Latest topics 近況報告
たまに18歳未満の人や心臓の弱い人にはお勧めできない情報が含まれることもあるかもしれない、甘くなくて酸っぱくてしょっぱいチラシの裏。RSSによる簡単な更新情報を利用したりすると、ハッピーになるかも知れませんしそうでないかも知れません。
 の動向はもえじら組ブログで。
の動向はもえじら組ブログで。
宣伝。日経LinuxにてLinuxの基礎?を紹介する漫画「シス管系女子」を連載させていただいています。
以下の特設サイトにて、単行本まんがでわかるLinux シス管系女子の試し読みが可能!

「シス管系女子」1話から13話までまとめて読める日経Linux 2012年9月号発売中です - Aug 09, 2012
既にご覧になった方もいらっしゃるかとは思いますが、コマンドライン豆知識漫画の「シス管系女子」が連載されている日経Linuxの9月号が8日付けで発売となりました。Amazonでもお買い求め頂けます。
 今回、別冊付録としてシス管系女子の1話から12話までを再録した「シス管系女子まとめ読み」が付いています(代わりにDVD-ROMは無し)。元々の掲載ページ数が少ないので全部で70ページにも満たないいわゆる「薄い本」なのですが、本誌掲載分も合わせると13話を一気読みできます。過去の回を見逃された方・「シス管系女子」ってなんやねん?と気にはなっていたけれども……という方は、是非ご覧下さい!
今回、別冊付録としてシス管系女子の1話から12話までを再録した「シス管系女子まとめ読み」が付いています(代わりにDVD-ROMは無し)。元々の掲載ページ数が少ないので全部で70ページにも満たないいわゆる「薄い本」なのですが、本誌掲載分も合わせると13話を一気読みできます。過去の回を見逃された方・「シス管系女子」ってなんやねん?と気にはなっていたけれども……という方は、是非ご覧下さい!
再録にあたって原稿を見返していると、「描き直したい……!」と思う所ばかりで、古い原稿はほんと見返すもんじゃないなと思いました。1話と2話はみんとちゃんの髪型が3話以降と少しだけ違ってた(3話から変えた)ので、カラー化のついでにそこだけ直しましたけど。
カラー化で思わぬ落とし穴だったのが、スクリーンショットでした。うっかりモノクロに変換した状態の物しか残していなかったので、同じような状況をまた作ってスクリーンショットを撮り直す羽目になってしまい、これがいろんな意味で辛かったです。元ファイルはなるべく残す、というのを怠ってしまった代償は大きかった……
ところで、付録の表紙と本誌掲載の13話(さらに言うとカラー化した1話・2話も)から、制作環境をComicStudio 4にアップグレードしました。コミティアの会場で買ってから半年ほど本棚の肥やしにしてしまってましたが、原稿のカラー化にあたってちょうどいい機会だと思って、頑張って移行してみました。ComicStudio 3から変わっている箇所が結構あって戸惑うことも多いのですが、13話を書き終える頃にはだいぶ慣れてきたような気もします。
あと、アップグレードついでに描画ツールを「鉛筆(ラスター)」から「ペン(ベクター)」に変えました。最初のもえじら組の同人誌で使った時に結構戸惑ったのと、やっぱり線編集に頼るのって邪道かな……という思いと、あと柔らかい線があって、それ以後ベクターのペンツールはずっと避けてしまっていたのですが、表紙に載せるならやっぱり綺麗な線じゃないとガッカリだよねとか、変な所にこだわって無駄に時間かかって汚い絵になるのと、ツールの助けを借りてサクッと綺麗な絵にするのとどっちがいいのかとか、そのへんの事を考えて、昼の仕事と無理なく両立させるためにも読者の皆さんにより良い物をお届けするためにもツールの機能を活かせる所は最大限活かした方がいいだろう……と考えを改めた次第です。
で、実際切り替えてみた感想ですが、いやー、いいですねこれ(手の平返し)。今までは「この線、なんか気に入らない……!」と思ったら消して描き直してという事を何度も何度も繰り返してたのですが、大体こんなもんやろってところで引けたら後は線修正で微調整するという感じで、ずいぶん時間が短縮された気がします。交点削除で髪の毛などの重なりを描きやすくなったのも大きい。あと、グレースケールのラスターレイヤに鉛筆を組み合わせた描き方だとどうしても線に半透明の部分ができてしまって、トーン処理する時に単純な閉領域選択の塗りつぶしだと線の所が逆に色が薄く見えてしまうというようなことが起こってしまっていたのですが、ベクターのペンツールだとパキッと線の色が着くので、単純な塗りつぶしのままでも結構見れる物になるんですね。これも時間短縮につながった気がします。
まとめると、ツールの機能をちゃんと使うと漫画制作は確実に楽になるのだなあとしみじみ実感したという話なのでした。
セッションの復元とツリー構造の維持 - Aug 07, 2012
ツリー型タブを3ヶ月ぶりに更新した。
地味な修正が多い中で特に地味な修正だけど、セッション復元でツリー構造が壊れるという問題について一定の改善を見られたのではないかと思ってる。実際に効果があったのかどうかは、今後同様のバグ報告が減るかどうかで見るしかない。
何故ツリーが壊れるか、という事の前にそもそもツリーが壊れるってどういう事やねん、という話なんだけど、ツリー型タブを使っててごく希に、「リンクから新しい子タブを開いても子タブにならない」とか「親にあたるタブには折り畳みのためのつまみが表示されているのに、子になったはずのタブはインデントされておらず、つまみをクリックしても子になったはずのタブが折り畳まれない」とかそういう怪しい挙動になる事があった。
何故そういう事が起こるのか。これはタブの管理方法に理由がある。
ツリー型タブでは、個々のタブに一意なIDをあらかじめふっておいて、tab.setAttribute(TreeStyleTabService.KPARENT, parentTab.getAttribute(TreeStyleTabService.kID)) とか tab.setAttribute(TreeStyleTabService.kCHILDREN, childTabs.map(function(aChild) { return aChild.getAttribute(TreeStyleTabService.kID); }).join('|')) とかいう感じにIDの文字列をキーにして互いの関係を保持している。親のタブや子のタブを取得する時は、TreeStyleTabService.getParentTab(tab) とした時にその中で tab.getAttribute(TreeStyleTabService.KPARENT) して取得したIDを使って(DOM3 XPathなどで)実際の要素を改めて取得するという風になってる。何故こうしたかというと、
