Mar 30, 2019
ツリー型タブ バージョン3.0への道
これはただの苦労話です。
2月末から3月末までをかけて、長らく懸案事項となっていたツリー型タブ(Tree Style Tab、TST)の大規模改修をやりました。具体的な変更の量としては、改修に取りかかる前の2.7.22からの差分 git diff 2.7.22 で約1MBありました。見た目は変えなかったのであまり代わり映えしませんし、挙動を決定づけるロジックもほぼそのままなのですが、それらが乗っかる基盤にあたる部分が入れ替わった感じです。
何を改修したのか、どういう成果があったのか、という事を説明するために、TSTのこれまでの歴史を振り返ってみます。WebExtensionsに移行した時の話ではあまり触れなかった、細かい実装の話が多めですが、誰の役に立つかは分かりません。
「いや、これでも昔はまともな設計をしてたんですよ?」
TSTのご先祖様にあたる古代のアドオン「Tabbrowser Extensions(TBE)」では、XBLによるカスタムバインディングをフル活用していました。
- 子タブや親タブといった情報は、各タブの
tab.childTabsやtab.parentTabなどのプロパティで参照できる。 - タブのツリー構造の編集は、各タブの
tab.attachTo()やtab.detach()などのメソッドで行う。
といった要領でわりかし普通にオブジェクト指向の設計になっていたので、その時点だけを見ればまあそんな変な作りではなかったんじゃないかなと思います。
が、問題は、Firefoxの(XULベースの)アドオンというものが本質的にFirefox本体のコードに動的に適用されるパッチのような物で、しかも前述のような変更をほとんどXBLでやっていた、という所にありました。分かりやすく言うと「Firefoxの起動時に割り込んで、Firefoxのタブを実装しているクラスを同名のクラスでオーバーライドし、他のモジュールから呼ばれる『タブを開く』とか『タブを閉じる』とかのメソッドもゴッソリ入れ換えて、ツリー的な挙動を実現するのに必要な機能をオンメモリで付け足していた」という感じでしょうか。
Firefoxの他の部分ともシームレスな統合を実現していた、と言えば聞こえがいいのですが、要するにその時点のFirefoxのコードにべったり密結合していたという事です。なのでFirefox本体の更新に追従しきれなくなり、TBEはFirefox 1.5と共に消え去りました。
「まともにやってたら駄目だったので、泥臭い設計に切り替えたんですよ……」
「密結合にするとFirefoxの更新についていけなくなる」という事を学んだ僕は、Firefox 2以降向けに新たにTST(レガシー版・XUL版のTST。バージョン0.1.2007102102~0.19.2017090601)を開発し直すにあたって、以下のように設計の方針を転換することにしました。
- XBLへの依存を可能な限り廃する。
- 「
getChildTabs()という関数で子タブの一覧を得る」「attachTabTo()という関数に親タブと子タブを渡して、互いを関連付ける」といった要領の、手続き型の設計を基本とする。 - タブのツリー構造はXULのtab要素に属性として保持し、さらにFirefox本体のセッションマネージャを使って、それらと同じ情報をタブのセッション情報の一部として永続化する。
- 処理対象のタブの検索は、XULのDOMツリーに対してDOM3 XPathや
