg.js:13:11)
27 verbose stack at mkdirp (/usr/local/lib/node_modules/npm/node_modules/mkdirp/index.js:11:10)
27 verbose stack at tryCatcher (/usr/local/lib/node_modules/npm/node_modules/bluebird/js/release/util.js:16:23)
27 verbose stack at ret (eval at makeNodePromisifiedEval (/usr/local/lib/node_modules/npm/node_modules/bluebird/js/release/promisify.js:184:12), <anonymous>:13:39)
27 verbose stack at Object.mkdirfix (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/cacache/lib/util/fix-owner.js:36:10)
27 verbose stack at makeTmp (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/cacache/lib/content/write.js:121:19)
27 verbose stack at write (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/cacache/lib/content/write.js:35:19)
27 verbose stack at putData (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/cacache/put.js:11:10)
27 verbose stack at Object.x.put (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/cacache/locales/en.js:28:37)
27 verbose stack at WriteStream._flush (/usr/local/lib/node_modules/npm/node_modules/npm-registry-fetch/node_modules/make-fetch-happen/cache.js:156:21)
27 verbose stack at WriteStream._write (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/index.js:36:35)
27 verbose stack at doWrite (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/node_modules/readable-stream/lib/_stream_writable.js:428:64)
27 verbose stack at writeOrBuffer (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/node_modules/readable-stream/lib/_stream_writable.js:417:5)
27 verbose stack at WriteStream.Writable.write (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/node_modules/readable-stream/lib/_stream_writable.js:334:11)
27 verbose stack at WriteStream.end (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/index.js:45:41)
27 verbose stack at WriteStream.end (/usr/local/lib/node_modules/npm/node_modules/flush-write-stream/index.js:42:47)
依存関係のどこかで、あるライブラリの動作が変更され、それに依存していた別のライブラリが動作しなくなる、という事態は度々発生します。RubyでもNode.js(JavaScript)でも、おそらくはPHPでもPythonでも、パッケージマネージャを使っていると、「色々なライブラリが依存関係で自動的に入ってくるけれども、そのそれぞれの内容はチンプンカンプン。にもかかわらず、依存関係が原因の実行時エラーが発生してしまって問題解決の糸口すら掴めない」という状況が発生しがちでしょう。
僕はJavaScriptを長く書いてきてはいますが、パッケージマネージャそのものには明るくなく、このような状況が発生するとお手上げになりがちで、そういう意味ではまったく初心者レベルと言えます。今回も、エラーが出た瞬間に顔が真っ青になり、操作を繰り返しても状況が変わらないことでさらに血の気を失う、という絶望的な状況でした。
結論から先に言うと、この問題はNode.jsを入れるのに使っていたnのバージョンが古かったせいで発生していました。n自体を最新の物に入れ換えてn 16.1.0で現行の最新リリースのNode.jsを入れ直した所、この問題は無事に解消され、npm installが成功するようになりました。
以下は、今回この問題の解決策に辿り着き、原因を把握するまでの過程で行ったことの記録です。今回の問題自体は、誰の環境でも起こるという物ではないので、直接の参考にはならないと思いますが、未知の物と立ち向かいながら調査をして、現状を把握し問題解決を図る際の、暗闇の歩き方の参考にしてもらえれば幸いです。
シン・エヴァンゲリオン劇場版(ネタバレ感想) - Mar 09, 2021
以下、ネタバレ感想です。未視聴の方は読まないことを強く強くお勧めします。
Windows 10で「デスクトップの解像度」と「アクティブな信号解像度」が一致しない現象が発生したときの解決方法 - Feb 01, 2021
先日導入したLGの35型液晶をLet's noteの外部ディスプレイとして接続して、「複数のディスプレイ」→「表示画面を拡張する」を選択したときに、表示が期待通りにならない現象が発生した。
このディスプレイの最大解像度は3440×1440なのだけれど、Windowsのディスプレイ設定で解像度を誤って4K(3840×2160)に一度設定した後、3440×1440に戻したのに、ディスプレイ側に「推奨解像度を超える解像度の信号が入力されている」旨の表示が出てしまう。