- タブの要素ノードに直接
tab.parentTab = parentTabのようにしてしまうと、うっかり参照を消し忘れたらいつまで経ってもメモリが解放されないんじゃないか、という心配があった。(意図しない事態の発生を防ぐため) - 実際には
setAttribute()するのと同じタイミングでSessionStore.setTabValue(tab, TreeStyleTabService.kPARENT, parentTabId)のようにしてセッションに情報を複製しており、クラッシュ時のツリーの復元などに役立てている。(ツリー構造の永続的な保存のため)
といった理由があってのことだった。
これはそれなりに堅牢なやり方なはずだと思ってたんだけど、実際にできあがってからJavaScriptデバッガでプロファイリングしてみたら、IDの文字列からタブの要素ノードを探すという処理が呼ばれる回数が突出して多くて、それが結構無駄な待ち時間を増やす元になっているらしかった。それで、もう少し高速に動作するような仕組みを後から加える事にした。setAttribute(TreeStyleTabService.kID, id) するのと同じタイミングで、gBrowser.treeStyleTab.tabsHash[id] = tab; としてハッシュテーブルを作っておき、それ以後はそちらだけを参照するという、ごくシンプルな物だ。
上記のおかしな挙動は、このハッシュテーブルが原因だっていた。このハッシュテーブルの仕組みが上手く働くためには、「ハッシュテーブルに入っていないタブはない(すべてのタブがハッシュテーブルで管理されている)」という前提が必要になる。もし万が一何らかの理由でハッシュテーブルの管理から漏れてしまうと、そのタブはAPI経由では永久に見つけられないことになってしまう。そのタブを親として子タブを登録する、という風な事はできるのに、その子タブに保存された情報から親のタブを探そうとしても、ハッシュテーブルに無いタブだから見つけられない。こういう不整合の発生は考慮に入っていなかったので、親子関係に基づくインデント幅の調整などの処理が中途半端な所で止まってしまって、上記のような色々と不可思議な現象が発生していた。
色々調べた結果、大量のタブが一気にセッション復元された時に「現在のタブ」になっていたタブが、このハッシュテーブルの管理から漏れてしまうことがあるようだという事が分かった。なので、そのような場合もちゃんとハッシュテーブルに入るようにした。これによって、手元で再現性100%だったケースについては問題が起こらないようになった。これまでに報告があった全ての問題がこれと同一の原因かどうかは不明だけれども、今までよりは問題が起こりにくくなったという事は言えると思う。
あと似たような問題で、タブの復元のタイミングによっては「ツリー構造だけの高速な復元」ができなくなるという現象も起こっていた。ツリー型タブが完全に初期化されるよりも前にFirefoxのセッション復元の仕組みによってタブが復元されていた、という想定外の状況が発生していて、それで色々な前提が崩れてしまっていた。理屈から言ってなんでそうなるのかがてんで分からなくて、どうにかしてタブが復元されるよりも前のタイミングに割り込みたかったんだけど、どうも無理っぽかったので、既にタブが復元されてしまっていた場合でもちゃんとそれらのタブを「後から初期化」するようにした。
そういう地味な修正ばかりが入っている版です。
Unityのランチャーに沢山Firefoxの項目を追加する代わりにサブコマンド?にした - Jul 29, 2012
複数のプロファイル、複数のバージョンを検証用に用意しないといけなくて、簡単に使い分けられるような環境を作る必要があるのです。
- Unityのランチャー上にある「Firefox ウェブ・ブラウザ」を右クリックして、「ランチャーに常に表示」のチェックを外す。
/usr/share/applications/firefox-custom.desktopとして以下の内容でファイルを作成する。
[Desktop Entry] Version=1.0 Name=Firefox Web Browser (custom) Name[ja]=Firefox ウェブ・ブラウザ (custom) Comment[ja]=ウェブを閲覧します GenericName=Web Browser GenericName[ja]=ウェブ・ブラウザ Exec=firefox %u Terminal=false X-MultipleArgs=false Type=Application Icon=firefox Categories=GNOME;GTK;Network;WebBrowser; MimeType=text/html;text/xml;application/xhtml+xml;application/xml;application/rss+xml;application/rdf+xml;image/gif;image/jpeg;image/png;x-scheme-handler/http;x-scheme-handler/https;x-scheme-handler/ftp;x-scheme-handler/chrome;video/webm;application/x-xpinstall; StartupWMClass=Firefox StartupNotify=true X-Ayatana-Desktop-Shortcuts=NewWindow;Sub;ESR;Stable;Beta;Nightly; [NewWindow Shortcut Group] Name=Open a New Window Name[ja]=新しいウィンドウを開く Exec=firefox -new-window TargetEnvironment=Unity [Sub Shortcut Group] Name=Sub Exec=firefox -no-remote -p sub TargetEnvironment=Unity [ESR