document.querySelectorAll()などで行う。
タブのツリー構造の情報を属性で保持するようにしたのには、処理を高速化したかったからという理由もありました。当時はまだSpiderMonkeyにJITが導入されておらず(※SpideMonkeyの最初のJITであるTraceMonkeyはFirefox 3.5で実戦投入されました)、JavaScriptのループ処理はとにかく遅いという定説があったので、僕は可能な限りJSのループを避けたいと考えていました。そのため、DOM3 XPathやdocument.querySelectorAll()などのDOMの機能でタブを見つけやすいように、XPath式やCSSセレクタで参照できる形でツリー構造を保持することにしたのでした。
この設計は簡潔さ・美しさからはほど遠い物でしたが、Firefox本体との結合箇所を最小限に抑えたのが功を奏したためか、Firefox 56に至るまで小改修の繰り返しでどうにか追従し続ける事ができていました。
「まともに作り直すの大変だから、仕方なく、泥臭い設計の物を持ち越したんですよね」
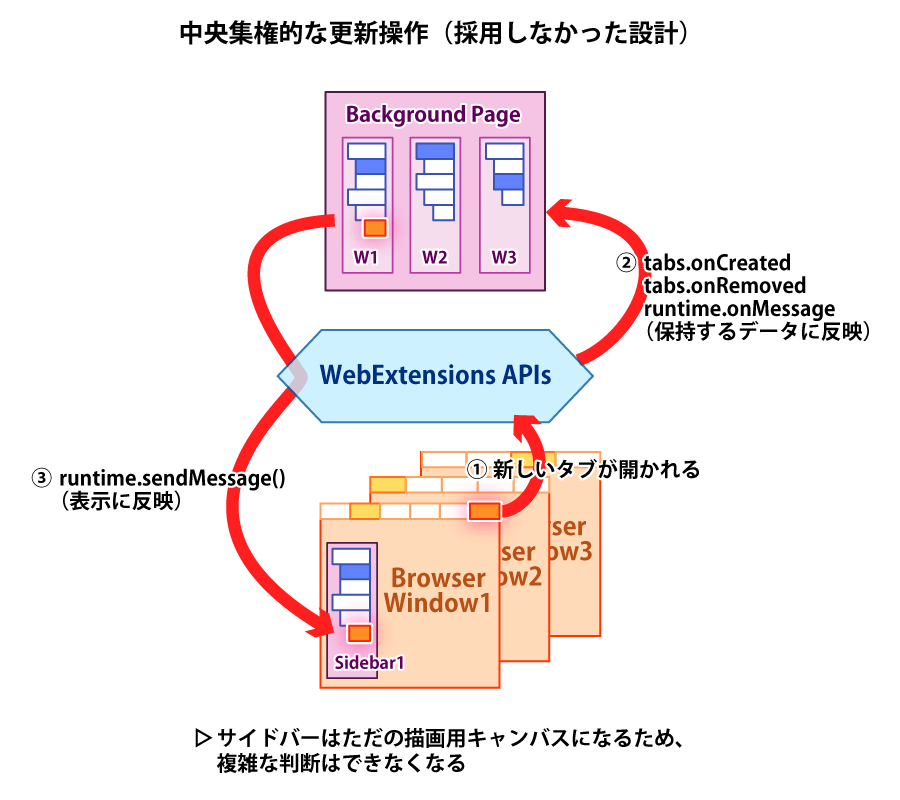
Firefox 57でのWebExtensionsへの移行にあたっては、WebExtensionsのAPIベースでTSTを作り直す必要がありました。しかし実際の所、WebExtensions APIへの慣熟度がそれほど高くなく、また解説漫画の連載を並行して行っていた自分には、「技術基盤を変えて」「設計も変える」「その上で以前と変わらない使い勝手を実現する」というのは現実的に到底不可能に思えました。そこで、TST 2.0では技術基盤は(XULからWebExtensions APIへ)変えつつも、設計そのものはほぼ以前の物を引き継ぐという方向性で、
- 手続き型の設計。
- マスターデータはDOMツリーで保持。
- DOMツリーに対して、DOM3 XPathや
document.querySelectorAll()でタブを検索。
という基本設計をそのまま引き継いだ上で、
- サイドバー内だけでは処理を完結できないため、バックグラウンドページというマスタープロセスを新たに用意する。
- ただしマスタープロセスをスクラッチで書き起こす余力は無いため、実装を「マスタープロセスとサイドバーの両方で使う共通実装」「マスタープロセスだけの実装」「サイドバーだけの実装」の3つのモジュール群に分けて、マスタープロセスとサイドバーとで可能な限りコードを共有するようにする。
- マスタープロセスとサイドバーの双方が半自律的に動作し、必要最小限の情報だけをメッセージで交換して、お互いの状態を細かく同期し合うようにする。
という感じの仕組みを作って、TST 2.xをなんとか動く物に仕上げたのでした。
しかしながら、元々WebExtensionsのAPI群が非同期である事に加えて、「マスタープロセス」と「サイドバー」という2つの異なる部分が互いに半自律的に動作しているために、ツリー構造やタブの並び順などを一貫させるためには複数の非同期処理を細かく待ち合わせる必要がありました。そのため、
- 大量のタブがあると滅茶苦茶遅い。
- タブを素早く開いたり移動したりすると、マスタープロセスとサイドバーの処理タイミングのずれのせいで、双方の同期が崩れる。
- 安定性を高めればオーバーヘッドが増え、速度を優先すれば安定性が犠牲になる。
という根の深い問題を抱え込む結果となってしまいました。