どうも、「3840×2160の解像度で信号が出ているけれど、その真ん中あたりの3440×1440にだけデスクトップが表示されている」という訳の分からない状態になっているらしい。そのせいで、ディスプレイ側で3840×2160を3440×1440に収めるように縮小表示されてしまって実効表示領域が狭くなるし、デスクトップ部分を全体に表示しようとしたら、そこからさらにもう1回拡大することになるので、全体がボケボケになる、という具合だった。
この状態、Windowsの「設定」→「ディスプレイ」では確かに解像度として3440×1440が選択されているのだけれど……
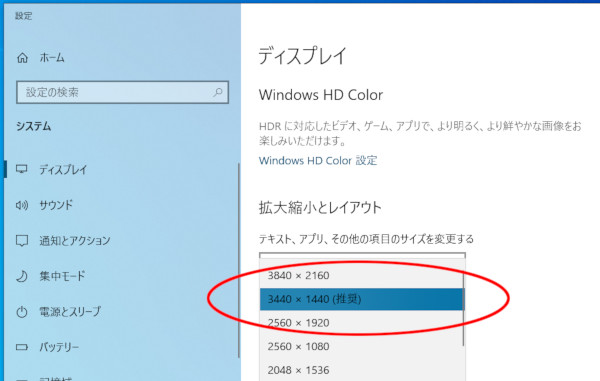
「ディスプレイの詳細設定」を見ると、「デスクトップの解像度」が3440×1440なのに、「アクティブな信号解像度」は3840×2160と、それぞれ異なる数字が表示されていた。


この状態を解消する方法はないものかと検索していたら、別の製品のAmazonのカスタマーレビューにヒントがあった。曰く、Windowsの設定画面ではなく、ディスプレイアダプターのプロパティで「モードの一覧」を開くとすべての解像度・色深度のリストが表示され、そこから適切な解像度を選択し直すといいらしい。
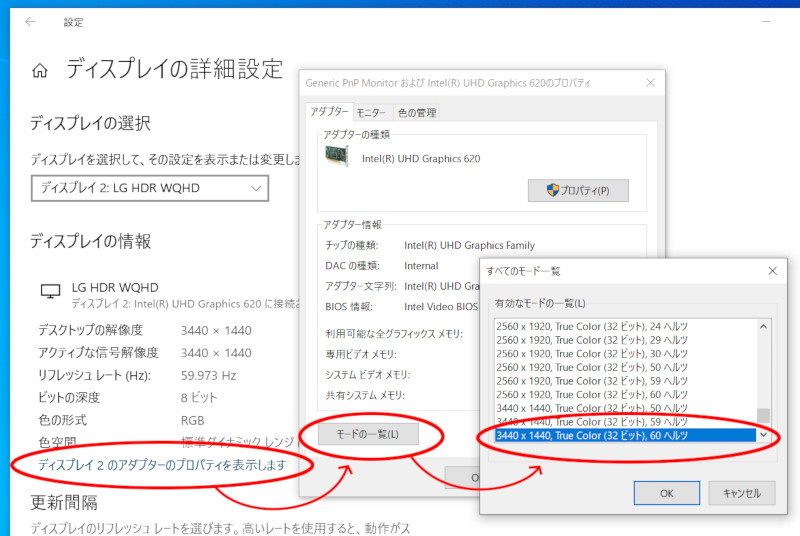
試しに見てみると、このリストでは「3440×1440 True Color(32bit) 59ヘルツ」が選択された状態になっていた。そのすぐ下にあった「60ヘルツ」の項目を選択して「OK」でダイアログを閉じ、戻った際のディスプレイアダプターのプロパティで「適用」ボタンを押すと、無事に「デスクトップの解像度」と「アクティブな信号解像度」の両方が3440×1440に揃った状態になった。ディスプレイ側で等倍表示されるようになり、文字も絵もクッキリ見える状態になった。これでようやくまともに使える。
他に同じ現象で困った人がこの情報に辿り着けるように、記録を残しておく。
「ディスプレイアーム二刀流や!」とテンション上がったけど2週間で1本がお役御免になった話 - Jan 31, 2021
昨年のイベントのトークセッションで漫画の制作環境を紹介した時、こんな感じの環境ですという写真を出した。