Shortcut Group] Name=ESR Exec=/home/piro/opt/firefox-esr/firefox -no-remote -p esr TargetEnvironment=Unity [Stable Shortcut Group] Name=Stable Exec=/home/piro/opt/firefox-stable/firefox -no-remote -p stable TargetEnvironment=Unity [Beta Shortcut Group] Name=Beta Exec=/home/piro/opt/firefox-beta/firefox -no-remote -p beta TargetEnvironment=Unity [Nightly Shortcut Group] Name=Nightly Exec=/home/piro/opt/firefox-trunk/firefox -no-remote -p trunk TargetEnvironment=Unity- ファイルに実行権限を設定する。
- Dashホームから「Firefox ウェブ・ブラウザ(custom)」を探して、実行する。
- ランチャーに表示されたアイコンを右クリックして「ランチャーに常に表示」にチェックを入れる。
これで、アイコンを右クリックして各プロファイルで起動できるようになった。
ユーザのホーム以下にファイルを作成して複数のアイコンを登録してみたりとか色々試みてたんだけど、自分で付けた名前と表示名が一致しないとか色々動作が怪しくて、結局このような所(グローバルな設定ファイルとして作成)に落ち着いた。
2014年8月21日追記。Ubuntu 14.04LTSで、Thunderbird用の物も作った。
[Desktop Entry]
Encoding=UTF-8
Name=Thunderbird Mail (custom)
Name[ja]=Thunderbird電子メールクライアント (custom)
Comment=Send and receive mail with Thunderbird
Comment[ja]=メールの読み書き
GenericName=Mail Client
GenericName[ja]=電子メールクライアント
Keywords=Email;E-mail;Newsgroup;Feed;RSS
Keywords[ja]=Eメール;イーメール;mail;e-mail;email;メール;電子メール;ニュースグループ;ネットニュース;RSS;フ>ィードリーダー;書く;読む;Mozilla
Exec=thunderbird %u
Terminal=false
X-MultipleArgs=false
Type=Application
Icon=thunderbird
Categories=Application;Network;Email;
MimeType=x-scheme-handler/mailto;application/x-xpinstall;
StartupNotify=true
Actions=Compose;Contacts;AnotherProfile
[Desktop Action Compose]
Name=Compose New Message
Name[ja]=新しいメッセージの作成
Exec=thunderbird -compose
OnlyShowIn=Messaging Menu;Unity;
[Desktop Action Contacts]
Name=Contacts
Name[ja]=連絡先
Exec=thunderbird -addressbook
OnlyShowIn=Messaging Menu;Unity;
[Desktop Action AnotherProfile]
Name=Start with Another Profile
Exec=thunderbird -no-remote -p sub
OnlyShowIn=Messaging Menu;Unity;
Firefoxの物を作った時と微妙に様式が変わっているようだ。
Ubuntuでのgeditとvimの初期設定 - Jul 23, 2012
自分がGNOME3ベースの環境でgeditを使う時に最低限これだけはやっとくという設定。
- タブ幅4、自動バックアップなし。
- フォントはシステムフォントではなくIPAゴシックあたりをダイレクトに指定(これは必要ないか?)
- シンタックスハイライトで太字にならないようにする。 /usr/share/gtksourceview-3.0/styles/classic.xmlをclassic-nobold.xmlとかなんとかいう名前でコピーして、vimで開いて:%s/ bold="true"//して、スタイルの名前を書き換えて上書き保存して、geditの設定で色のスキームの欄からファイルを選択して一覧に追加して選択する。 ( Gedit の色設定。 - 研究日誌。のやり方に従った)
- エンコーディング自動判別用の設定を日本語環境向けに変更する。 gsettings set org.gnome.gedit.preferences.encodings auto-detected "['UTF-8','CURRENT','SHIFT_JIS','EUC-JP','ISO-2022-JP','UTF-16']"で、自動判別がまともに動くようになる。 (geditの文字化けを解消する (GNOME3) - 憩いの場のやり方に従った)
- プラグインを入れる。設置場所は ~/.local/share/gedit/plugins/ 以下(GNOME2の頃に書かれたような古いドキュメントでは ~/.gnome2/gedit/plugins/ 以下に置くように書いてあるけど、GNOME3では .local 以下に置くようになってる)。
- Regex Search and Replace(正規表現での検索と置換を可能にする): Gedit/Plugins - GNOME Live!の「Regular Expression Plugin」の所からダウンロードできる。
あと、vimの設定も。というか、Ubuntuの方の設定なんだけど。
- sudo apt-get install vimでインストール。
- sudo update-alternatives --config editorで設定のリストが出るので「vim.basic」を選択する。