一応、その後の更新の中で「遅いDOM3 XPathやdocument.querySelectorAll()の使用頻度を減らす(※この頃にはもうSpiderMonkeyのJITもこなれてきていて、DOMを触る方が却って遅いという風に状況が逆転していた)」「非同期処理の流れを制御して可能な限り同期を取る」といった改善は繰り返し行ってきましたが、3000だの6000だのといった異常に大量のタブがあるケースの前では焼け石に水で、もうこれ以上どうしようもないという状況でした。
とはいえ、自分自身が使う上ではこの状態でもそれほど大きな問題は起こっておらず、タブを数千個開くというような人も希なようでしたので、何もなければこのまま細かくメンテナンスしていくだけかなあ、と2018年の秋くらいまでは考えていました。
しかし、Firefox 64からのタブの複数選択機能に対応したあたりで状況が変わってきました。それまで潜在していた並行して走る複数の非同期処理の結果が安定しないという問題が、それによって顕在化したからです。
「みんな気付いてなかったみたいなんだけど、ずっと前から実はバグってたんですよ」
TST 2.xでは当初から度々、「開いた子タブの並び順が一定しない」とか「移動したタブが変な所に表示される」といった問題が報告されていました。これは、タブを開く(=Firefoxのタブが開かれたことを検知して、それに対応するタブの要素を画面上に配置する)処理が非同期で進行する事と、マスタープロセスとサイドバーのそれぞれが独自に・自律的にタブの変更を監視している事とが原因になっているようです。今に至るまで状況を正確に調べきれてはいないのですが、現時点での自分の認識としては、複数のタブを一度にまとめて開くような場面において、
- あるタブの挿入位置を計算した後で、既に挿入処理が進行されていた別のタブが挿入され、結果的に、計算した挿入位置が不自然な物になる。
- マスタープロセス側ではタブの挿入位置を制御するために処理待ちを何度か挟んでいるのに対し、サイドバー側では最低限の計算だけで済ませているために、挿入位置の計算結果や実際にタブの要素がDOMツリーに挿入されるタイミングにずれが生じる。
といった事が複数・並行して発生し、互いの結果が複雑に絡み合ってカオス状態になるために、「マスタープロセス側で把握したタブの並び順」「サイドバー上に表示されるタブの並び順」「Firefoxのタブバー上のタブの並び順」の同期が崩れてシッチャカメッチャカになってしまっている、という事ではないかと考えています。
それでも、Ctrl-Tabでのタブ切り替え(これは完全にFirefoxx側で制御されており、Firefoxのタブバー上でのタブの並び順に基づいて動作する)や、タブのドラッグ&ドロップでの並べ替えなどを行わない限りは、問題が起こっている事に気付かずに使っていた人は多かったのだと思われます。というか、他ならぬ自分自身もそのひとりでした。
「バグがね……見えるようになっちゃったんすわ……」
ところで、Firefox 64で導入されたタブの複数選択APIは、タブを選択する場面だけでなく、タブのフォーカス切り替えにも使われ得ます。他のタブの複数選択の状態を壊さないで、アクティブなタブだけ切り替えるという事(Shift-クリックで複数のタブを選択した後に、選択状態にあるタブ群の中でアクティブでないタブをドラッグしようとしたら、そのタブがアクティブに切り替わる、という挙動を再現する時なんかにこれが必要になります)を考慮に入れると、タブのフォーカス切り替えにはbrowser.tabs.update()ではなくbrowser.tabs.highlight()の方をどうしても使わなくてはなりません。