ディスプレイ3つというと豪勢に聞こえるけど、左のサブはD-Sub 15pin接続の17インチ1280×1024(妻が独身時代から使っていた物を、不要になったとのことで譲ってもらった)、右のメインはDVI-I接続の17インチ1280×1024(16年前に買ったEIZOのFlexScan)で、どちらも年代物。ある物は駄目になるまで使う勿体ない精神で、ずっと使い続けてきてた。
自宅のPCが急死したので買い換えた(死んだWindows 10 PCから新しいWindows 10 PCへの移行) - Jan 31, 2021
次の号に掲載される予定のシス管系女子の原稿を制作中に、突然画面がグリッチしたかと思ったら無反応になり、電源長押しで再起動を試みても画面は真っ暗のまま、UEFIの画面すら出てこなくなってしまった。追加で挿してたグラボを抜いても状況変わらずだったので、マザーボードとかオンボードグラフィックスとかその辺がお亡くなりになったのだと思われる。前回調達して移行したのは2017年5月だったので、享年約3年9ヵ月だった。
作業中の原稿は、そのPCの起動ドライブだったSSD(M.2 NVMe)の中に閉じ込められてしまってたんだけど、AOTECHというブランドから出てるUSB接続の外付けHDDとして使えるようにするケース(当初、「M.2」という点だけに気を取られて「M.2 SATA」のみ対応のケースを買いそうになってしまったけど、Twitter上で「安い物はM.2 SATAのみ対応でM.2 NVMeと互換性が無いよ」と指摘を頂いて、ギリギリで回避できた。危なかった)を使って取り出して、別のPCでとりあえず完成まで仕上げて提出した。この間1週間もかかってない。
それと並行して進めなくてはならなかった新PCの調達だけど、そういう切羽詰まった状況で吟味してられなかったので、前回と同じくパソコン工房のBTOのクリエイター向け構成にした。4年の延長保証を付けずに購入したPCが3年9ヵ月で死んでしまったので、今回は4年保証も付けた。
移行は概ね、過去にやった以下のそれぞれの作業の合わせ技で行った。
最新の情報へのアップデートも兼ねて、改めて書き起こしておく。
正論が抑圧の象徴になる時代? - Jan 13, 2021
レッドブルが くたばれ、正論。
というコピーで新成人向けの広告を打った、という話を見かけた。
この世の行き過ぎた正しさが、君の美しいカドを丸く削ろうとする
といった文からは、いわゆるポリコレ疲れ、左翼・リベラル的な言説への反動、のような雰囲気を感じる。若者を抑圧してくるそういった物に抵抗しよう、というメッセージのように感じられた。
広告が意図する所は一応理解できてると思う。挑戦はした方がいいし、うるさく言って足を引っ張ってくる年寄り連中の言うことを真に受けて萎縮しない方がいい。そこの所に異論はない。
だけど、このコピーに、僕は真っ先に違和感を覚えた。
僕は今38歳で、新成人だった頃から遠く離れた所に来てしまったのだけれど、自分が新成人やそれより若かった頃を思い返すと、「弱い立場から正論を武器に抗弁したが、正論が通らなくて煮え湯を飲まされた」経験の方が記憶に強く残ってる。
融通が利かなくて、弱い立場のこちらに対して抑圧を押しつけてくる物は、僕にとっては「筋の通った正論」ではなくて「筋の通らない因習・慣習」だった(と感じられた)ように記憶してるから。
- 抵抗者
- 「自分が教わった理屈に基づいて考えると、これこれこういう理屈で、こうあるべきなんじゃないの? なんでそうなってないの?(正論)」
- 既得権益者
- 「現実を知らないガキは黙ってろ。ガキにはわかんねー大人の事情って物があるんだよ(理屈の通ってない抑圧)」
こんな感じだった気がしてる。
レッドブルの広告に書かれた「正論」という言葉からイメージされる抑圧は、
- 抵抗者
- 「理屈とかよく分かんないんだけど、自分にはどうしても納得できない。これっておかしいんじゃないの?(素直)」
- 既得権益者
- 「理屈を知らないガキは黙ってろ。これこれこういう理屈でこうなってるんだから、素人が浅知恵で口出すな(正論ぽい抑圧)」