vimを使っているのは、nanoはGNOME標準のキーバインドとも何とも異なるワケ分からない操作体系のようなので、それよりはまだlessとかと操作が共通している部分が多いvimの方がマシ……という判断による。
ページ内の見出し一覧をMarkdownのリスト形式で出力するbookmarklet - Jul 05, 2012
前に似たような事をやった気がするけど。
javascript:
var tab = ' ',
min = prompt('Input minimum level of the headings (default=1)');
function tabs(n) {
var ret = [];
for (var i = 0; i < n; i++) ret.push(tab);
return ret.join('');
};
function collectHeadings(minLevel) {
var rawHeadings = document.querySelectorAll('h1, h2, h3, h4, h5, h6');
var headings = [];
var heading, node;
for (var i = 0, maxi = rawHeadings.length; i < maxi; i++)
{
node = rawHeadings[i];
heading = {
node: node,
id: node.id,
label: node.textContent,
level: parseInt(node.localName.charAt(1))
};
if (heading.level >= min)
headings.push(heading);
}
return headings;
}
function generateList(headings) {
var list = [],
h,
id,
item,
nest = 0;
for (var i = 0; i < headings.length; i++)
{
h = headings[i];
id = h.id || h.node.parentNode.id || h.node.parentNode.parentNode.id;
item = (id) ? '['+h.label+'](#'+id+')' : h.label ;
if (i > 0) {
if (h.level > headings[i-1].level) {
nest += 1;
} else if (h.level < headings[i-1].level) {
nest -= 1;
}
}
if (nest == 0) {
list.push(' * '+item+'\n');
} else {
list.push(tabs(nest)+'* ' + item + '\n');
}
}
return list.join('');
}
var headings = collectHeadings(Math.max(1, min));
var list = generateList(headings);
if (list) window.open('data:text/plain,'+encodeURIComponent(list));
見出しレベルの関係がちゃんとしてないとうまく動かない。あとsection/headingのネストには対応してない。
結婚しました - Jul 03, 2012
一部の方や会社では報告済みですが、結婚しました。お相手は一般人の女性です……というと芸能人っぽくてウケるかなと思いましたが寒いだけでした。ともかく、誰と結婚したのかという情報は諸事情により今の所完全公開にはしたくないというのが両名の意向ですので、両名をご存じの皆様方におかれましては、ブコメやらTweetやらで二人の名前を併記して「おめでとう」とウッカリ発言してしまわれることのないように、何卒ヨロシクお願い致します。
時間外受け付けに書類を提出して、ちゃんと受理されるかどうかドキドキハラハラだった(指輪に「婚姻届の提出日」ということで日付を入れてしまった以上、手続きやり直しなんて事になったら、後で指輪を見返した時に「この日付なんなの」ってなってしまう……)のですが、昼間に住民票を取りに行ったらちゃんと受理されてました。よかったです。
で、結婚にあたって姓を妻側にしたのですが、特に社会人になって以降は「下田」と呼ばれる機会よりも「ぴろたん」と呼ばれる機会の方が圧倒的に多かったため、いまいち実感が湧きません。早速免許の訂正の手続きに行ってみたら、窓口で新しい苗字で呼ばれて一瞬「あー誰か呼ばれてるな」って思ってしまいました。慣れるまで時間がかかりそうです。
ところで、姓を妻側にするというと婿入りなのかとかなんとか色々思われるようなのですが、単に姓が妻側になっただけで、それ以上のことは何も無いです。といっても知らない人にはよくわからないと思うので、姓を妻側に変更するとはどういう事なのか?を簡単に解説してみたいと思います。ポイントは以下の3点です。
- 姓を妻側にする、とはどういう事なのか?
- 姓を妻側にする事と、婿養子と、婿入りとはどう違うのか?
- 本籍地はどこになるのか? どこにするべきなのか?
まず戸籍というのは、代表者にあたる筆頭者および他のメンバーからなる家族を1つのユニットとした単位で存在しています。大抵の場合は、両親+その子供というセットになっています。
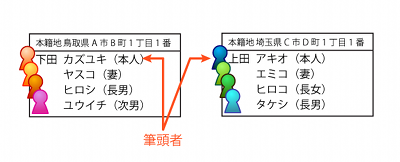
さて、ここで下田家の長男と上田家の長女が結婚するとします。この時、新しいユニットが誕生することになって、それ用の戸籍が新たに作られます。新しく作成された戸籍には、各人のメタ情報として元の戸籍への参照が付与されます。また、古い戸籍にあるその人の情報には「除籍(この人の情報はこの戸籍ではもう管理されていない)」というタグが付き、新しい戸籍への参照が付与されます。
このようにして戸籍と戸籍が相互リンクされるため、例えば下田カズユキさんやヒロシ君が死んだ時には、遺産を相続できる人がどれだけいるんだ?という事を辿っていって調べられるわけです。
この時決めないといけないのが、新戸籍の「筆頭者」と「本籍地」の2点です。