厄介な事に、このメソッドは選択する対象のタブをidではなくindexで指定する必要があります。そのため、サイドバーに表示されているタブの並び順とFirefoxのタブの並び順の同期が崩れていると、クリックされたタブとは別のタブがフォーカスされてしまうという現象が起こってしまいます。
タブのフォーカスを切り替えるためにタブをクリックするという操作は、Ctrl-Tabでのフォーカス切り替えやドラッグ&ドロップでの並べ替えに比べると圧倒的に多くの人が日常的に行う操作です。そういうわけで、Firefox 64以後この件の障害報告が頻繁に寄せられるようになりました。
TST 2.7.0ではこの問題の暫定的な回避策として、タブの並べ替えや配置が行われたら、マスタープロセスが把握しているタブの並び順を基準として、Firefoxのタブとサイドバー上のタブの並び順を強制的に同期するという事をやるようにしました。この対策はある程度の効果を挙げたと思っているのですが、問題が頻発している人の環境では依然として起こり続けているようです。
「諦めてたんだけど、意外といけそうな気がしてきましてん」
問題の完全な解決には至らなかった一方で、TST 2.7.0で導入したタブの並び順の強制同期処理は、僕の中に一つの気付きをもたらしました。「あれ? マスタープロセスで全部管理する設計に切り替えるなんて無理だって思ってたけど、案外いけるんじゃね?」と。
素人考えでは、「マスタープロセス側で把握しているタブの並び順に他の物を揃える」というのはかなり大変な事のように思えます。やり方がまずければ、特に数千個ものタブがあるような場面では、同期のための処理が走る度にFirefoxがフリーズするなんて事にもなりかねません。
その解決策のヒントになったのが、数年前から度々噂に聞く仮想DOMの考え方でした。詳しい事はリンク先に書いてありますが、要点は現在の状態から期待される状態へ、なるべく少ない変更で持っていく手順をまず計算し、それに従って変更を適用するという事です。
実を言うと、僕はこのあたりの話にちょっと覚えがありました。僕は会社の業務の一環で何年も前にUnitTest.XUL、略してUxUというテスティングフレームワーク的なFirefox/Thunderbird用アドオンを開発していたのですが、その中に、アサーションの期待値と実測値の差分を表示するという機能があり、これがまさにその「最短の変更手順を求める」実装だったのです。UxUでは当初はgit diffなどでよく見かける行単位の差分表示のみ対応していたのですが、TortoiseSVGやTortoiseGitではもっとカラフルに、且つ行内の単語レベルで差分を強調表示してくれるという事を知っていた僕は、同じ事をやりたくて差分を求める実装の中を覗いてみたのでした。で、この実装はうちの社長の須藤さんがPythonからJavaScriptに移植してUxUに組み込んだ物だったのですが、よくよく読んでみると、内部的にはこの実装でも1文字単位で差分を検出できていて、それを出力する時に行単位でまとめているのだという事が分かりました。そこで、あれこれ手を入れてTortoiseGitのようなカラフルな差分を出力できるようにしたのでした。この時のdiffの実装を援用すれば、TSTで期待するタブの並び順とその時点の実際の並び順を比較し、最小の回数でタブを並べ替えるという事もできるはずだ、と思い至ったのです。