こういう感じなのかなと思った。実際、そういう場面は自分でも体験したことがあるし。
また、正論を武器にしていた左翼かぶれの知識人達が、かつては被抑圧者だったとしても、今では抑圧者の側になっているケースも、多々あると思う。
ただ、(これは、この広告のメッセージそのものというよりも、この広告のような言葉の選び方がごく自然に出てくる発想や、受け入れられてしまう風潮に対しての意見なのだけれど、)「正論」というものを権力と同一視して、抵抗者は権力とともに正論もを否定せよというのは、僕には、知的には後退してると思える。
正論は誰でも手に入れられる武器なのに、それをわざわざ忌むべき物と位置付けるのは(ともすれば、手放すことを奨励しているとも取れるメッセージを発するのは)、自分で自分の首を絞めてると思える。
僕としては、抵抗者には常に、正論を武器にしていてもらいたい感覚がある。
納得できない部分があれば、頑張って言語化して論理立てて正論で主張して欲しいし、
権力側が主張する、一見すると正論に見える言葉の中に巧妙に隠蔽された詭弁を明らかにして、その正論じみた言説の正論でなさを暴くようにして欲しい。
腐敗した古い正論を、より洗練された正論で打ち崩して欲しい、と思う。
今抑圧してきてる者達が、僕みたいなおっさんが、「正論」という建前で言ってる諸々のことの内容を嫌いでも、それは構わないので、ただ、「正論を立てて主張する」という枠組み自体まで否定しないで欲しい。
(……と、アイドルグループを卒業した人のような事を言ってる時点で、この枠組み自体が見捨てられる風潮はもう止まらないのだろうな、という気もひしひしとするけど……)
ガンダムマーカーエアブラシシステム良かったよという話 - Jan 01, 2021
昨年末にFRONT MISSION STRUCTURE ARTSの3体を塗るのに使ったガンダムマーカーエアブラシシステムがすごく良かったので、その話です。
そもそも、僕は昔からプラモの色塗りがクッソ下手で、ものすごく苦手意識がありました。ガンダムTR-1も塗装前で投げ出しちゃったし。自分で塗った物よりGFFやROBOT魂の方が全然見栄えがするし。プラモはもう、成形色そのままで色分けされてるMGくらいしか作らないだろう、くらいに思ってました。
でも、nippperでプラモを成形色そのままで組んだ記事をたくさん見ているうちに、「もしかして……塗らなくてもいいんじゃないか……?」と思えてきて、そんなタイミングでのFRONT MISSION STRUCTURE ARTSが発表されたため、「ヴァンツァーの立体! 知ってるデザインとちょっと違うし色分けもされてないけど、絶対欲しい!!」と思って、ポチってしまいました(という具合に唯一の立体物と思い込んでたけど、後でWANDER ARTSという完成品フィギュアのシリーズが既にあったことを知った)。まあ、成形色がサンドイエローだから、なんなら砂漠戦塗装と思うこともできるだろうし。
HGUCセカンドV、HMM Fire Foxを片付けた後、いよいよ今回の積みプラ消化の本命だったFRONT MISSION STRUCTURE ARTSの4体に取りかかるにあたって、様子を見るための練習として、思い入れがまったく無かったナムスカルから作り始めました。その際、Fire Foxの耳の内側を塗るのにファントムグレーを使えるかな?と思って買ったジオン軍6色セットに入っていたザクダークグリーンが、公式の作例のナムスカルの色に近い気がしたので、軽い気持ちでマーカー直塗りで全塗装してみることにしました。
しかし、これがめちゃめちゃ難しかった……細かい所にマーカーの先が届かないのはまだいいんだけど(そういう所は爪楊枝を筆代わりに使った)、モールド周辺や広い面で塗料がめちゃめちゃ弾かれてしまい、乾いた所に重ね塗りしても、一度目に塗った方の塗料が溶け出して弾かれて、重ねて塗ってるうちに浅いモールドが塗料で埋まってしまったりもして……という具合で、全然狙った通りに塗れませんでした。1つ前のエントリの写真ではわかりにくいですが、角度を変えてみれば