筆頭者とは、文字通り、その戸籍の最初に名前が書かれてる人の事です。新戸籍に記載される人達の姓は、筆頭者の姓になります。つまり、夫の姓を名乗りたければ夫が筆頭者になるし、妻の姓を名乗りたければ妻が筆頭者になります。はい、僕の場合はそういうわけなので、戸籍上は妻が筆頭者になっています。
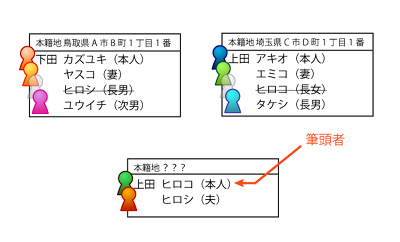
新しく作る戸籍で誰の名前を最初に書くのかを決めなくてはならなくて、その時選んだ方の人の姓が、新戸籍に属してる人全員の姓になる。制度上は、ただそれだけ。「夫の姓になったんだから妻は夫の一族の一員になったのだ」とか、「妻の姓になったんだから夫は実家を捨てて妻の家に尽くさねばならないのだ」とか、言うのは勝手ですが、それは制度とは何も関係のない話だということです。
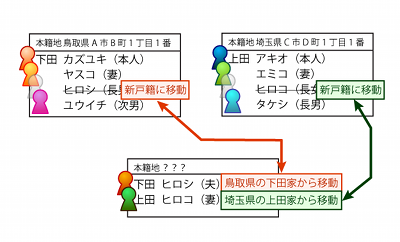
他方、婿養子の場合は、戸籍同士の関係がちょっと違います。
まずヒロシ君と上田アキオさんの養子縁組手続きをして、ヒロシ君が上田家の養子になります。この時、元の下田家の戸籍からはヒロシ君は除籍されます。
次に、ヒロシ君とヒロコさんで結婚して(※養子と実子は結婚できます)新しい戸籍を作ります。
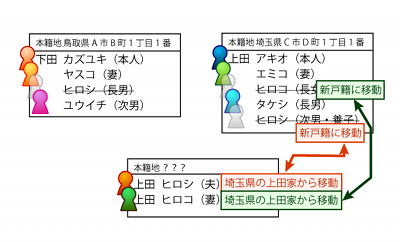
この時、ヒロシ君は既に上田姓になっていますし、ヒロコさんも当然上田姓なので、どっちが筆頭者になっても新戸籍の姓は上田になります。よって、ヒロシ君はどっちみち、もう下田姓を名乗ることはできません。
ヒロシ君とアキオさんの間には養子・養父としての法的な親子関係もあります。なので、ヒロシ君にとってアキオさんは「義理の父」ではなく「養父」ということになります。「実子の配偶者」ではなく「養子」として、遺産の相続等、実子と同等の権利があるわけです。
これがいわゆる婿養子です。なお、実際には養子縁組と婚姻の手続きはどっちを先にやってもいいそうです。ここでは説明が簡単な方ということで、養子縁組後に婚姻する場合を説明しました。
婿入りというのは、これら制度上のやり取りとは関係のない慣習的な言葉です。かつての制度やしきたりを現在の制度に照らし合わせると、上記の「婿養子」に近いものを指していたっぽいです。ということで、僕が婿入りという言葉を使う時は、婿養子と同じ物を指していると思って下さい。(もっと言うと、「婿養子」も慣習的な言葉で、制度上はただの「妻の実家の養子になっている」という状態です)
ちなみに、法律の用語における入籍とは、上記の養子縁組手続きにおいて夫が妻の実家の戸籍に入る、あるいは妻が夫の実家の戸籍に入る事を言うそうです。なので、僕のケースは入籍にはあたらないわけです。「結婚」のもってまわった言い回しとして「入籍」を使うという風潮があります(この用法は俗語として一般的なので、最近は辞書にも載ってるみたいです……)が、そういうわけなので、僕は入籍という表現は意地でも使わないでおきます。
最後に、ここまであえて触れずにいましたが、本籍地についても説明します。
昔は戸籍と住民票が一体だったとかで、戸籍は住所ベースの管理になっていますが、戸籍と住民票が別々になっている現在では、本籍地とは単に「戸籍を管理する自治体がどこなのかを示す」という事以上の意味は無いそうです。居住地と無関係に決められるので、夫側実家と同じ本籍地にしてもいいし、妻側実家と同じにしてもいいし、千代田区1の1で皇居を本籍地にしてもいい(戸籍を取り寄せる時は千代田区の区役所に行く)し、スカイツリーでも屋久島でもなんでもオッケーです。
よく「本籍地はどっちかの実家と同じにしておいた方がいい」という話がありますが、これは、単に「管理する自治体が1箇所にまとまっていれば、手続きや戸籍の取り寄せがちょっとだけ楽になる」「本籍地が変わらない方の人は、本籍地が関係している登録を更新しなくて良い」というだけのことです。
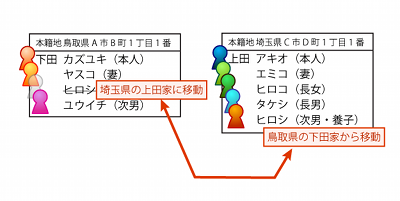
仮に東京都E区の住所で新戸籍を作ったとすると、ヒロシ君が死んだ時は、東京都E区と鳥取県A市のそれぞれから戸籍を取り寄せることになりますし、ヒロコさんが死んだ場合、東京都E区と埼玉県C市の2箇所の自治体から戸籍を取り寄せることになります。これがニュートラルな状態です。
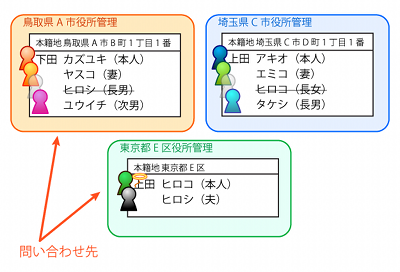
埼玉県の上田家の本籍地と同じ本籍地で新戸籍を作った場合、ヒロコさんが現在属している戸籍と、過去に属していた戸籍は、2つとも埼玉県C市の役所が管理しています。なので、ヒロコさんが死んだ時であれば埼玉県C市の役所からだけ戸籍を取り寄せればOKです。でも、ヒロシ君が死んだ時は、埼玉県C市と鳥取県A市の両方から戸籍を取り寄せないといけません。二人のうち片方だけは楽になりますが、もう片方はニュートラルな状態と何ら変わりません。

また、運転免許のように本籍地の情報がある登録情報は、本籍地が変わったら更新する必要があります。上記のように「上田家の本籍地と同じ本籍地に新戸籍を作った」場合、ヒロコさんは名前も本籍地も変わらないので免許は更新しないでオッケーです。それに対して、ヒロシ君の方は名前も本籍地も変わるので(どっちか一方だけ変わった場合もですが)免許を更新しないといけません。
僕の場合、夫側実家の本籍地で妻側の姓ってなんか違和感あるなーと思ったのと、妻側実家の本籍地で妻側の姓だとちょっと婿入りっぽ過ぎるかなーと思ったのと、いろんな意味でちゃんと独立したいなあ一人前になりたいなあという思いとで、心機一転するつもりで本籍地は敢えて既存のどちらでもない場所にしました。
どちらの実家も苗字については特に拘りは無い(家を継ぐとかそういうのは無い)ということだったので、姓については当人同士の意志でわりとすんなり決まりました。
というか、僕の元の苗字「下田」がぶっちゃけダサイというかショボいというか、敢えてこの苗字になろうという気が湧くようなものでもなく、僕自身苗字を変えられる物ならもっと格好いい苗字だったらよかったのに!と思っていたくらいだったし、妻さんにも「『下田』になるのはちょっと……」と言われてしまったしで、満場一致で妻側の姓という感じでした。
姓が変わることで色々大変なのかなーと思っていたのですが、実際なってみると、引っ越しとそれに伴う住所変更の時と気分はそんなに変わらないなあ……という感じです。事前にしなきゃいけない事なんて、元の戸籍を取り寄せて婚姻届の枠の中を埋めておくという事だけだったし。むしろ引っ越しより楽なくらいじゃないの?