それを実際にやってみたのがTST 2.7.0以降でのタブの強制同期処理だった(この辺の事については、別途詳しい解説を会社のブログに書いてます)のですが、部分的にとはいえ仮想DOMのコンセプトに似た事をTSTにも取り入れられて、しかも思っていたより全然速かったという事実が、僕に「この調子でやれば、基本的に全部マスタープロセス側で管理して、必要な変更をサイドバーに随時反映する、という設計に切り替える事もできるはず」という自信を付けさせてくれました。
(とはいえ、最終的にリリースに至ったTST 3.0では結局仮想DOMそのものは導入せずじまいになっているわけですが……)
「一気にやると死ぬんで、ちょっとずつやってく」
すべてぶっ壊してクリーンな設計で作り直す、というのが手っ取り早いのは間違い無いのですが、TST 2.0への移行時と同様に、「設計を変えて」「実装も変えて」「その上で以前と変わらない使い勝手を実現する」というのを一気にやると絶対に途中で収拾が付かなくなる自信が僕にはありました。なので、まず作業をいくつかの段階に分けて考えて、少しずつ進めていく事にしました。
- 全体的に、タブの情報を保持するマスターを、DOMツリー上のDOM要素から、JavaScriptの通常のオブジェクトに切り替える。(TST 2.8.0で投入)
- 各モジュールを、DOMツリーに直接触らないように無害化する。(TST 2.8.0で投入)
- マスタープロセスのタブのキャッシュを、DOMベースからJSONベースに切り替える。(TST 2.8.0で投入)
- サイドバー側においてWebExtensions APIでFirefoxのタブの変更を監視するのをやめ、WebExtensions APIのイベントの監視はマスタープロセス側だけに一本化する。その上で、情報が常に マスタープロセス→サイドバー の方向で流れていくように整理する。(TST 2.8.1以降で少しずつ投入し、TST 3.0で全面投入)
- サイドバーのタブの要素を、JavaScriptのオブジェクトから適宜生成・変更を反映して組み立てるようにする。(TST 2.8.0から少しずつ投入)
1~3は、コードの量としては大きな変更でしたが、作業自体は単純でした。例えて言うなら、「Rubyで書かれたプロダクトをJavaScriptにべた書きで移植する」みたいな話です。tabElement.getAttribute('parent')という要領でDOM要素の属性から情報を得ていた部分を、tabElement.tabObject.parentIdのようにDOM要素にくっつけたオブジェクト経由で取得・設定するように書き換えて、さらに、不要になった端からDOM要素を参照する部分を取り除いてtabObject.parentIdにする……という感じで、TSTの機能とDOMの癒着を少しずつ剥がすように、モジュール単位でちょっとずつ進めていきました。ちゃんとやればノーリスクで完遂できる事が目に見えていたので、ここはサクサク進められて、完遂時点で成果を一旦TST 2.8.0としてリリースする事にしました。
4から先は結構リスクのある変更になるという事をなんとなく感じていたので、一旦ここで足を止め、TST 2.8.0から2.8.7までの間はその時点でできる最適化を進める事にしました。