というありさまです(脚部側面が特に顕著)。塗り→乾燥待ち→重ね塗り→乾燥待ち→また重ね塗り と時間がかかった上でこれなので、いいとこなしでした。物が物なので、天然ウェザリングに見えなくもないのが救いでしょうか。ともかく、時間的にも仕上がり的にもマーカー直塗り全塗装はキツイと痛感しました。
とはいうものの、一個塗ってしまうと、残りも塗装しないとバランスが悪い気がしてきます。1個だけ色付きだと仲間はずれ感があるし、ゲーム中でも(少なくともSFCの初代では)各ヴァンツァーは色とりどりだったため、全機同色よりはカラフルな方が「らしく」感じます。
そんな感じで悩みつつ、外出のついでに量販店のプラモ関連売り場を見ていたら、ガンダムマーカーエアブラシシステムが目に留まりました。普通のエアブラシは、ハンドピースやエアコンプレッサーなど必要な機材を全部揃えると2万円以上には絶対になりますが(と思っていたんですが、最近は1万円を切る据え置き型コンプレッサーもあるんですね……時代は変わった……)、こちらはエアー缶1個同梱で3千円くらいとお手頃価格です。
この製品の存在は前から一応知ってはいましたが、ペン先に向かって横から空気を当てる構造ということで、「これって漫画の血しぶきなどの表現で使われていた「筆にインクをたっぷり含ませて、息を吹きかけてインクを飛ばす」技法(スパッタリングの一種?)みたいな物なのでは? ということは、まさに血しぶきみたいなボタボタの仕上がりになってしまうのでは? エアブラシといいつつ、実際は子供騙しのオモチャなのでは?」という不安がありました。
……が、そういう不安は杞憂だったようです。店頭でスマホで検索して、実際に使ってみた人のレビュー記事を見てみると、エアブラシとして全然実用に足る品質のようでした。
- 素組みでガンプラ!ガンダムマーカーエアブラシシステムの活用法・基本【後編】 | 電撃ホビーウェブ:ファンネルの塗り分けのぼかしの所を見ると、飛散する塗料の粒子がかなり細かいのが分かる。
- ガンダムマーカーエアブラシシステム!! | 一撃確殺SS日記:下の色が透けまくって実用に耐えないクソ隠蔽力のあのガンダムホワイトで、こんなにフラットで綺麗な塗装面が得られるなんて……
手持ちのガンダムマーカーと組み合わせて使えて、値段も安い。完成した物の置き場所がなくコンスタントに模型を作り続ける予定がない自分としては、とりあえず残りの3体を塗るための物として、有力な選択肢に思えます。ということで、早速買って帰ることにしました。
ガンダムマーカーエアブラシシステム & 専用替え芯(6本入り) & Mr.エアースーパー190 3点セット cmGMA01-01K -PA148 Mr.ホビー
ホビーベース プレミアムパーツコレクション 持ちやすい塗装棒 中 ホビー用塗装用具 PPC-Nn09
棒付きのクリップは各社が色々な商品名で出しているようです。元々こういう道具はあまり買い揃えるつもりはなかったのですが、HGUCセカンドVにトップコードをかける際に、ランナーを棒状に切ってマスキングテープでパーツを固定して……という作業を久々にやってみて面倒さに嫌気がさしたため、数百円の出費で時短になるならと思って買ってみました。(この棒を刺すための台も売られていますが、僕はたまたま家にちょうどいいサイズの発泡スチロールの箱があったため、そこに雑にブッ刺して使っています。)
実際に自分で使ってみて思い知らされたのは、何と言っても塗装面の段違いの綺麗さです。