元々、住所変更すら完璧にはこなしてなかった(郵便物の転送期限が過ぎて実家に連絡が行ってそれでやっと情報を更新したとかそんなのもあった)人間なので、結婚だからって気張って完璧に手続きを済ませられるわけがないのであります。なので、気がついた物からボチボチ名前を変えていこうと思っています。
……という風に思えるのは、戸籍上の名前イコール自分のアイデンティティ、という考え方をしていないからなのかもしれませんね。
僕は16で漫研に入った時にペンネームを決めて(先輩に決めてもらって)以降、13年間ずっと「Piro」の名義で色々な活動をしてきました。物心ついてから、という考え方をすれば「Piro」であった期間の方が長いくらいです。どっちかがシンボリックリンクでどっちかが本当の名前だ、というのではなく、どっちも等しくハードリンクという感覚だと思います。
よく「インターネットは仮想現実。ハンドルという仮名で、嘘の人格を装って交流する場所。そんなものにハマってないで、もっと現実を見ろ。」みたいな言い方をされるけれども、僕にとってはネットも現実の一部です。「現実」と、そこから切り離れた「非現実」があるのではなくて、ネットというインフラの上に「現実」が延長されている、そういう感じなので、僕はオフラインでもPiroという名前を使いますし、オンラインでも下田洋志という名前を使ってきました。名前毎に異なるペルソナを使い分ける、という事をしていない(つもり)のですよね。むしろ、ペルソナは名前よりも場(家だとか客先だとか)の方に結び付いている気がします。
名前が一つしか無かったら、名前が変わる事への抵抗はもっと強かったかもしれません。姓が変わった後でも変わらない、自分を自分でアイデンティファイする永続的な名前を持っていたから、それほど強い抵抗を感じずに済んだ、というのはやっぱりあるんじゃないかなと思います。それが良い事(制度に縛られない自由な感覚が養われたということ)なのか悪い事(伝統を蔑ろにすること、制度に順応「できていない」ということ、在る物に合わせるのを怠っているということ)なのかは分かりませんが。
以上、結婚のご報告でした。
漫画、連載 - Jul 02, 2012
「描かないマンガ家」の3巻で、マンガ家デビューを目指す若手が3話連載のチャンスをもらって、好評なら長期連載ということだったんだけど不評で予定通り3話でおしまいになって、長期連載になるチャンスを逃して涙する、という話があって、見てていたたまれなくなった……
日経Linuxで連載中のシス管系女子も、実は当初はとりあえず3回くらいでっていうことで話をもらってて、3話目の最後に「つづく」って入れていいのか良くないのか(っていうか話的にちゃんときりのいい所で終わらせなきゃなんじゃないのかとか)悩んでたりしたんだけど、なんか特にそこを突っ込まれることもなく4話5話と続いて、今に至ってる。それでもうすぐ1周年ですよ。感慨深い。
でもそれはあくまで技術系の雑誌(専門誌?)の連載「記事」としての評価なのであって、「雑誌の連載漫画作品」というのとはまたちょっと違うのかな-、と思う所もある。画力も話作り(技術解説の部分ではない、エンタテインメントとしての部分)も取り立てて優れているわけではない……というか、むしろ下手な方だと思うし。そこら辺、純粋に画力や話作りで勝負する「漫画業界」に比べるとずいぶんユルく甘やかされてるんだと思う。「描かないマンガ家」「バクマン」等のマンガ家漫画を見てると、こんなんで連載やらせてもらってるのが忍びないです。
という事に引け目を感じるくらいなら、上達することに一生懸命になれよって話ですよね……
シス管系女子 第11話「システムの負荷を把握しよう」 - Jun 18, 2012
発売から少し経ってしまってますが、日経Linuxにて連載中のコマンドライン系豆知識漫画「シス管系女子」の第11話が掲載されている日経Linux 2012年7月号が発売されています。
 今回はtopの紹介のつもりで始めたのですが、成り行きでload averageとkillについても説明してしまいました。
今回はtopの紹介のつもりで始めたのですが、成り行きでload averageとkillについても説明してしまいました。
ところで、日経BP記事検索サービスを今見てみたら、10話だけでなく11話も単品でご覧頂けるようになってました。シス管系女子だけ見てみたい!という方はこういう手もありますよということで……(PDFのダウンロード購入ではなく、オンラインビューワで見る形式だそうですが)
今回が11話という事は、次回は連載12回目で、ついに1周年ですね。まぁ、何か特別な事をやるわけでもなく、普通に11話の続きでtopとload averageの話の補足をやるつもりなのですけれども。
そういえば、ネタのチョイスについては特に指示があるわけでなく、ある程度普遍的な話題であればOKという枠だけ示していただいていて、毎回僕の方でとりあげたいネタを好き勝手に考えています。もし「こういうのもやってくれ!」というご要望がございましたら、コメント等で是非ともお寄せいただけましたら幸いです(本誌のアンケート葉書ならなお良し)!