まず、3までの変更によって、タブの検索処理からはdocument.querySelector()やDOM3 XPathが全廃され、純粋なJavaScriptのループだけで完結するようになりました。そこで、条件ごとのタブの検索処理の実行回数や頻度を集計してみた所、自分では予想していなかったボトルネックが意外とたくさんあるという事が見えてきましたので、頻出する検索条件については「この条件にマッチするタブの一覧」という物を適宜保持しておくようにしていきました。(このあたりの発想は、ガチの検索エンジンであるGroonga案件で得た最適化の知見が活かされたと自分では思っています。)
また、タブのマスターデータをJSONのオブジェクトとして表現するようになったため、マスタープロセスからサイドバーへとタブのマスターデータそのものを丸ごと送りつけたり、DOMツリーをDocumentFragmentで組み立てて最後に一気にドキュメントに反映したりという事もできるようになりました。この事を活かした結果、起動直後の初期化やサイドバーの開閉時の再初期化は大幅に高速化できたと思っています。
マスタープロセスとサイドバーとの間の通信にも手を加えました。それまでは基本的にbrowser.runtime.sendMessage()でメッセージを送り合っていたのですが、簡単なベンチマークを取ってみた所、browser.runtime.connect()で作ったコネクションの方が4倍くらい高速だという事が分かりました。しかしbrowser.runtime.connect()で作ったコネクションには「メッセージの受け手が返したレスポンスを受け取れない」というデメリットがあります。そのため、TST 2.8.7ではレスポンスが必要ない一部のメッセージについてだけ、コネクションの方でメッセージを送るように先行して切り替えるという事もしてみました。
当初想定していなかった喜ばしい誤算として、回帰テストの自動化を再び図れるようになってきたというのも、自分としては大きな進歩でした。TSTはその性質上、Firefoxの実際のタブの振る舞いが動作に大きな影響を与えるため、Node.js上で再現されたWebExtensions APIのダミーでのユニットテストにはあまり意味は無いだろうという事を、当初からなんとなく考えていました。自動テストはそれ自体が目的になってしまってはいけなくて、不安を感じる所で不安を取り除くために書いておく物だ、とは確かt_wadaさん主催のテストの勉強会で教わった事だったように思います。その考え方を愚直に実践し、Firefox上で「テスト実行専用のタブ」の中でWebExtensions APIを呼んでユーザーの操作を再現しつつ、その結果として構築されたツリーの状態は適宜マスタープロセスに問い合わせて確認してアサーションする、というホワイトボックステストとブラックボックステストの中間のような極小のテスティングフレームワークを実装して、以降は直した後退バグをその都度回帰テストに追加するようにしています。現時点でまだテストの件数は10個あるかないかといったレベルですが、TST 3.0.1や3.0.2の修正の一部はこれらのテストで見つけられた物だったので(そもそも回帰テストが完遂しない状態でリリースするなよって話ですが……)、この効果は今後少しずつ顕れていくんじゃないでしょうか。
という感じでちまちま最適化しつつ、たまたま仕事がヒマだったタイミングがあったのでその時に本腰を入れて取り組んだ結果、4のアーキテクチャ変更をどうにか完遂できました。現在の設計を大まかに図にすると、Firefoxのタブの監視からサイドバーへの反映までの流れについて、主要モジュールの関係は