フトモモ横の凹凸の多い面も、臑の横の平面も、足の甲の曲面も、最初からそういう色のパーツだったっけ?というくらいに滑らかな塗装面を得られています。肩の白ラインの右のちょっと色が違う部分は、マーカー直塗りでリタッチした跡です。これはちょっと目立つ感じになってしまいましたが、「あっ、やっちゃった」という部分を同じ色でサッとリタッチできるのもガンダムマーカーの便利な所です。
しかも、塗装後の乾燥時間が短い。溶剤がすぐ揮発して塗料が定着するので、マーカー直塗りの時のように下の色が溶け出てくるということもなく、重ね塗りができます。この画像の部分では、ガンダムグレーで全体を塗った上からマスキングして、各部のガンメタを重ね塗りしました。
これらはエアブラシの一般的な特性ですが、「ガンダムマーカー」ならではの利点もあります。
- 臭くない。通常のエアブラシ塗装では塗料の希釈にも使った後の掃除にもシンナーが必要ですが、こちらはほぼ無臭です。
- 色の使い分けが容易。通常のエアブラシ塗装では基本的に、1つの色を塗ったら次の色を使う前に掃除が必要(色の順番でこれを省略するテクニックはあるそうです)ですが、こちらはマーカーを交換するだけです。「同じ色を一気に塗らないといけない」という制約が無く、「さっき塗ったあの色をまた塗り直す」みたいな事もできます。後片付けも、マーカーを外してキャップを閉めるだけです。
マーカー故の注意点もいくつかあります。
- ペン先へのインク充填は小まめにしないといけない。色にも依りますが、自分の場合、1パーツ塗るごとに1~2回程度の重点が必要な印象でした。その都度マーカーを外すので、ペン先の位置の調整も小まめにやらないといけません。
- (メタルカラーは特に)ペン先が詰まって使えなくなる事がある。ペン先を押しつけるとドバッと塗料が出てくるのにエアブラシにセットしてもまったく色が乗らない、というときはこれです。メタルカラーの場合、ペン先の塗料の通り道に金属粉が詰まるらしく、特にこの問題が起こりやすいようです。替え芯(エアブラシシステムのセットに3本付属しているほか、6本単位でも買える)に交換すると、また出るようになります。
- 比較的割高。ものすごい勢いで塗料が消費されるので、全塗装の場合、マーカー1本でプラモ2体は塗りきれないくらいな気がします。
- 塗料の飛ぶ方向を読みにくい。エアー圧やペン先の位置にも左右されるようですが、後述のコンプレッサーで使った時は、ハンドピースの軸線上よりやや上向きに出る印象があります。
 使う前にはあらかじめ試し吹きして、塗料の出方を確認しておくと良さそうです。
使う前にはあらかじめ試し吹きして、塗料の出方を確認しておくと良さそうです。
総じて、「細かい調色に関心が薄く、出来合いの色で満足できる」「後片付けなどのアガらない作業にあまり時間を使いたくない、多少お金はかかっても"塗装"というアガる作業の方に時間を使いたい、お金で時間を買うのをそれほど厭わない」タイプの人向けのツールのように感じました。自分にはまさにピッタリです。
ガンダムマーカーエアブラシシステムのハンドピースはシングルアクション(エアーの出方の調整だけはできて、塗料の出方の調整はできない)なので、細かい調整はできない欠点もありますが、指先での微調整は神経を使いそうなので、自分はとりあえずこれで満足しています。
ただ、個体差なのか僕の物はボタンの戻りが悪く、押し込んだボタンが戻らずそのままになってしまうことが多いです。今のところは、箸を使うときのような持ち方でつまんでボタンを上下させる感じで乗り切っています
あと、マーカーかどうかに関わらず、エアー缶を使う場合には宿命として「連続使用できない」「(塗る面積次第ですが)缶1本でプラモ1体を塗りきれない」という問題もあります。
使い続けると気化熱が奪われるため缶が冷たくなっていき、エアーの圧も下がってきます。そのまま無理矢理使い続けてみたところ、自分の場合はハンドピースまで結露してしまって、ハンドピースの先から水が吹き出てしまいました。それはさすがにやりすぎとしても、あまりに早くエアー圧が下がるため、全塗装をするには頻繁に休憩が必要になります。
また、そうして休み休み使っていても、先のエアブラシシステム一式に付属している190㎖缶では、プラモ1体分を全塗装するには容量が全然足りませんでした。自分の感触では、複数色の塗り分けをするのには1体につき3~4本くらい欲しくなる気がしました。より大容量の缶なら2本くらいあれば十分そうですが、プラモ1体につきエアーに2000円と思うと、さすがにお金かかりすぎです。
幸い、今は5000円前後で使える小型の充電式エアーコンプレッサーが色々と出回っています(どうやらネイルアートなどに使われる想定の製品のようです)。僕はガンダムマーカーエアブラシシステムで使える複数機種の紹介記事を参考に、スペック上のエアー圧が高めだったS-POWERという製品を選びました。
SOUL POWER USB充電式エアブラシ Model-03 NEO ダブルアクション 予備用電池付き 0.3mm DIY
エアー缶が付いてくるセットのガンダムマーカーエアブラシシステムには、コンプレッサーと接続するための変換ジョイントが無いため、それも追加で買いました。ガンダムマーカー用のハンドピース単体で買うと、これと同じ変換ジョイントが付いてくるらしいので、最初からコンプレッサーで使うことが確定してるなら、そちらを買った方が良いようです。
Mr.ジョイント3点セット (エアブラシ系アクセサリー) PS241 シルバー
所感は以下の通りです。
- エアコンプレッサーというと「うるさい物だ」と聞いていましたが、この製品の動作音はヒゲ剃りよりより静かなくらいでした。Amazonの商品レビューの動画ほか、検索すると使用中の様子の動画がいっぱい見つかるので、買う前に実際に見てみるといいと思います。
- この製品にはバッテリーが2つ付いてくるので、「マーカーの交換時や塗装後の様子見などの間も電源入れっぱなし」「電池切れで動かなくなったら、もう1つのバッテリーに交換しつつさっきまで使っていた物を充電開始」という使い方ができて、ものぐさな自分としては非常にありがたいです。
コンプレッサー本体はジュースの缶程度の大きさなので、僕は棒付きのクリップなどとまとめて1つの箱に収納しています。
ということで、ガンダムマーカーエアブラシシステムすごく良かったという話でした。積みプラはこの後まだガンヘッドとHGUC GP03があるのと、FRONT MISSION STRUCTURE ARTS Vol.2も出るらしいので、このエアブラシ(とコンプレッサー)にはまだまだ活躍してもらえそうです。
ある程度の出費を厭わない人向けと書きましたが、ファントムグレー1色のためにジオン軍6色セットを毎回買うというのはさすがに無しかな……というくらいのケチさの僕としては、ファントムグレーが空になった後をどうするかが悩み所です。
一応、コンプレッサーに付属のハンドピースは普通の塗料が普通に使えるので、ガンダムカラーのファントムグレーを自分で希釈して使えばいいんですが、前述したような「マーカーならではの手軽さ」を得られないのが気がかりです。
検索してみたところ、ガンダムマーカーの軸は、先端のパーツを反時計回りにひねると機構部分を取り外せるという情報が出てきて、実際やってみたら、そこから塗料を補充できそうな雰囲気でした。ということで、いよいよ空になったら駄目元で、ガンダムカラーを希釈した物をここに入れて使えるか試してみよう、と思っています。
FRONT MISSION STRUCTURE ARTS Vol.1 1/72 ゼニス、ギザ、ドレーグ、ナムスカル - Dec 31, 2020
今月は積みプラ消化月間にしようと決めて消化した3体目から6体目、FRONT MISSION STRUCTURE ARTS Vol.1です。13日にナムスカルから着手して、31日にドレーグまで組み上がったことで、年内に4体間に合いました。