JSDeferred - Why this code doesn't work? - Jun 12, 2012
I got a mail.
I've started to use jsdeferred 2 days ago and I'm really really happy with it because I consider it's really easy to use, light and it looks very powerfull. Anyway, I have one little doubt I hope you can help me about.
Here's the thing, I would like to deferredize some functions to use in some chains, but I haven't figured out what's the best way to get it, I put you a little example
If I try something basic like this:
function my_deferred(data) { var deferred = new Deferred(); deferred.call(data); return deferred; } function main() { Deferred.define(); my_deferred("foo"). next(function(data) { console.log(data); }); }The chain is not executed (I don't know why). But if I change to something like this, using setTimeout, it works:
function my_deferred(data) { var deferred = new Deferred(); setTimeout(function() { deferred.call(data); },1); return deferred; } function main() { Deferred.define(); my_deferred("foo"). next(function(data) { console.log(data); }); }The question is, wouldn't it be possible to get the right behaviour of the chain without using setTimeout? I would like to deferredize some functions without the penalty of using setTimeout.
You should use Deferred.next() ( it is available as a global function
next() if you use Deferred.define() ) instead of setTimeout(), like:
function my_deferred(data) {
var deferred = new Deferred();
Deferred.next(function() {
deferred.call(data);
});
return deferred;
}
Deferred.next() works just like setTimeout(), but in most cases it works
faster than setTimeout().
deferred.call() just calls the next job which is registered as a
callback function given to its .next() method. So, you have to call
deferred.call() after you register the next job.
However, In your case, any "next job" has not been registered yet when
you call deferred.call(). As the result, the "next job" registered after
deferred.call() was called won't be called by anyone.
function my_deferred(data) {
// (3) Now, we are in this function.
var deferred=new Deferred();
deferred.call(data); // (4) deferred.call() is called, then
// the next job ( registered via
// deferred.next() ) is also called.
// However, it has not been registered yet.
// As the result, nothing happens.
return deferred; // (5) We return the deferred object and
// exit from this function.
}
function main() {
// (1) Starting position of this event loop.
Deferred.define();
// (2) The function is called.
my_deferred("foo").
next(function(data) {
// We never come here!!
console.log(data);
}); // (6) You register the next job to the returned deferred
// object, via its next() method. However, because
// deferred.call() was already called, the job will
// never be called by anyone.
// (7) End of this event loop.
}
Instead,
function my_deferred(data) {
// (3) Now, we are in this function.
var deferred=new Deferred();
Deferred.next() {
// (8) Now, the next event loop is started.
deferred.call(data); // (9) deferred.call() is called, then
// the registered next job is also called.
}); // (4) We just reserve the task for the next event loop.
return deferred; // (5) We return the deferred object and
// exit from this function.
}
function main() {
// (1) Starting position of this event loop.
Deferred.define();
// (2) The function is called.
my_deferred("foo").
next(function(data) {
// (10) We are here!
console.log(data);
}); // (6) You register the next job to the returned object.
// (7) End of this event loop.
}
As above, you must register the next job to the deferred object before its call() is called.
ちょよんごさんによると、このメールの送り主の人(ここでは省いたけど、WebGL用のスクリプトを書いてるそうです)は、JSDeferredを使ってるとおぼしき開発者に手当たり次第質問を投げてるらしい。そんなこととはつゆ知らず「僕作者じゃないんだけどなあ」と呑気にちょよんごさんに転送してしまって、余計なストレスをかけてしまったようなので罪滅ぼしと思って真面目に返信してみた。伝わってるかどうかは分かんないけど。
これはJSDeferredの結構典型的なハマリ所だと思う。XMLHttpRequestとかNode.jsの非同期なメソッドみたいに、コールバック関数が必ず次以降のイベントループで呼ばれる物に対してであれば、このメールの送り主の人が書いてるような
var Deferred = require('jsdeferred').Deferred;
var fs = require('fs');
function statDeferred(filePath) {
var deferred = new Deferred();
fs.stat(filePath, function(error, stats) {
if (error)
deferred.fail(error);
else
deferred.call(stats);
});
return deferred;
}
statDeferred('/tmp/foobar')
.next(function(stats) {
if (stats.isDirectory()) {
...