![]() のような感じで、その逆の、ユーザーがサイドバー上で行った操作がFirefoxに反映されるまでの流れは
のような感じで、その逆の、ユーザーがサイドバー上で行った操作がFirefoxに反映されるまでの流れは
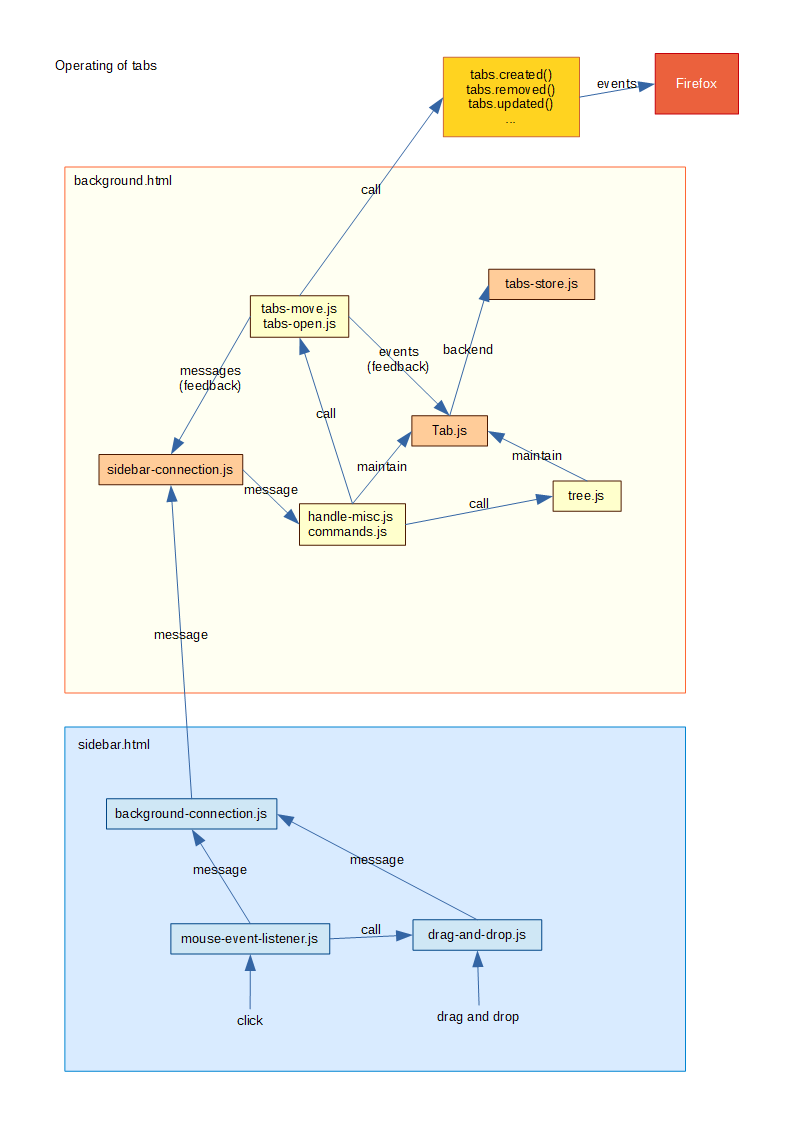 のような感じになっています。WebExtensions移行時に検討した中央集権的な設計を、3.0でやっと素直に実装したわけです。ずいぶん遠回りしました。
のような感じになっています。WebExtensions移行時に検討した中央集権的な設計を、3.0でやっと素直に実装したわけです。ずいぶん遠回りしました。
{kind=link}
マスタープロセス→サイドバー という流れを徹底するように、ユーザーの操作についても原則としてマスタープロセス側に処理を任せる(サイドバー内だけで終わらせない)ように改めたことで、非同期処理のカオスはだいぶ軽減されたのではないかと思っています。マスタープロセス上での複数の非同期処理のかち合いについてはまだまだ心配がありますが、マスタープロセスとサイドバーの間のズレを気にしなくてもよくなったので、今後はそちらの安定化にも力を入れて行きやすくなったんじゃないでしょうか。
当初やろうと思っていた「仮想DOM化」については、現時点でその本質に相当する事はそこそこ取り入れられてるんじゃないかなと思ったので、特に既存の有名ライブラリを導入するという事はせずじまいです。でも、そうしないとやっぱりパフォーマンスが上がらないなという事を痛感したら、TST 3.1とかそういう段階の取り組みとして導入していくかもいれないなとは思っています。
「リリースしたつもり無かったんですけど」
という事で、もうちょっとドッグフーディングしてから正式にTST 3.0をリリースしようかなと思ってたんですが、Mozilla Add-onsにちょっとアップロードしてみて「やっぱやめ」と思って工程をストップしたつもりだった物が一夜明けたらバージョン3.0として世に出てしまっていて、バグ報告まで寄せられ始めていたので、慌てて3.0.1、3.0.2をリリースしたというのが3月29日の事でした。どうも、自動テストの所で雑にinnerHTMLを使っていた部分が原因で「このファイルは目視レビューが必要」と判定されて、それでEditorの人が目視してレビュー通過のフラグを立てた結果、止めたつもりだった公開プロセスが先に進んでしまって、気付かないうちに公開されてしまっていた、という事なんじゃないかという気がします。
自分としては、前より状況が悪くなったという事はあんまり無いんじゃないかと思ってるんですが、Webの反応を見てみると、3.0でメモリを食うようになったとか遅くなったとかのケースもあるようです。以前は非同期でちょっとずつ進行していた物が、マスタープロセスへの処理の一本化によって可能な限りまとめて処理を進めるようになった結果、一気に大量のデータを処理しようとしてsaturationが起こってるという事なんじゃないだろうか?と予想していますが、今の所明確な再現条件が出てきているわけでもないようなので、静観の構えでおります。「こうしたら100%再現する」という手順を特定された方がもしいらっしゃいましたら、GitHubのイシュートラッカーへ、日本語でよいのでご報告を頂ければ幸いです。
wikieditish message: Ready to edit this entry.