自分はフロントミッションシリーズは初代のSFC版しかプレイしていないのですが、ヴァンツァーといえば、ドット絵や当時の攻略本に載っていたイラストでのずんぐりしたイメージイメージがずっとありました。でも、公式の作例や説明書のイラストはなんだかヒョロッとしてる印象で……

と思ってたんですが、膝を曲げて腰を落としたポーズを取らせてみたら、思ってた以上に当時のドット絵を彷彿とさせるカタマリ感が出るじゃないですか。

ということで、ここから先の写真は全部中腰でお送りいたします。
1体目、ゼニス。右手武器は初回生産限定のツィーゲです。

機体色はガンダムグレー、各部はガンメタをガンダムマーカーエアブラシシステムで塗りました。ガンメタ部の塗り分けは、上手くマスキングできる自信が無かったので、一部簡略化しています。上腕は公式の作例では機体色になっていますが、SFC版当時のデザインでは肩からフレームで前腕がぶら下がってるような見え方だったと思うので、フレームのつもりで、ポリキャップの色に近いファントムグレーにしました。

プラモではゴーグル型の目になってますが、SFC版当時の攻略本のイラストや横山宏氏の作例などでは「頭の横に黒い丸い目があって、赤いラインが真ん中に走っている」デザインだったように記憶しています。ということで、そんな感じに見えるように改造しました。(フェイスはゴーグル部分をカットして角度を変えて接着、目はランナータグから削り出した目を接着。赤いラインはHGUCセカンドVのシールの余りを細切りして貼り付けた。)

また、目と合わせて自分の中でゼニスのビジュアルアイデンティティだった要素として、肩のラインもありました。凹凸がめちゃめちゃあって大変でしたが、頑張ってマスキングして塗り分けてみました。ゲーム中では機体色に応じてラインの色が変わり、白ではなく黄色になる事が多かった気がしますが、ガンダムグレーで塗ってみたら結構濃いグレーになったので、まあ白でもいいかな、と。

ゲームの中では、クォータービューで斜め後ろから見ることが多かったですね。そうそう、こんな感じだった……
2体目、ギザ。

機体色は成形色そのままのサンドイエローで、各部をガンメタで部分塗装しました。シールドは、本来は腕のハードポイントに直接付けるようですが、1stでは肩に装備しているように描写されていたので、ユーティリティを使って肩からぶら下げてみました。

3体目、ドレーグ。

まったく馴染みがない上になんだかデザインの文法が僕の知ってるヴァンツァーと違う……と思ったんですが、フロントミッション3からの登場機体とのことで、初代プレステの性能で描画しやすいようなポリゴンポリゴンしたデザインになったということなんですかね?

この中で最後に作ったので、マスキングの要領が掴めてきていたため、こいつはなるべく公式の作例と同じように塗り分けてみてます。本体色は、公式の作例に近い色が見当たらなかったので、ガンダムメカグレーを使いました。
4体目、ナムスカル。