}
});
こういう流れの書き方で何も問題ない。
問題は、やらせたい処理が同期的であった場合で、
function statDeferred(filePath) {
var deferred = new Deferred();
try {
var stats = fs.statSync(filePath);
deferred.call(stats);
} catch(error) {
deferred.fail(error);
}
return deferred;
}
これでは動かないのですよね。
何故かというと、 deferred.call() は「その deferred の next() に渡された関数、という形で あらかじめ 登録されていた『次のジョブ』を実行する」物だから。
この例だと statDeferred() が deferred を return する前に deferred.call() を呼んでしまっているから、その後で次のジョブを登録しても、登録した「次のジョブ」を呼ぶ人が誰もいないわけです。
function statDeferred(filePath) {
// (2) 関数の中に入った。
var deferred = new Deferred();
try {
var stats = fs.statSync(filePath); // (3) 処理を実行した。
deferred.call(stats); // (4) 登録済みの「次のジョブ」を実行しよう……
// とするんだけど、まだ何も登録されてないので、
// 当然何も起こらない。
} catch(error) {
deferred.fail(error);
}
return deferred; // (5) 関数を抜けた。
}
// (1) 今のイベントループでのスタート地点。
statDeferred('/tmp/foobar')
.next(function(stats) {
// 「次のジョブ」の登録後に deferred.call() が呼ばれないので、ここには到達しない。
if (stats.isDirectory()) {
...
}
}); // (6) 戻り値の next() を呼んで、「次のジョブ」を登録した(今更)。
// (7) 今のイベントループの終わり。
だから、 setTimeout() なり Deferred.next() なりを使って、 deferred.call() を呼ぶ処理を「次のジョブを登録する処理」よりも後(=次のイベントループ)に実行する必要がある。そうすれば、
function statDeferred(filePath) {
// (2) 関数の中に入った。
var deferred = new Deferred();
Deferred.next(function() {
// (7) 次のイベントループで、予約されたこの処理が始まる。
try {
var stats = fs.statSync(filePath);
deferred.call(stats); // (8) 登録済みの「次のジョブ」を連鎖的に呼ぶ。
} catch(error) {
deferred.fail(error);
}
}); // (3) 次のイベントループで実行するように予約。
return deferred; // (4) 関数を抜けた。
}
// (1) 今のイベントループでのスタート地点。
statDeferred('/tmp/foobar')
.next(function(stats) {
// (9) 「次のジョブ」として、この処理が始まる。
if (stats.isDirectory()) {
...
}
}); // (5) 戻り値の next() を呼んで、次のジョブを登録した。
// (6) 今のイベントループの終わり。
……という順番で処理が進むから、期待通りに動くようになる。
どの処理が一体何をしているのか、どの関数が何を返しているのか、自分が呼んでいるメソッドは誰のメソッドなのか、といった事をちゃんと理解しておくと、この話がすっと頭に入ってくると思うんだけど、ただの構文として覚えてしまっていると、メールの送り主の人みたいに「何で動かないの……」って詰まってしまうんだと思う。
という風に偉そうな事を言ってるけど、僕自身も最初は多分ただの構文として覚えてた方で、ただ、「同期処理の時は setTimeout() なり Deferred.next() なりを使って deferred.call() を呼ぶ」という所までを「構文」として暗記していたから、結果的にはちゃんと動いてくれてたという状態だったんだと思う。その後若手IT勉強会の中でコードリーディングをやってだんだん仕組みが分かってきて、「ああなるほど、こういうことだったんだ」と理解できるようになった。
Firefox Hacks Rebootedでもいっぱい書いたけど、JSDeferredの本質は、「あらゆる処理について、その次にやらせたい仕事を next() のコールバック関数という形で後から登録できるようにする」ものだ、と僕は認識してる。「後から登録する」という都合上、この性質は非同期処理(関数を抜けた時点でまだ処理が始まっていないという種類の処理)と非常に相性がいい。けれども、非同期処理じゃないと使えないわけではない。ただ、「後から登録する」というのは、普通に順番通りに進む同期的な処理の中では行えないイレギュラーな事だから、 setTimeout() や Deferred.next() を使わざるを得なくて、それで初見の人に分かりにくくなってしまう。そこがもどかしい所だ。
The priority policy of my addon projects - May 10, 2012
In recent days, I discussed on the issue about scrolling of the vertical tab bar. It made the priority policy about my addon projects clear, again. So, let's sum up them.
- I assign the highest priority to issues I actually annoyed. Most projects were started because I wanted to use such addons. This is the main motivation to continue developing for me. In other words, when I suffer from a bug in my daily use, I'll fix it prior to other bugs, even if the mine is just trivial and the yours is very serious. After that, if I have time good enough, I'll research and fix your issues. If I've never used the feature (and I never use it in the future), then there is extremely low feasibility rating.
- I'm negative about adding new features (especially digressive features) to existing addons. Because I currently have no plan to switch to other browsers (Google Chrome, etc.), I want to keep codes easy to follow up to future releases of Firefox. Even if the new feature looks simple, it can cost much time for maintenance in the future chronically. Long term sustainability is prior to short term convenience, for my projects. I'll reject requests which can lose maintainability or independency of the project, even if it is very useful feature, fixing serious bug, and so on.
- I think that any addon shouldn't break features of Firefox itself without any apparent reason. For example, because the tab bar is automatically hidden in the full-screen mode (F11 key) by default, the vertical tab bar also should be done. If my addon breaks Firefox's default behavior unexpectedly, then I'll make effort on fixing it. However, if the issue is not introduced by my addon, then I often step back from it.
Because currently I have less time to develop addons, I have to apply these policies strictly. Actually, in recent days, I spend just a few days of my time per a month for my private development. Sadly I have to keep many requests pending.
However, codes of my addons are licensed under open source licenses. For example, Tree Style Tab is licensed under GPL/LGPL/MPL. You can fork, develop, or re-distribute any project based on my codes, by your hand. Your version can be better alternative for people who suffered from the issue ignored by me. (And, if it is enough reasonable, I possibly merge your changes to my repository.)