これもまったく馴染みがない機体ですが、調べてみたら初代のリメイク版での追加機体だったんですね。デザインの文法がドレーグほどはかけ離れていないのも納得です。

こいつだけ全身をマーカー直塗りで塗装したので、色がものすごくまだらな感じになってしまいました。
いずれも「成形色の所にガンダムマーカー墨入れ用流し込みタイプの茶色で墨入れ」→「ガンダムマーカー(直塗り/エアブラシ)で塗装」という順番で塗っていて、全塗装後の墨入れはしていませんが、塗料が回りきらなかった所にうっすらと墨入れの色が残って見える感じで、意外といい感じの効果を得られたのでは?と自分では思っています。
複数あるとゲーム画面の再現をやってみたくなるわけですが、
Duel Lv1
— Piro/Linuxコマンド操作解説マンガ連載中 (@piro_or) December 26, 2020
ーーーーーーーーー
[BODY]
ARM L
ARM R
LEGS
(NO DUEL)
二つできると戦闘画面ごっこがはかどりますね pic.twitter.com/x0gNEAltA8
SFC版のクォータービュー戦闘画面を再現するには、背景紙代わりのライオンボードのサイズがキツイです。なので代わりに、「実際ヴァンツァーのいる戦場ではこんな風に見ることになるのかな」というイメージで、
First

(Miss)
Duel
- BODY
- ARM L
- ARM R
- LEGS
- (NO DUEL)

良い……
ご覧の通り4機ともそれぞれ違う感じに塗り分けましたが、これを実行できたのは、ひとえにガンダムマーカーエアブラシシステムのお陰でした。時々しかプラモを作らなくて、ガンダムマーカーの色の範囲で事足りる僕にとっては、ガンダムマーカーエアブラシシステム最高です。
ということで、この後にガンダムマーカーエアブラシシステム良かったよというだけの話を続けようと思っていたのですが、長くなったため別エントリに分けました。
FRONT MISSION STRUCTURE ARTSは、Vol.2としてテラーンとフロストを含む4体が出る予定みたいです。手持ちの色では、ガンダムマーカージオン軍カラー6色セットのザクライトグリーンがテラーンに、シャアレッドがフロストに合いそうかな、と思っています。リリースが待ち遠しいですね。
HMM 1/72 Firefox……じゃなくてFire Fox完成させた - Dec 31, 2020
今月は積みプラ消化月間にしようと決めて消化した2体目、ゾイド HMM Fire Foxです。2013年に予約して、届いて作業を始めたものの、作業を中断したまま数年放置、今月11日に作業を再開して、13日頃には完成していました。

正直、この機体がどういう物かも全く分かっておらず、子供の頃にもゾイドを履修しないまま来たため、自分にとってはこれが初ゾイドです。

簡単フィニッシュどころか、墨入れと部分塗装だけのパチ組みです。ガンダムマーカーの黄色が手元にあったので、スラスターの内側を塗ってみています。

HGUC 1/144 セカンドV作った - Dec 31, 2020
今月は積みプラ消化月間にしようと決めて消化した1体目、HGUC セカンドVです。6日に着手して15日に完成しました。

このポーズを……立体で手元に置いておきたいと思ってからもう26年。悲願が達成されて感慨深いです。

成形色仕上げ部分塗装(ガンダムマーカー墨入れ流し込み用で墨入れして、ダクトの中やハードポイントの溝の中や装甲の裏や全身の丸いモールドををガンダムマーカーのグレーで塗って、BLベタの部分を黒で塗りつぶして、ハードポイントの赤い丸を赤でちまちま塗って、最後につや消しトップコート。目やトサカなどのセンサー部分だけは付属のシールをカットして貼り付けた)。合わせ目も消してないしパーティングラインもそのままです。アンテナとミノフスキードライブ下側の先端保護用の突起だけは除去しました。

いわゆる簡単フィニッシュとはいうものの、元々のキットがものすごく凝った作りになってて、合わせ目は肘関節とビームライフルくらいにしか出ないので、それで全然見栄えします。素晴らしい。ただ、ミノフスキーシールドの裏面ほか目立つ位置に肉抜き穴があったので、そこはランナーのタグ部分を切り出して埋めてみました。
目立つとこだけ穴を埋めることにした。足の裏とウェポンプラットフォームは、まあ見えないからいいかなって…… pic.twitter.com/HUVQe1h35Z
— Piro/Linuxコマンド操作解説マンガ連載中 (@piro_or) December 9, 2020
足の裏は、肉抜き穴が入り組んでてプラ材で埋めるのが大変そうだったのと、どうせ見ないのとで、そのままです。

なお、1枚目の写真は絶対にこの目で見たいポーズではあったのですが、実際にポーズを取らせた物を別角度から見ると

なんかちょっとこう……「えっへん」みたいな感じがあってマヌケっぽく感じてしまったため、棚に飾るにあたってはもう少し脇を締めてもらってます。宙に浮かせるのには、推奨のフライングベースが手に入らなかったため、たまたま余っていたfigmaガイバーⅠ付属のスタンドを流用しました。